Lucene.Net 2.3.1开发介绍 —— 二、分词(一)
原文:Lucene.Net 2.3.1开发介绍 —— 二、分词(一)
Lucene.Net中,分词是核心库之一,当然,也可以将它独立出来。目前Lucene.Net的分词库很不完善,实际应用价值不高。唯一能用在实际场合的StandardAnalyzer类,效果也不是很好。内置在Lucene.Net里的分词都被放在项目的Analysis目录下,也就是Lucene.Net.Analysis命名空间下。分词类的命名一般都是以“Analyzer”结束,比如StandardAnalyzer,StopAnalyzer,SimpleAnalyzer等。全部继承自Analyzer类。而它们一般各有一个辅助类,一般以”“Tokenizer”结尾,分词的逻辑大都在辅助类完成。
使用Lucene.Net,要很好地使用Lucene.Net,必须理解分词,甚至能自己扩展分词。如果只使用拉丁语系,那么使用内置的分词可能足够了,但是对于中文肯定是不行的。目前中文方面的分词分为单字分词,二元分词,词库匹配,语义理解这几种。StandardAnalyzer类就是按单字分,二元分就是把两个字作为一组拆分,而词库的话肯定是有一个复杂的对比过程,语义理解的就更加复杂了。这是分词的方式,而匹配的方式也分为正向和逆向两种,一般逆向要优于正向,但是写起来也要复杂一些。
1、内置分词器
本节将详细介绍Lucene.Net内置分词的效果,工作过程,及整体结构。
1.1、分词效果
1.1.1 如果得到分词效果
如果得到分词效果?有效的方式就是进行测试。这里将引入自动测试的方法,这样更加便于测试,将使用NUnit来完成。Nunit的简单实用方法见附录二。
创建一个新的项目,命名为Test。步骤如图 1.1.1.1 - 1.1.1.2
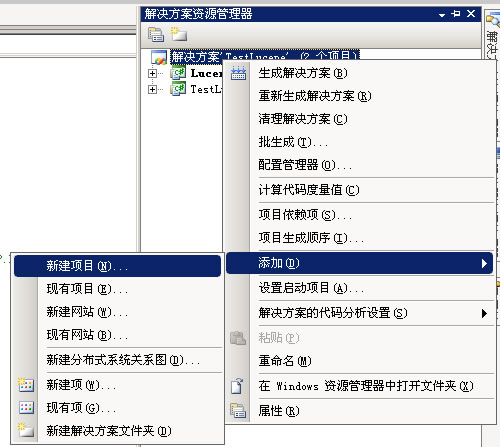
图1.1.1.1
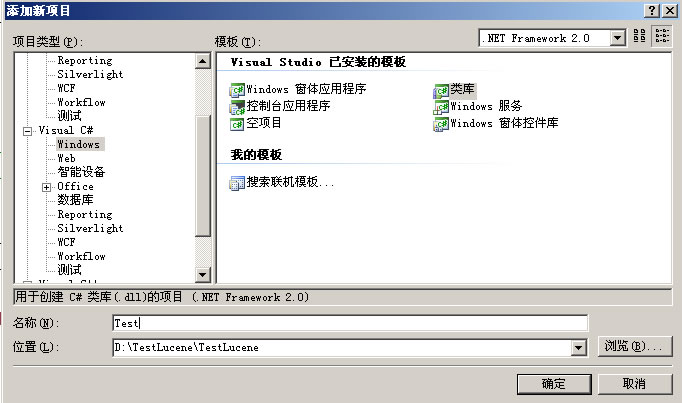
图 1.1.1.2
点确定,就加入了新项目Test,选择类库模板。再引用Nunit.framework类库。如图 1.1.1.3。
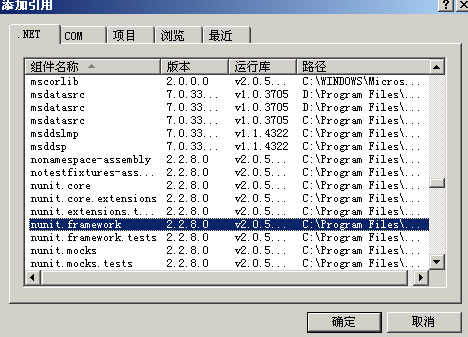
图 1.1.1.3
再按第一章节的步骤引入Lucene.Net类库。先来试试SimpleAnalyzer类的效果。在Test项目中添加SimpleAnalyzerTest,代码 1.1.1.1。
代码 1.1.1.1
Code 1using System; 2using System.Collections.Generic; 3using System.Text; 4using NUnit.Framework; 5using Lucene.Net.Analysis; 6using System.IO; 7namespace Test 8{ 9 [TestFixture]10 public class SimpleAnalyzerTest11 {12 [Test]13 public void ReusableTokenStreamTest()14 {15 string testwords = "我是中国人,I can speak chinese!";1617 SimpleAnalyzer simple = new SimpleAnalyzer();18 TokenStream ts = simple.ReusableTokenStream("", new StringReader(testwords));19 Token token;20 while ((token = ts.Next()) != null)21 {22 Console.WriteLine(token.TermText());23 }24 ts.Close();25 }26 }27}28
运行结果:
我是中国人
i
can
speak
chinese
查看这个结果,基本可以确定,SimpleAnalyzer分词就是以空格或符号为断点,把句子分析出来。对于英文大写还会执行一个转换到小写的操作。
1.1.2 内置分词的分词效果
按照1.1.1节介绍的方式,就可以分析分析效果了。不过这样写出来的测试代码过于麻烦,改造一下。
(1)、在Test项目中新建Analysis目录;
(2)、在Analysis下建立TestData类,代码1.1.2.1;
代码1.1.2.1
Code 1using System; 2using System.Collections.Generic; 3using System.Text; 4 5namespace Test.Analysis 6{ 7 public class TestData 8 { 9 public static string TestWords = "我是中国人,I can speak chinese!";10 }11}12
(3)、建立TestFactory类,代码1.1.2.2
代码1.1.2.2
Code 1using System; 2using System.Collections.Generic; 3using System.Text; 4using Lucene.Net.Analysis; 5using System.IO; 6 7namespace Test.Analysis 8{ 9 public class TestFactory10 {11 public static void TestFunc(Analyzer analyzer)12 {13 TokenStream ts = analyzer.ReusableTokenStream("", new StringReader(TestData.TestWords));14 Token token;15 while ((token = ts.Next()) != null)16 {17 Console.WriteLine(token.TermText());18 }19 ts.Close();20 }21 }22}
(4)、建立AllAnalysisTest类,代码1.1.2.3
代码1.1.2.3
Code 1using System; 2using System.Collections.Generic; 3using System.Text; 4using NUnit.Framework; 5using Lucene.Net.Analysis; 6using Lucene.Net.Analysis.Standard; 7namespace Test.Analysis 8{ 9 [TestFixture]10 public class AllAnalysisTest11 {12 [Test]13 public void TestMethod()14 {15 List<Analyzer> analysis = new List<Analyzer>() { 16 new KeywordAnalyzer(),17 new SimpleAnalyzer(),18 new StandardAnalyzer(),19 new StopAnalyzer(),20 new WhitespaceAnalyzer() };2122 for (int i = 0; i < analysis.Count; i++)23 {24 Console.WriteLine(analysis[i].ToString() + "结果:");25 Console.WriteLine("--------------------------------");26 TestFactory.TestFunc(analysis[i]);27 Console.WriteLine("--------------------------------");28 }29 }30 }31}32
(5)、运行。
对于TestWords = "我是中国人,I can speak chinese!";测试结果:
Lucene.Net.Analysis.KeywordAnalyzer结果:
--------------------------------
我是中国人,I can speak chinese!
--------------------------------
Lucene.Net.Analysis.SimpleAnalyzer结果:
--------------------------------
我是中国人
i
can
speak
chinese
--------------------------------
Lucene.Net.Analysis.Standard.StandardAnalyzer结果:
--------------------------------
我
是
中
国
人
i
can
speak
chinese
--------------------------------
Lucene.Net.Analysis.StopAnalyzer结果:
--------------------------------
我是中国人
i
can
speak
chinese
--------------------------------
Lucene.Net.Analysis.WhitespaceAnalyzer结果:
--------------------------------
我是中国人,I
can
speak
chinese!
--------------------------------
换一句话试试:更改TestData类TestWords字段值为“我是中国人,I'can speak chinese,hello world,沪江小Q!”。测试结果:
Lucene.Net.Analysis.KeywordAnalyzer结果:
--------------------------------
我是中国人,I'can speak chinese,hello world,沪江小Q!
--------------------------------
Lucene.Net.Analysis.SimpleAnalyzer结果:
--------------------------------
我是中国人
i
can
speak
chinese
hello
world
沪江小q
--------------------------------
Lucene.Net.Analysis.Standard.StandardAnalyzer结果:
--------------------------------
我
是
中
国
人
i'can
speak
chinese
沪
江
小
q
--------------------------------
Lucene.Net.Analysis.StopAnalyzer结果:
--------------------------------
我是中国人
i
can
speak
chinese
hello
world
沪江小q
--------------------------------
Lucene.Net.Analysis.WhitespaceAnalyzer结果:
--------------------------------
我是中国人,I'can
speak
chinese,hello
world,沪江小Q!
--------------------------------
对于这几种分词效果基本可以看出来了。
KeywordAnalyzer分词,没有任何变化;
SimpleAnalyzer对中文效果太差;
StandardAnalyzer对中文单字拆分;
StopAnalyzer和SimpleAnalyzer差不多;
WhitespaceAnalyzer只按空格划分。
当然,这只是个粗略的结果。
Lucene.Net 2.3.1开发介绍 —— 二、分词(一)的更多相关文章
- Lucene.Net 2.3.1开发介绍 —— 二、分词(六)
原文:Lucene.Net 2.3.1开发介绍 -- 二.分词(六) Lucene.Net的上一个版本是2.1,而在2.3.1版本中才引入了Next(Token)方法重载,而ReusableStrin ...
- Lucene.Net 2.3.1开发介绍 —— 二、分词(五)
原文:Lucene.Net 2.3.1开发介绍 -- 二.分词(五) 2.1.3 二元分词 上一节通过变换查询表达式满足了需求,但是在实际应用中,如果那样查询,会出现另外一个问题,因为,那样搜索,是只 ...
- Lucene.Net 2.3.1开发介绍 —— 二、分词(三)
原文:Lucene.Net 2.3.1开发介绍 -- 二.分词(三) 1.3 分词器结构 1.3.1 分词器整体结构 从1.2节的分析,终于做到了管中窥豹,现在在Lucene.Net项目中添加一个类关 ...
- Lucene.Net 2.3.1开发介绍 —— 二、分词(四)
原文:Lucene.Net 2.3.1开发介绍 -- 二.分词(四) 2.1.2 可以使用的内置分词 简单的分词方式并不能满足需求.前文说过Lucene.Net内置分词中StandardAnalyze ...
- Lucene.Net 2.3.1开发介绍 —— 二、分词(二)
原文:Lucene.Net 2.3.1开发介绍 -- 二.分词(二) 1.2.分词的过程 1.2.1.分词器工作的过程 内置的分词器效果都不好,那怎么办?只能自己写了!在写之前当然是要先看看内置的分词 ...
- Lucene.Net 2.3.1开发介绍 —— 四、搜索(二)
原文:Lucene.Net 2.3.1开发介绍 -- 四.搜索(二) 4.3 表达式用户搜索,只会输入一个或几个词,也可能是一句话.输入的语句是如何变成搜索条件的上一篇已经略有提及. 4.3.1 观察 ...
- Lucene.Net 2.3.1开发介绍 —— 三、索引(二)
原文:Lucene.Net 2.3.1开发介绍 -- 三.索引(二) 2.索引中用到的核心类 在Lucene.Net索引开发中,用到的类不多,这些类是索引过程的核心类.其中Analyzer是索引建立的 ...
- Lucene.Net 2.3.1开发介绍 —— 三、索引(四)
原文:Lucene.Net 2.3.1开发介绍 -- 三.索引(四) 4.索引对搜索排序的影响 搜索的时候,同一个搜索关键字和同一份索引,决定了一个结果,不但决定了结果的集合,也确定了结果的顺序.那个 ...
- Lucene.Net 2.3.1开发介绍 —— 四、搜索(三)
原文:Lucene.Net 2.3.1开发介绍 -- 四.搜索(三) Lucene有表达式就有运算符,而运算符使用起来确实很方便,但另外一个问题来了. 代码 4.3.4.1 Analyzer anal ...
随机推荐
- C#中结构与类的区别
一.类与结构的示例比较: 结构示例: public struct Person { string Name; int height; int weight public bool overWeight ...
- BZOJ 3011: [Usaco2012 Dec]Running Away From the Barn( dfs序 + 主席树 )
子树操作, dfs序即可.然后计算<=L就直接在可持久化线段树上查询 -------------------------------------------------------------- ...
- JNI 详细解释
JNI事实上,Java Native Interface缩写,那是,java本地接口.它提供了许多API实现和Java和其它语言的通信(主要是C&C++). 或许不少人认为Java已经足够强大 ...
- Swift UI开发初探
今天凌晨Apple刚刚发布了Swift编程语言,Swift是供iOS和OS X应用编程的新编程语言.相信很多开发者都在学习这门新语言. 废话不多说,下面我就来学习使用Swift创建一个简单的UI应用程 ...
- C# - 委托_求定积分通用方法
代码: using System; using System.Collections.Generic; using System.Linq; using System.Text; using Syst ...
- 在Web Api中快速实现JSonp
本文翻译自:http://www.codeproject.com/Tips/631685/JSONP-in-ASP-NET-Web-API-Quick-Get-Started Concept: 同源策 ...
- 利用Winscp,Putty实现Windows下编写Linux程序
本文讲的方案实现以下功能:利用winscp和putty的脚本功能,实现在Window平台上编写代码,上传到Linux进行编译,然后取编译结果.需要用到3个文件,分别如下: (1) synchroniz ...
- WCF技术剖析之十九:深度剖析消息编码(Encoding)实现(下篇)
原文:WCF技术剖析之十九:深度剖析消息编码(Encoding)实现(下篇) [爱心链接:拯救一个25岁身患急性白血病的女孩[内有苏州电视台经济频道<天天山海经>为此录制的节目视频(苏州话 ...
- Java获取随机数的几种方法
Java获取随机数的几种方法 .使用org.apache.commons.lang.RandomStringUtils.randomAlphanumeric()取数字字母随机10位; //取得一个3位 ...
- poj1830
高斯消元求秩,难在构造方程. ; ; i < equ; i++) { ; j < var + ; j++) { cout & ...