Map Reduce Application(Partitioninig/Binning)
Map Reduce Application(Partitioninig/Group data by a defined key)
Assuming we want to group data by the year(2008 to 2016) of their [last access date time]. For each year, we use a reducer to collect them and output the data in this group/partition(year of the last access datetime). So, we want the MR to partition our key by year. We will lean what's the default partitioner and see how to set custom partitioner.
The default partitioner:
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
Custom Partitioner:
job.setPartitionerClass(CustomPartitioner.class)
With blew partitioner, the data of different year of [last access date time] will be assigned to different / unique partition. The num of reduce tasks is 9.
public static class CustomPartitioner extends Partitioner<Text, Text>{
@Override
public int getPartition(Text key, Text value, int numReduceTasks){
if(numReduceTasks == 0){
return 0;
}
return key-2008
}
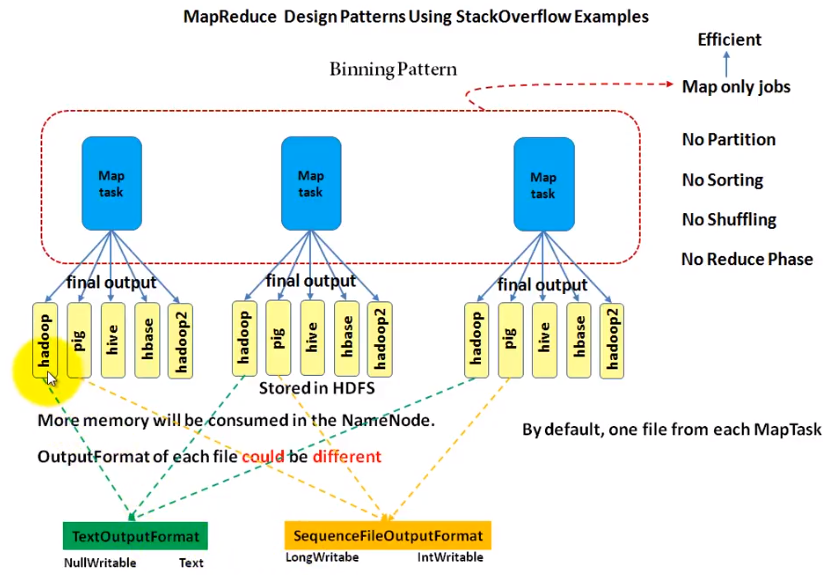
Binning pattern
The text/comments/answer/question....contains the specific words will be written into the corresponding files from mapper.
See below picture to understand the binning pattern. It is easier than partitioning as it does not have partition/sorting/shuffling and reducer(job.setNumReduceTasks(0)). The outputs from mappers compose the final outputs.
MultipleOutputs.addNamedOutput(job,"namedoutput",TextOutputFormat.class, NullWritable.class, Text.class)
In the mapper setup function, create the MultipleOutputs intance by calling its constructor
MultipleOutputs(TaskInputOutputContext<?,?,KEYOUT,VALUEOUT> context)
Creates and initializes multiple outputs support, it should be instantiated in the Mapper/Reducer setup method.
@Override
protected void setup(Context context){
maltipleOutputs = new MultipleOurputs(context);
}
Write your logic in the mapper function and output the result. "$tag/$tag-tag" means folder $pag will be created and $tag-tag is the prefix of the files(to distinguish the different mappers with suffix).
See doc for MultipleOutputs:https://hadoop.apache.org/docs/r3.0.1/api/org/apache/hadoop/mapreduce/lib/output/MultipleOutputs.html
if(tag.equalsIgnoreCase("pig"){
multipleOutputs.write("namedoutput",key,value,"pig/pig-tag");
}
if(tag.equalsIgnoreCase("hive"){
multipleOutputs.write("namedoutput",key,value,"hive/hive-tag");
}
.....
Map Reduce Application(Partitioninig/Binning)的更多相关文章
- Map Reduce Application(Join)
We are going to explain how join works in MR , we will focus on reduce side join and map side join. ...
- Map Reduce Application(Top 10 IDs base on their value)
Top 10 IDs base on their value First , we need to set the reduce to 1. For each map task, it is not ...
- mapreduce: 揭秘InputFormat--掌控Map Reduce任务执行的利器
随着越来越多的公司采用Hadoop,它所处理的问题类型也变得愈发多元化.随着Hadoop适用场景数量的不断膨胀,控制好怎样执行以及何处执行map任务显得至关重要.实现这种控制的方法之一就是自定义Inp ...
- MapReduce剖析笔记之三:Job的Map/Reduce Task初始化
上一节分析了Job由JobClient提交到JobTracker的流程,利用RPC机制,JobTracker接收到Job ID和Job所在HDFS的目录,够早了JobInProgress对象,丢入队列 ...
- python--函数式编程 (高阶函数(map , reduce ,filter,sorted),匿名函数(lambda))
1.1函数式编程 面向过程编程:我们通过把大段代码拆成函数,通过一层一层的函数,可以把复杂的任务分解成简单的任务,这种一步一步的分解可以称之为面向过程的程序设计.函数就是面向过程的程序设计的基本单元. ...
- 记一次MongoDB Map&Reduce入门操作
需求说明 用Map&Reduce计算几个班级中,每个班级10岁和20岁之间学生的数量: 需求分析 学生表的字段: db.students.insert({classid:1, age:14, ...
- filter,map,reduce,lambda(python3)
1.filter filter(function,sequence) 对sequence中的item依次执行function(item),将执行的结果为True(符合函数判断)的item组成一个lis ...
- map reduce
作者:Coldwings链接:https://www.zhihu.com/question/29936822/answer/48586327来源:知乎著作权归作者所有,转载请联系作者获得授权. 简单的 ...
- python基础——map/reduce
python基础——map/reduce Python内建了map()和reduce()函数. 如果你读过Google的那篇大名鼎鼎的论文“MapReduce: Simplified Data Pro ...
随机推荐
- 我的前端工具集(八)获得html元素在页面中的位置
我的前端工具集(八)获得html元素在页面中的位置 liuyuhang原创,未经允许禁止转载 目录 我的前端工具集 有时候需要用点击等操作,来获取某元素在页面中的位置,然后在该位置添加某些操作 如 ...
- 【Java】使用Atomic变量实现锁
Atomic原子操作 在 Java 5.0 提供了 java.util.concurrent(简称JUC)包,在此包中增加了在并发编程中很常用的工具类 Java从JDK1.5开始提供了java.uti ...
- 用IntelliJ IDEA 配置Maven并部署Maven工程到Tomcat(Windows中)
近几天做一个新项目才接触Intellij IDEA 1.在官网下载了maven 解压并新建一个本地仓库文件夹 2.配置本地仓库路径 3.配置maven环境变量 4.在IntelliJ IDEA中配置m ...
- mysql 的基本操作总结--增删改查
本文只是总结一下mysql 的基本操作,增删改查,以便忘记的时候可以查询一下 1.创建数据库 语法:CREATE DATABASES 数据库名; 例子: CREATE DATABASES studen ...
- 新手Linux命令学习
一.dd命令:1.可以复制文件,2.可以制作ios镜像,简单理解就是备份 常用的参数 if 设置输入文件的名称 of 设置输出文件的名称 bs 设置每个“”块“”大小 count 要复制“块” ...
- 分布式缓存 Redis(一)
概念 Redis是一个开源的使用ANSI C语言编写.支持网络.可基于内存亦可持久化的日志型.Key-Value数据库,和Memcached类似,它支持存储的value类型相对更多,包括string( ...
- 四、分离分层的 platform驱动
学习目标: 学习实现platform机制的分层分离,并基于platform机制,编写led设备和驱动程序: 一.分离分层 输入子系统.usb设备比驱动以及platform类型的驱动等都体现出分离分层机 ...
- MFC非模态添加进程控件方法一(线程方法)
由于非模态对话框的自己没有消息循环,创建后无法进行消息处理.需要和父窗口共用消息循环.如果单独在子窗口进行控件由于自己没有单独的消息循环,更新是无法进行的. 如果在父窗口更新控件会造成程序假死.如以下 ...
- 常用贴片三极管型号与丝印的对应关系(SOT23)
个人常用贴片三极管型号与丝印的对应关系(SOT23): 丝印:Y1 型号:8050,NPN型三极管 丝印:Y2 型号:8550,PNP型三极管 丝印:L6 ...
- python教程(一)·python环境搭建
python的环境搭建总的来说分为两大步:下载.安装(废话@_@).在这里以windows为例(Linux通常内置了python,就算没有内置,相信Linux用户也非常清楚软件的安装方法) 第一步-下 ...