第1节 flume:13、14、更多flume案例一,通过拦截器实现不同类型的数据区分
1.6、flume案例一
1. 案例场景
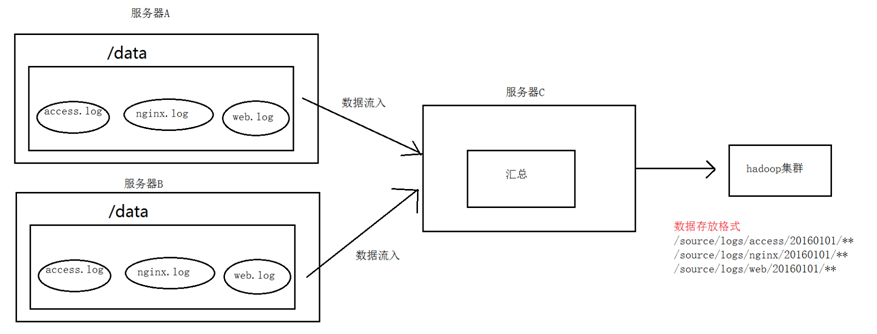
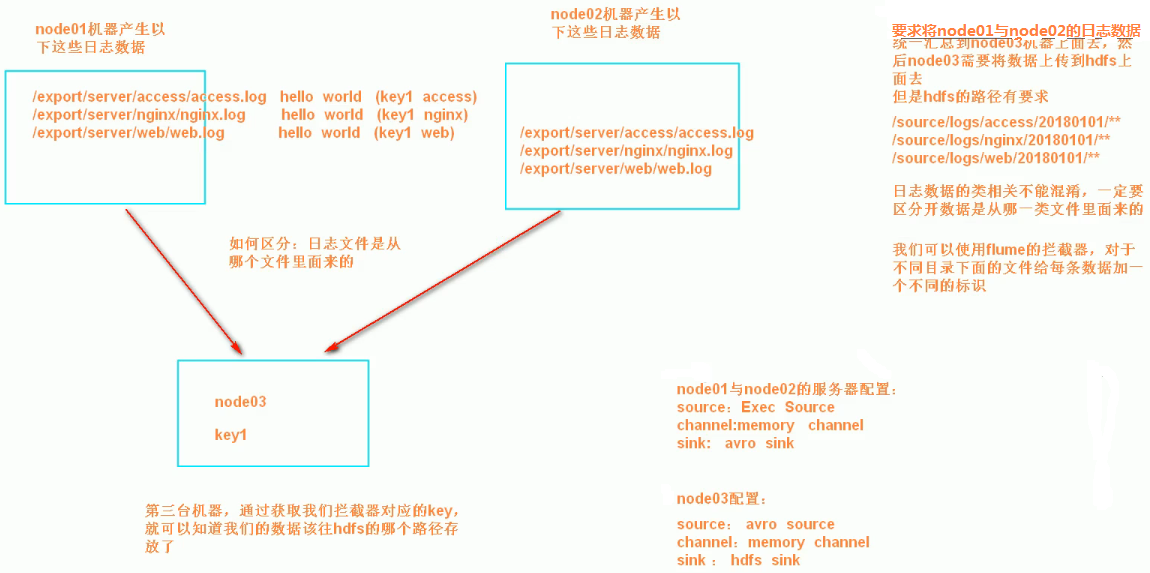
A、B两台日志服务机器实时生产日志主要类型为access.log、nginx.log、web.log
现在要求:
把A、B 机器中的access.log、nginx.log、web.log 采集汇总到C机器上然后统一收集到hdfs中。
但是在hdfs中要求的目录为:
/source/logs/access/20180101/**
/source/logs/nginx/20180101/**
/source/logs/web/20180101/**
2. 场景分析
3. 数据流程处理分析
4、实现
服务器A对应的IP为 192.168.52.100
服务器B对应的IP为 192.168.52.110
服务器C对应的IP为 192.168.52.120
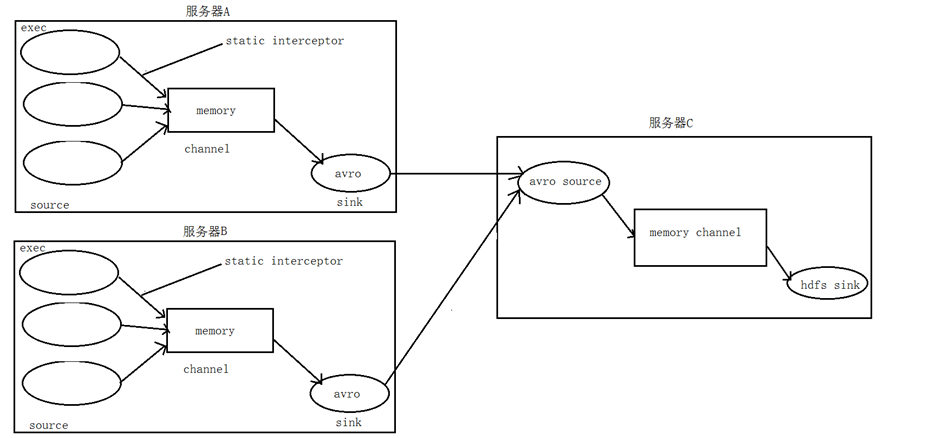
采集端配置文件开发
node01与node02服务器开发flume的配置文件
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/conf
vim exec_source_avro_sink.conf
# Name the components on this agent
a1.sources = r1 r2 r3
a1.sinks = k1
a1.channels = c1
# Describe/configure the source
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /export/servers/taillogs/access.log
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = static
## static拦截器的功能就是往采集到的数据的header中插入自己定## 义的key-value对
a1.sources.r1.interceptors.i1.key = type
a1.sources.r1.interceptors.i1.value = access
a1.sources.r2.type = exec
a1.sources.r2.command = tail -F /export/servers/taillogs/nginx.log
a1.sources.r2.interceptors = i2
a1.sources.r2.interceptors.i2.type = static
a1.sources.r2.interceptors.i2.key = type
a1.sources.r2.interceptors.i2.value = nginx
a1.sources.r3.type = exec
a1.sources.r3.command = tail -F /export/servers/taillogs/web.log
a1.sources.r3.interceptors = i3
a1.sources.r3.interceptors.i3.type = static
a1.sources.r3.interceptors.i3.key = type
a1.sources.r3.interceptors.i3.value = web
# Describe the sink
a1.sinks.k1.type = avro
a1.sinks.k1.hostname = node03
a1.sinks.k1.port = 41414
# Use a channel which buffers events in memory
a1.channels.c1.type = memory
a1.channels.c1.capacity = 20000
a1.channels.c1.transactionCapacity = 10000
# Bind the source and sink to the channel
a1.sources.r1.channels = c1
a1.sources.r2.channels = c1
a1.sources.r3.channels = c1
a1.sinks.k1.channel = c1
服务端配置文件开发
在node03上面开发flume配置文件
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin/conf
vim avro_source_hdfs_sink.conf
a1.sources = r1
a1.sinks = k1
a1.channels = c1
#定义source
a1.sources.r1.type = avro
a1.sources.r1.bind = 192.168.52.120
a1.sources.r1.port =41414
#添加时间拦截器
a1.sources.r1.interceptors = i1
a1.sources.r1.interceptors.i1.type = org.apache.flume.interceptor.TimestampInterceptor$Builder
#定义channels
a1.channels.c1.type = memory
a1.channels.c1.capacity = 20000
a1.channels.c1.transactionCapacity = 10000
#定义sink
a1.sinks.k1.type = hdfs
a1.sinks.k1.hdfs.path=hdfs://192.168.52.100:8020/source/logs/%{type}/%Y%m%d
a1.sinks.k1.hdfs.filePrefix =events
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
#时间类型
a1.sinks.k1.hdfs.useLocalTimeStamp = true
#生成的文件不按条数生成
a1.sinks.k1.hdfs.rollCount = 0
#生成的文件按时间生成
a1.sinks.k1.hdfs.rollInterval = 30
#生成的文件按大小生成
a1.sinks.k1.hdfs.rollSize = 10485760
#批量写入hdfs的个数
a1.sinks.k1.hdfs.batchSize = 10000
#flume操作hdfs的线程数(包括新建,写入等)
a1.sinks.k1.hdfs.threadsPoolSize=10
#操作hdfs超时时间
a1.sinks.k1.hdfs.callTimeout=30000
#组装source、channel、sink
a1.sources.r1.channels = c1
a1.sinks.k1.channel = c1
采集端文件生成脚本
在node01与node02上面开发shell脚本,模拟数据生成
cd /export/servers/shells
vim server.sh
#!/bin/bash
while true
do
date >> /export/servers/taillogs/access.log;
date >> /export/servers/taillogs/web.log;
date >> /export/servers/taillogs/nginx.log;
sleep 0.5;
done
顺序启动服务
node03启动flume实现数据收集
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin
bin/flume-ng agent -c conf -f conf/avro_source_hdfs_sink.conf -name a1 -Dflume.root.logger=DEBUG,console
node01与node02启动flume实现数据监控
cd /export/servers/apache-flume-1.6.0-cdh5.14.0-bin
bin/flume-ng agent -c conf -f conf/exec_source_avro_sink.conf -name a1 -Dflume.root.logger=DEBUG,console
node01与node02启动生成文件脚本
cd /export/servers/shells
sh server.sh
5、项目实现截图
第1节 flume:13、14、更多flume案例一,通过拦截器实现不同类型的数据区分的更多相关文章
- Flume 拦截器(interceptor)详解
flume 拦截器(interceptor)1.flume拦截器介绍拦截器是简单的插件式组件,设置在source和channel之间.source接收到的事件event,在写入channel之前,拦截 ...
- 大数据学习——flume拦截器
flume 拦截器(interceptor)1.flume拦截器介绍拦截器是简单的插件式组件,设置在source和channel之间.source接收到的事件event,在写入channel之前,拦截 ...
- 第1节 flume:15、flume案例二,通过自定义拦截器实现数据的脱敏
1.7.flume案例二 案例需求: 在数据采集之后,通过flume的拦截器,实现不需要的数据过滤掉,并将指定的第一个字段进行加密,加密之后再往hdfs上面保存 原始数据与处理之后的数据对比 图一 ...
- Flume 自定义拦截器 多行读取日志+截断
前言: Flume百度定义如下: Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据:同时,F ...
- 分布式实时日志系统(二) 环境搭建之 flume 集群搭建/flume ng资料
最近公司业务数据量越来越大,以前的基于消息队列的日志系统越来越难以满足目前的业务量,表现为消息积压,日志延迟,日志存储日期过短,所以,我们开始着手要重新设计这块,业界已经有了比较成熟的流程,即基于流式 ...
- flume【源码分析】分析Flume的拦截器
h2 { color: #fff; background-color: #7CCD7C; padding: 3px; margin: 10px 0px } h3 { color: #fff; back ...
- Flume自定义拦截器(Interceptors)或自带拦截器时的一些经验技巧总结(图文详解)
不多说,直接上干货! 一.自定义拦截器类型必须是:类全名$内部类名,其实就是内部类名称 如:zhouls.bigdata.MySearchAndReplaceInterceptor$Builder 二 ...
- js如何判断一组数字是否连续,得到一个临时数组[[3,4],[13,14,15],[17],[20],[22]];
var arrange = function(arr){ var result = [], temp = []; arr.sort(function(source, dest){ return sou ...
- intellij idea 13&14 插件推荐及快速上手建议 (已更新!)
原文:intellij idea 13&14 插件推荐及快速上手建议 (已更新!) 早些年 在外企的时候,公司用的是intellij idea ,当时也是从eclipse.MyEclipse转 ...
随机推荐
- HDU3065【AC自动机-AC感言】
Fourth AC zi dong ji(Aho-Corasick Automation) of life 9A(其实不止交了10发...) 感言: 一开始多组数据这种小数据还是...无伤大局,因为改 ...
- [HNOI2010] 物品调度 fsk
标签:链表+数论知识. 题解: 对于这道题,其实就是两个问题的拼凑,我们分开来看. 首先要求xi与yi.这个可以发现,x每增加1,则pos增加d:y每增加1,则pos增加1.然后,我们把x与y分别写在 ...
- Oracle Java SE 组件概念图
JDK1.8 组件概念图
- C#求圆的周长、面积、体积
窗体应用程序 private void button1_Click(object sender, EventArgs e) { double r; r = Convert.ToInt32(textBo ...
- Ibatis相关
XML中的#和$的区别 http://shenzhenchufa.blog.51cto.com/730213/254561 poolMaximumActiveConnections和poolMaxim ...
- rn-splash-screen 启动页 安卓
1. 进入项目npm install --save rn-splash-screen 2.react-native link rn-splash-screen 3.在项目android/app/src ...
- jmeter常用的beanshell脚本
时间戳下载文件保存响应内容断言连接数据库解析jsonlist递归创建多级目录 常用内置变量调用cmd文件GUI小命令 时间戳import java.text.SimpleDateFormat;impo ...
- Codeforces Round #402 (Div. 2) A
Description In Berland each high school student is characterized by academic performance — integer v ...
- Promise.then(a, b)与Promise.then(a).catch(b)问题详解
原文: When is .then(success, fail) considered an antipattern for promises? 问题 我在bluebrid promise FAQ上面 ...
- C语言的面向对象技术
引言:面向过程的C有效率高,代码紧凑的特点,在单片机嵌入式领域是C的主要阵地,while(1)+中断是其主要的开发模式,但是当系统复杂到一定程度,想要添加一个功能需要改动很多地方,耦合性太强:跟别人交 ...