论文笔记:Visual Semantic Navigation Using Scene Priors
Visual Semantic Navigation Using Scene Priors
2018-10-21 19:39:26
Paper: https://arxiv.org/pdf/1810.06543.pdf
Demo:https://www.youtube.com/watch?v=otKjuO805dE&feature=youtu.be
本文将首先定义什么是 visual semantic navigation, 然后描述怎么利用深度强化学习的框架来解决该问题,以及该任务的 baseline model。
1. 任务的定义:
视觉语义导航(Visual Semantic Navigation),即在给定的环境中,当我们所要找的目标物体在我们的视野中,并且距离该物体比较近(低于某一阈值)。

2. The Baseline Model:
我们将该问题定义为 DRL 的框架,给定语义任务的目标 g,智能体接收到一个状态 s,然后根据策略 π 从可能的动作集合 A 中采样出一个动作 a。我们用 deep Policy network 来估计该策略。由于 visual states 和 semantic objective 来自于不同的模态,我们设计两支子网络,来将该两个输入映射到联合的特征映射中去(a joint visual-semantic feature embedding)。
Visual Network:如图2所示,该网络输入为 224*224 RGB images,产生一个 512-D 的 feature vector。所用的 backbone 网络结构是 ResNet-50,本文所提取的 feature 是经过全连接层 和 ReLU layer 之后得到的 512-D 的特征作为 visual-semantic feature。
Semantic Network:语义任务的目标是通过物体的种类来描述的,例如:微波炉,电视等等。本文用 fastText 来计算 100-D 的 embedding。然后将这些 Word embedding 映射为 512-D feature。
Actor-Critic Policy Network:我们采用 A3C 的模型来在每一个时刻进行 policy 的估计。A3C model 的输入就是联合的 current state 和 semantic task objective 的特征表示,即:1024-D feature vector。该网络产生两个输出,即:the policy and the value。我们从预测的 policy 中采样出 action。
Reward:我们考虑 reward 的设计,使其能够最小化与目标物体的轨迹长度:
如果在一定的步数之内,接近了目标种类中的任何物体,都给 agent 一个大的 positive reward 10;
否则,我们惩罚每一个 step,用一个小的 negative reward -0.01.
而对于不同类型的 action,作者也给定不同类型的 reward,即:是否是 stop action。
3. Generalization with Graph Convolutional Networks:
3.1. Knowledge graph construction:
我们的知识图谱提供了两个优势:
1). 其编码了不同物体种类之间的空间关系(the spatial relationships between different object categories)
2). 其提供了 the spatial and visual relationships between the known objects and novel categories in cases that we have not seen any visual examples of the novel categories.
我们将知识图谱表示为:G=(V, E), 其中,V 和 G 分别表示 nodes 和 edges。具体的来说,每一个节点 v 代表了 an object category, 每一个 edge e 表示了a pair of object categories 之间的关系。作者采用 Visual Genome dataset (https://link.springer.com/content/pdf/10.1007%2Fs11263-016-0981-7.pdf, Project Page:https://visualgenome.org/) 作为构建 the knowledge graph 的来源。Visual Genome consists of over 100K natural images. Each image is annotated with objects, attributes and the relationships between objects. Since there is no predefined object category list, the annotators are free to label any objects in the image, which results in very diverse object categories.

在我们的实验当中,我们构建了一个知识图谱,将所有的出现在 AI2-THOR 环境中的物体种类都囊括中该 graph 中。每一个种类表示为 graph 中的一个 node。我们计算统计了 the Visual Genome dataset 中出现的 object-to-object relationships 的次数。当两个节点之间的出现频率超过三次的时候,我们就用一条边来连接这两个节点。图3展示了部分示例,如下所示:

3.2. Incorporating Semantic Knowledge into Actor-Critic Model:

3.2.1 GCN:

3.2.2 GCN for Navigation:
这里作者就是利用 GCN 来建模多个物体词汇之间的关系,从而协助 agent 更好的感知所接触到的环境。
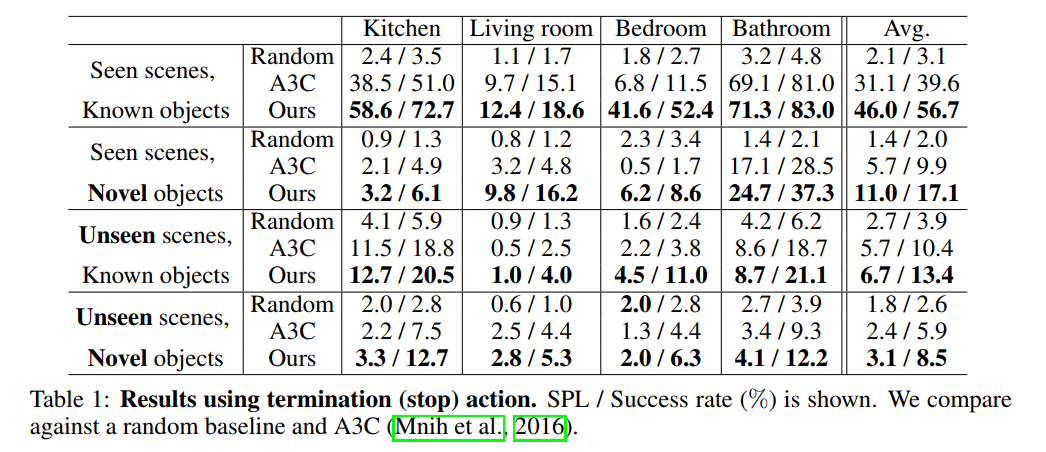
4. Experiments:


论文笔记:Visual Semantic Navigation Using Scene Priors的更多相关文章
- 论文:利用深度强化学习模型定位新物体(VISUAL SEMANTIC NAVIGATION USING SCENE PRIORS)
这是一篇被ICLR 2019 接收的论文.论文讨论了如何利用场景先验知识 (scene priors)来定位一个新场景(novel scene)中未曾见过的物体(unseen objects).举例来 ...
- 论文笔记:Semantic Segmentation using Adversarial Networks
Semantic Segmentation using Adversarial Networks 2018-04-27 09:36:48 Abstract: 对于产生式图像建模来说,对抗训练已经取得了 ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- 论文笔记: Dual Deep Network for Visual Tracking
论文笔记: Dual Deep Network for Visual Tracking 2017-10-17 21:57:08 先来看文章的流程吧 ... 可以看到,作者所总结的三个点在于: 1. ...
- 论文笔记之:Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning
论文笔记之:Action-Decision Networks for Visual Tracking with Deep Reinforcement Learning 2017-06-06 21: ...
- Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记
Deep Reinforcement Learning for Visual Object Tracking in Videos 论文笔记 arXiv 摘要:本文提出了一种 DRL 算法进行单目标跟踪 ...
- 图像显著性论文(一)—A Model of saliency Based Visual Attention for Rapid Scene Analysis
这篇文章是图像显著性领域最具代表性的文章,是在1998年Itti等人提出来的,到目前为止引用的次数超过了5000,是多么可怕的数字,在它的基础上发展起来的有关图像显著性论文更是数不胜数,论文的提出主要 ...
- 论文笔记之:Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking
Spatially Supervised Recurrent Convolutional Neural Networks for Visual Object Tracking arXiv Paper ...
- 论文笔记系列-Auto-DeepLab:Hierarchical Neural Architecture Search for Semantic Image Segmentation
Pytorch实现代码:https://github.com/MenghaoGuo/AutoDeeplab 创新点 cell-level and network-level search 以往的NAS ...
随机推荐
- MongoDB分片集群原理、搭建及测试详解
随着技术的发展,目前数据库系统对于海量数据的存储和高效访问海量数据要求越来越高,MongoDB分片机制就是为了解决海量数据的存储和高效海量数据访问而生. MongoDB分片集群由mongos路由进程( ...
- sqlserver开启远程访问
1.通过本地连接数据库,选择数据库——右键——属性 2.在连接选项勾选“允许远程连接到此服务器” 3.打开sqlserver配置管理器 4.到sqlserver网络配置——XXX的协议——TCP/IP ...
- Web开发——HTML基础(高级文本格式 列表/style)
文档资料参考: 参考:https://developer.mozilla.org/en-US/docs/Learn/HTML/Introduction_to_HTML/Advanced_text_fo ...
- Bom 字符串的问题
不含 BOM 的 UTF-8 才是标准形式",的确是这样,无BOM使用得更多些,所以个人还是推荐一般情况下用无BOM的形式吧,除非有问题的时候,再考虑换有BOM的.Windows系统保存的都 ...
- 转:sql篇 select from where group by having order by
原文地址: sql篇 select from where group by having order by select from where group by having order by 的基 ...
- (转载)Java Map中的Value值如何做到可以为任意类型的值
转载地址:http://www.importnew.com/15556.html 如有侵权,请联系作者及时删除. 搬到我的博客来,有空细细品味,把玩. 本文由 ImportNew - shut ...
- (转载)中文Appium API 文档
该文档是Testerhome官方翻译的源地址:https://github.com/appium/appium/tree/master/docs/cn官方网站上的:http://appium.io/s ...
- java框架之Struts2(4)-拦截器&标签库
拦截器 概述 Interceptor (拦截器):起到拦截客户端对 Action 请求的作用. Filter:过滤器,过滤客户端向服务器发送的请求. Interceptor:拦截器,拦截的是客户端对 ...
- IO实时监控命令iostat详解
iostat用于输出CPU和磁盘I/O相关的统计信息 命令格式 iostat [ -c ] [ -d ] [ -h ] [ -N ] [ -k | -m ] [ -t ] [ -V ] [ -x ] ...
- (转)Golang--使用iota(常量计数器)
iota是golang语言的常量计数器,只能在常量的表达式中使用. iota在const关键字出现时将被重置为0(const内部的第一行之前),const中每新增一行常量声明将使iota计数一次(io ...