MongoDB Input
Configure Connection Tab
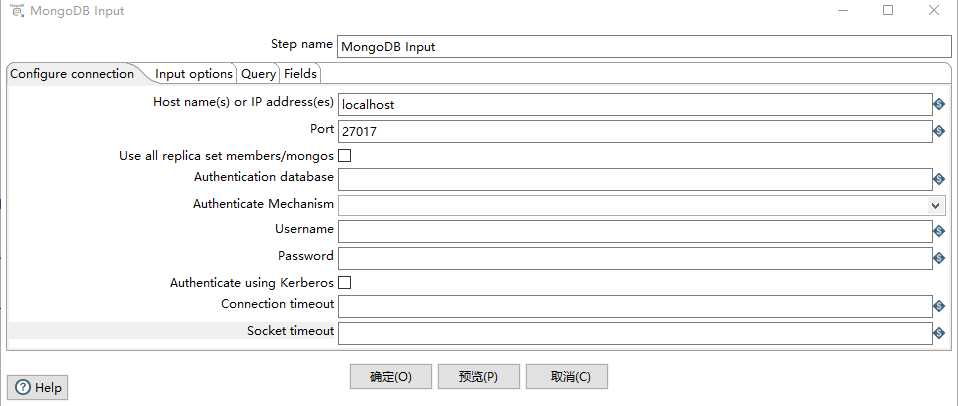
Host name(s) or IP address(es):网络名称或者地址。可以输入多个主机名或IP地址,用逗号分隔。还可以通过将主机名和端口号与冒号分隔开,为每个主机名指定不同的端口号,并将主机名和端口号的组合与逗号分隔开。例如,要为两个不同的MongoDB实例包含主机名和端口号,您将输入localhost 1:27017,localhost 2:27018,并使端口字段为空
Use all replica set members/mongos:
Port:端口号
Username:用户名
Password:密码
Authenticate using Kerberos:指示是否使用Kerberos服务来管理身份验证过程。
Connection timeout:连接超时时间(毫秒)
Socket timeout:等待写操作(以毫秒为单位)的时间
Input Options Tab
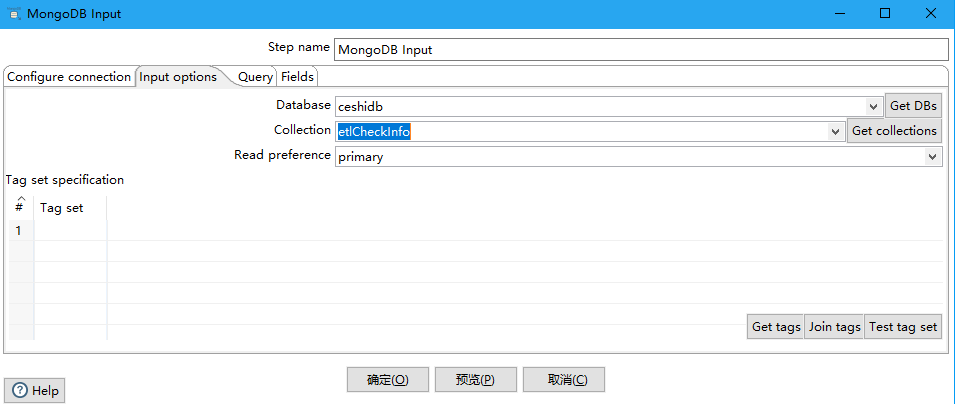
Database:检索数据的数据库的名称。单击Get DBs以在服务器上的数据库列表填充下拉菜单。
Collection:集合名称。点击 Get collections以在数据库中包含一个集合列表来填充下拉菜单
Read preference:表示要先读取哪个节点
Tag set specification/#/Tag Set:标签允许您自定义写关注和读取副本的首选项
Query Tab
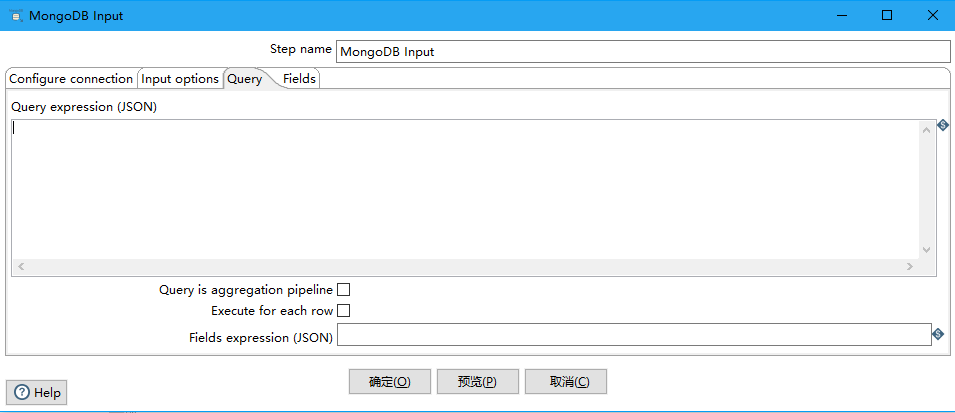
查询选项卡使您能够改进读请求。这个选项卡以两种不同的模式运行。您可以使用JSON查询表达式或使用聚合框架来创建查询。默认情况下,查询选项卡是JSON查询表达式模式。您可以输入一个JSON查询表达式。当选Query is aggregation pipeline 的时候,使用聚合表达式查询,是一种类似与json的查询语言。
Query expression (JSON):查询表达式(JSON)(Query is aggregation pipeline没被选择的情况下)
{ name : "MongoDB" } 或者{ name : { '$regex' : "m.*", '$options' : "i" } }
Query is aggregation pipeline:将多个JSON表达式连接在一起,立即执行。聚合管道将几个JSON表达式串在一起,前面的表达式的输出将成为下一个表达式的输入。
Aggregation pipeline specification (JSON):聚合管道规范(JSON)(Query is aggregation pipeline被选择)
{ $match : {state : "FL", city : "ORLANDO" } }, {$sort : {pop : -1 } }或者{ $group : { _id: "$state"} }, { $sort : { _id : 1 } }
Execute for each row:对每一行数据执行查询
Fields expression (JSON):Query is aggregation pipeline没被选中时候有效,控制字段返回
MongoDB Input的更多相关文章
- kettle之mongodb数据同步
需求: 1.源数据库新增一条记录,目标库同时新增一条记录: 2.源数据库修改一条记录,目标库同时修改该条记录: 示例用到三个Kettle组件 下面详细说下每个组件的配置 Source: 本示例连接的是 ...
- Scala spark mongodb
最好的参考是Mongo官网的地址 https://docs.mongodb.com/spark-connector/getting-started/ 需要截图所示的包 代码地址 https://git ...
- Spark连接MongoDB之Scala
MongoDB Connector for Spark Spark Connector Scala Guide spark-shell --jars "mongo-spark-connect ...
- MongoDB With Spark遇到的2个错误,不能初始化和sample重复的key
1.$sample stage could not find a non-duplicate document while using a random cursor 这个问题比较难解决,因为我用mo ...
- Scala2.11.8 spark2.3.1 mongodb connector 2.3.0
import java.sql.DriverManager import com.mongodb.spark._ import org.apache.spark.SparkConf import or ...
- spark读取mongodb数据写入hive表中
一 环境: spark-: hive-; scala-; hadoop--cdh-; jdk-1.8; mongodb-2.4.10; 二.数据情况: MongoDB数据格式{ "_i ...
- MongoDB + Spark: 完整的大数据解决方案
Spark介绍 按照官方的定义,Spark 是一个通用,快速,适用于大规模数据的处理引擎. 通用性:我们可以使用Spark SQL来执行常规分析, Spark Streaming 来流数据处理, 以及 ...
- pyspark mongodb yarn
from pyspark.sql import SparkSession my_spark = SparkSession \ .builder \ .appName("myApp" ...
- Mongodb——文档数据库
mongodb是一个文档数据库. mongo操作 多个修改操作,但每个修改携带的数据包较小,可操作考虑批量操作.bulkWrite()改善性能. MongoCollection是线程安全的. db.c ...
随机推荐
- org.apache.tomcat.util.descriptor.web.WebXml.setVersion Unknown version string [4.0]
错误: 在 IDEA 创建WEB项目之后,打印出的日志中总是出现一行警告信息: 12-May-2018 15:52:30.692 警告 [RMI TCP Connection(3)-127.0.0.1 ...
- Linux gdb调试及后台程序问题
https://blog.csdn.net/lengchanguo/article/details/50481533 转? 问题是后台& 调试
- 箭头函数与定时器的this指向问题
函数体内的this对象,就是定义时所在的对象,而不是使用时所在的对象. 箭头函数本身没有this,this继承上级的this. 定时器中箭头函数的this指向包含定时器的函数,所以定时器中的箭头函数要 ...
- tsung压力测试环境部署详细步骤(内附安装包)
操作系统: Redhat 6.3.Redhat6.5 .centos7.4(这些版本已验证过) tsung版本: tsung-1.6.0 下载地址: 链接: https://pan.baidu.com ...
- jquery 去除 css 的 background-image 样式
首先我使用了这个: $('#**').css('background-image', null); 没有效果...... 然后我用了这个: $('#staffName').css('backgroun ...
- redis.conf 文件解释
# Redis示例配置文件 # 注意单位问题:当需要设置内存大小的时候,可以使用类似1k.5GB.4M这样的常见格式: # # 1k => 1000 bytes # 1kb => 1024 ...
- Maven 配置问题 - could not find resource mybatis-config.xml
需要在pom中加入以下代码 <build> <resources> <resource> <directory>src/main/resources&l ...
- 宽字符(UNICODE)字符集
推荐使用宽字符(UNICODE)字符集,严格使用宽字符集的函数和定义.具体参考https://blog.csdn.net/qq_22642239/article/details/84822485
- 北京清北 综合强化班 Day1
a [问题描述]你是能看到第一题的 friends呢. —— hja何大爷对字符串十分有 ...
- 【csp模拟赛2】黑莲花--数据结构+数论
没有什么能够阻挡,你对被阿的向往.天天 AK 的生涯,你的心了无牵挂. 虐过大佬的比赛,也曾装弱装逼.当你低头的瞬间,才发现旁边的人. 把你的四肢抬起来,使劲地往门上撞.盛开着永不凋零,黑莲花. —— ...