step5: 编写spider爬取
改写parse函数
实现功能:
1.获取文章列表页中的文章url并交给scrapy下载后,交给解析函数进行具体字段的解析
2.获取下一页的url并交给scrapy进行下载,下载完成后交给parse
提取一页列表中的文章url
#解析列表页中所有文章的url,遍历出来
def parse(self, response):
# 解析列表页中的所有url并交给scrapy下载后进行解析
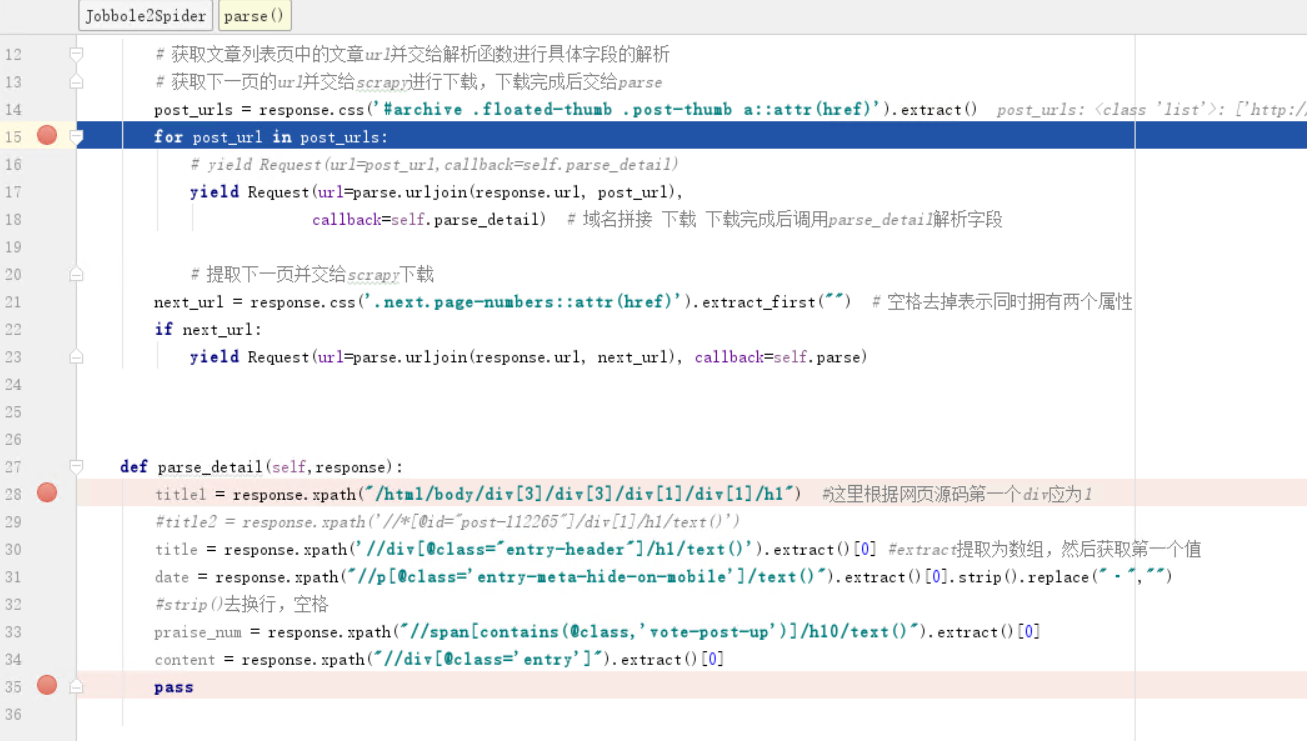
post_urls = response.css('#archive .floated-thumb .post-thumb a::attr(href)').extract()
for post_url in post_urls:
print(post_url)
调试输出结果

如何让scrapy进行下载
引入request对象
from scrapy.http import Request
修改提取字段类类名为parse_detail,引入parse类进行域名拼接,yield下载
from urllib import parse
def parse(self, response):
#获取文章列表页中的文章url并交给解析函数进行具体字段的解析
#获取下一页的url并交给scrapy进行下载,下载完成后交给parse
post_urls = response.css('#archive .floated-thumb .post-thumb a::attr(href)').extract()
for post_url in post_urls:
#yield Request(url=post_url,callback=self.parse_detail)
yield Request(url=parse.urljoin(response.url, post_url),callback=self.parse_detail) #域名拼接 下载 下载完成后调用parse_detail解析字段
获取下一页并交给scrapy进行下载
#提取下一页并交给scrapy下载
next_url = response.css('.next.page-numbers::attr(href)').extract_first("")#空格去掉表示同时拥有两个属性
if next_url:
yield Request(url=parse.urljoin(response.url, next_url), callback=self.parse) #继续调用parse解析出列表页中具体文章的url
调试前修改start_url为all-posts
调试结果
step5: 编写spider爬取的更多相关文章
- 第八篇 编写spider爬取jobbole的所有文章
通过scrapy的Request和parse,我们能很容易的爬取所有列表页的文章信息. PS:parse.urljoin(response.url,post_url)的方法有个好处,如果post_ur ...
- 兴奋与沮丧并存spider爬取拉勾网
兴奋的开发除了爬取拉勾网的爬虫信息,可是当调试都成功了的那一刻,我被拉钩封IP了. 下面是spider的主要内容 import reimport scrapy from bs4 import Beau ...
- 用java编写爬虫爬取电影
一.爬取前提1)本地安装了mysql数据库2)安装了idea或者eclipse等开发工具 二.爬取内容 电影名称.电影简介.电影图片.电影下载链接 三.爬取逻辑1)进入电影网列表页, 针对列表的htm ...
- 第4章 scrapy爬取知名技术文章网站(2)
4-8~9 编写spider爬取jobbole的所有文章 # -*- coding: utf-8 -*- import re import scrapy import datetime from sc ...
- 第十六节:Scrapy爬虫框架之项目创建spider文件数据爬取
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 其可以应用在数据挖掘,信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取所设计的, 也可以应用在获取API所返回的数据或 ...
- scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250
scrapy爬虫框架教程(二)-- 爬取豆瓣电影TOP250 前言 经过上一篇教程我们已经大致了解了Scrapy的基本情况,并写了一个简单的小demo.这次我会以爬取豆瓣电影TOP250为例进一步为大 ...
- Scrapy-redis实现分布式爬取的过程与原理
Scrapy是一个比较好用的Python爬虫框架,你只需要编写几个组件就可以实现网页数据的爬取.但是当我们要爬取的页面非常多的时候,单个主机的处理能力就不能满足我们的需求了(无论是处理速度还是网络请求 ...
- 爬虫入门之Scrapy框架基础框架结构及腾讯爬取(十)
Scrapy终端是一个交互终端,我们可以在未启动spider的情况下尝试及调试代码,也可以用来测试XPath或CSS表达式,查看他们的工作方式,方便我们爬取的网页中提取的数据. 如果安装了 IPyth ...
- Java爬取51job保存到MySQL并进行分析
大二下实训课结业作业,想着就爬个工作信息,原本是要用python的,后面想想就用java试试看, java就自学了一个月左右,想要锻炼一下自己面向对象的思想等等的, 然后网上转了一圈,拉钩什么的是动态 ...
随机推荐
- STM32开发(一):简介及开发环境
1. 背景 STM32是意法(ST)公司开发的基于ARM Cortex-M系列的一系列微控制器(MCU). 有两种库 标准外设库(StdPeriph_Driver.Standard Periphera ...
- 三个数组求中位数,并且求最后中位数的中位数-----C++算法实现
文件Median.h #include <list> class CMedian { public: explicit CMedian(); virtual ~CMedian(); voi ...
- SDOI2013直径(树的直径)
题目描述: 点这里 题目大意: 就是在一个树上找其直径的长度是多少,以及有多少条边满足所有的直径都经过该边. 题解: 首先,第一问很好求,两边dfs就行了,第一次从任一点找距它最远的点,再从这个点找距 ...
- OCP认证052考试,新加的考试题还有答案整理-23题
23.Which two are true about data dictionary and dynamic performance views (v$ views)? A) All databas ...
- bzoj2705Longge的问题
题目链接 题意很简单 $$ans=\sum_{i=1}^{n}gcd(i,n)$$ 然后推一下式子,求一下欧拉函数就好了 细节是由于$BZOJ$的评测计时策略, 不能线性筛啊$……$ 必须每个数单独筛 ...
- bzoj1801中国象棋
题目链接 很裸的$dp+$组合计数 注意 注意 注意 $BZOJ$不要用玄学优化 $CE$不管$qwq$ /********************************************** ...
- CF1059C Sequence Transformation 题解
这几天不知道写点什么,状态也不太好,搬个题上来吧 题意:给定一个数n,设一个从1到n的序列,每次删掉一个序列中的数,求按字典序最大化的GCD序列 做法:按2的倍数找,但是如果除2能得到3的这种情况要特 ...
- CentOS下TFTP服务安装
CentOS下TFTP服务安装 今天和同学做交换机恢复DCN操作系统的任务,然后需要用到tftp,然后就开始研究.这里对TFTP服务进行介绍以及安装. tftp 比 ftp 更易于管理 tftp 比 ...
- 基本bash shell命令
以下列举一些常用的bash shell命令,在使用时方便查找. 访问Linux系统上的手册:man 命令.例:man ps 手册是由分页程序来显示的,可以通过点击 空格,回车,向上和向下箭头 ...
- 浅谈Object.create
在网上发现了Object.create的用法,感觉很是奇怪,所以学习记录下 var o = Object.create(null); console.log(o); // {} o.name = 'j ...