推荐系统之余弦相似度的Spark实现
推荐系统之余弦相似度的Spark实现
(1)原理分析
余弦相似度度量是相似度度量中最常用的度量关系,从程序分析中,
- 第一步是数据的输入,
- 其次是使用相似性度量公式
- 最后是对不同用户的递归计算。
本例子是基于欧几里得举例的相似度计算。
(2)源代码
package com.bigdata.demo
import org.apache.spark.{SparkContext, SparkConf}
/**
* Created by SimonsZhao on 3/29/2017.
*/
object CollaborativeFilteringSpark {
//1.设置环境变量
val conf=new SparkConf().setMaster("local").setAppName("CollaborativeFilteringSpark")
//2.实例化环境
val sc=new SparkContext(conf)
//3.设置用户
val users=sc.parallelize(Array("aaa","bbb","ccc","ddd","eee"))
//4.设置电影名
sc.parallelize(Array("smzdm","ylxb","znb","nhsc","fcwr"))
//5.使用一个source嵌套map作为姓名电影名和分值的存储
var source=Map[String,Map[String,Int]]()
//6.设置一个用以存放电影分的map
val filmSource =Map[String,Int]()
//7.设置电影评分
def getSource():Map[String,Map[String,Int]]={
val user1FilmSource=Map("smzdm"->2,"ylxb"->3,"znb"->1,"nhsc"->0,"fcwr"->1)
val user2FilmSource=Map("smzdm"->1,"ylxb"->2,"znb"->2,"nhsc"->1,"fcwr"->4)
val user3FilmSource=Map("smzdm"->2,"ylxb"->1,"znb"->0,"nhsc"->1,"fcwr"->4)
val user4FilmSource=Map("smzdm"->3,"ylxb"->2,"znb"->0,"nhsc"->5,"fcwr"->3)
val user5FilmSource=Map("smzdm"->5,"ylxb"->3,"znb"->1,"nhsc"->1,"fcwr"->2)
//存储人的名字
source += ("aaa" -> user1FilmSource)
//存储人的名字
source += ("bbb" -> user2FilmSource)
//存储人的名字
source += ("ccc" -> user3FilmSource)
//存储人的名字
source += ("ddd" -> user4FilmSource)
//存储人的名字
source += ("eee" -> user5FilmSource)
//返回嵌套的map
source
}
//采用余弦相似度两两计算分值
def getCollaborateSource(user1:String,user2:String):Double={
//获得第一个用户的评分
val user1FilmSource =source.get(user1).get.values.toVector
//获得第二个用户的评分
val user2FileSource=source.get(user2).get.values.toVector
//对公示分子部分进行计算
val member=user1FilmSource.zip(user2FileSource).map(d => d._1 *d._2).reduce(_+_).toDouble
//求解分母的第一个变量
val temp1=math.sqrt(user1FilmSource.map(num=>{math.pow(num,2)}).reduce(_+_))
//求解分母第二个变量
val temp2=math.sqrt(user2FileSource.map(num=>{math.pow(num,2)}).reduce(_+_))
//求出分母
val denominator=temp1*temp2
//求出分式的值
member/denominator
}
def main(args: Array[String]) {
//初始化分数
getSource()
//设定目标对象
val name="bbb"
//进行迭代计算
users.foreach(user=>{
println(name+" 相对于"+user+"的相似性分数是:"+getCollaborateSource(name,user))
})
}
}
点击可复制代码
package com.bigdata.demo
import org.apache.spark.{SparkContext, SparkConf}
/**
* Created by SimonsZhao on 3/29/2017.
*/
object CollaborativeFilteringSpark {
//1.设置环境变量
val conf=new SparkConf().setMaster("local").setAppName("CollaborativeFilteringSpark")
//2.实例化环境
val sc=new SparkContext(conf)
//3.设置用户
val users=sc.parallelize(Array("aaa","bbb","ccc","ddd","eee"))
//4.设置电影名
sc.parallelize(Array("smzdm","ylxb","znb","nhsc","fcwr"))
//5.使用一个source嵌套map作为姓名电影名和分值的存储
var source=Map[String,Map[String,Int]]()
//6.设置一个用以存放电影分的map
val filmSource =Map[String,Int]()
//7.设置电影评分
def getSource():Map[String,Map[String,Int]]={
val user1FilmSource=Map("smzdm"->2,"ylxb"->3,"znb"->1,"nhsc"->0,"fcwr"->1)
val user2FilmSource=Map("smzdm"->1,"ylxb"->2,"znb"->2,"nhsc"->1,"fcwr"->4)
val user3FilmSource=Map("smzdm"->2,"ylxb"->1,"znb"->0,"nhsc"->1,"fcwr"->4)
val user4FilmSource=Map("smzdm"->3,"ylxb"->2,"znb"->0,"nhsc"->5,"fcwr"->3)
val user5FilmSource=Map("smzdm"->5,"ylxb"->3,"znb"->1,"nhsc"->1,"fcwr"->2)
//存储人的名字
source += ("aaa" -> user1FilmSource)
//存储人的名字
source += ("bbb" -> user2FilmSource)
//存储人的名字
source += ("ccc" -> user3FilmSource)
//存储人的名字
source += ("ddd" -> user4FilmSource)
//存储人的名字
source += ("eee" -> user5FilmSource)
//返回嵌套的map
source
}
//采用余弦相似度两两计算分值
def getCollaborateSource(user1:String,user2:String):Double={
//获得第一个用户的评分
val user1FilmSource =source.get(user1).get.values.toVector
//获得第二个用户的评分
val user2FileSource=source.get(user2).get.values.toVector
//对公示分子部分进行计算
val member=user1FilmSource.zip(user2FileSource).map(d => d._1 *d._2).reduce(_+_).toDouble
//求解分母的第一个变量
val temp1=math.sqrt(user1FilmSource.map(num=>{math.pow(num,2)}).reduce(_+_))
//求解分母第二个变量
val temp2=math.sqrt(user2FileSource.map(num=>{math.pow(num,2)}).reduce(_+_))
//求出分母
val denominator=temp1*temp2
//求出分式的值
member/denominator
}
def main(args: Array[String]) {
//初始化分数
getSource()
//设定目标对象
val name="bbb"
//进行迭代计算
users.foreach(user=>{
println(name+" 相对于"+user+"的相似性分数是:"+getCollaborateSource(name,user))
})
}
}
点击+可复制代码
(3)结果分析
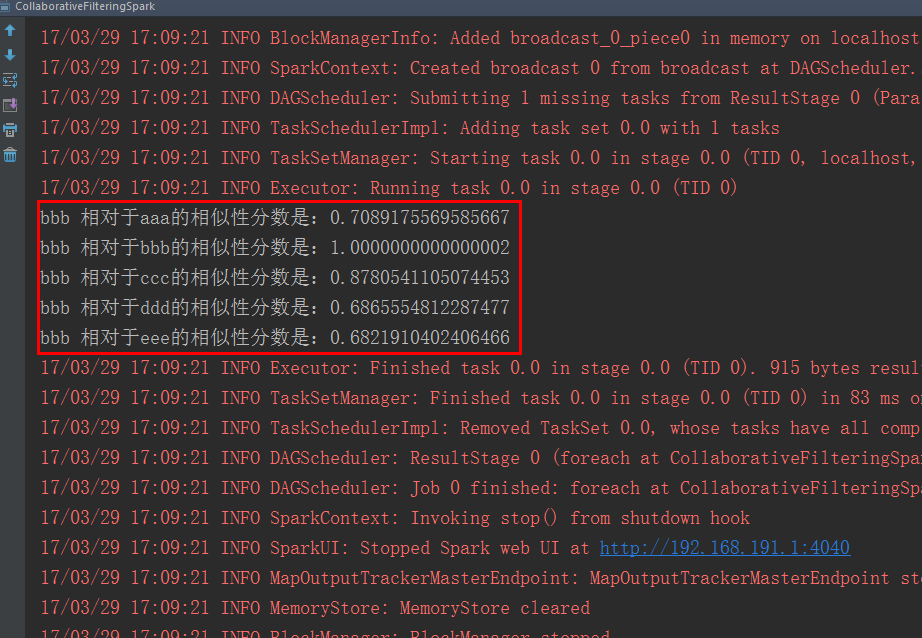
推荐系统之余弦相似度的Spark实现的更多相关文章
- Spark/Scala实现推荐系统中的相似度算法(欧几里得距离、皮尔逊相关系数、余弦相似度:附实现代码)
在推荐系统中,协同过滤算法是应用较多的,具体又主要划分为基于用户和基于物品的协同过滤算法,核心点就是基于"一个人"或"一件物品",根据这个人或物品所具有的属性, ...
- Spark Mllib里相似度度量(基于余弦相似度计算不同用户之间相似性)(图文详解)
不多说,直接上干货! 常见的推荐算法 1.基于关系规则的推荐 2.基于内容的推荐 3.人口统计式的推荐 4.协调过滤式的推荐 协调过滤算法,是一种基于群体用户或者物品的典型推荐算法,也是目前常用的推荐 ...
- spark MLlib 概念 5: 余弦相似度(Cosine similarity)
概述: 余弦相似度 是对两个向量相似度的描述,表现为两个向量的夹角的余弦值.当方向相同时(调度为0),余弦值为1,标识强相关:当相互垂直时(在线性代数里,两个维度垂直意味着他们相互独立),余弦值为0, ...
- 【Math】余弦相似度 和 Pearson相关系数
http://cucmakeit.github.io/2014/11/13/%E4%BF%AE%E6%AD%A3%E4%BD%99%E5%BC%A6%E7%9B%B8%E4%BC%BC%E5%BA%A ...
- 相似度度量:欧氏距离与余弦相似度(Similarity Measurement Euclidean Distance Cosine Similarity)
在<机器学习---文本特征提取之词袋模型(Machine Learning Text Feature Extraction Bag of Words)>一文中,我们通过计算文本特征向量之间 ...
- java算法(1)---余弦相似度计算字符串相似率
余弦相似度计算字符串相似率 功能需求:最近在做通过爬虫技术去爬取各大相关网站的新闻,储存到公司数据中.这里面就有一个技术点,就是如何保证你已爬取的新闻,再有相似的新闻 或者一样的新闻,那就不存储到数据 ...
- 皮尔逊相关系数与余弦相似度(Pearson Correlation Coefficient & Cosine Similarity)
之前<皮尔逊相关系数(Pearson Correlation Coefficient, Pearson's r)>一文介绍了皮尔逊相关系数.那么,皮尔逊相关系数(Pearson Corre ...
- 两矩阵各向量余弦相似度计算操作向量化.md
余弦相似度计算: \cos(\bf{v_1}, \bf{v_2}) = \frac{\left( v_1 \times v_2 \right)}{||v_1|| * ||v_2|| } \cos(\b ...
- TF版本的Word2Vec和余弦相似度的计算
前几天一个同学在看一段代码,内容是使用gensim包提供的Word2Vec方法训练得到词向量,里面有几个变量code.count.index.point看不懂,就向我求助,我大概给他讲了下code是哈 ...
随机推荐
- git同时提交到两个仓库
有时候一个项目,希望既提交到oschina又提交到公司内网的gitlab,或者是github什么的. 使用git remote -v 查看当前git的远程仓库. 添加一个远程仓库 git remote ...
- js中判断浏览器版本
var ai = { ovb: { /** * 该对象用于判断系统,系统版本,浏览器,苹果设备等等功能.ovb是单词 Os Version Browser 的头字母缩写. */ _version_va ...
- MTK 时区修改
1.修改packages/apps/Settings/res/xml-xx-xx/timezones.xml (xx-xx表示不同的语言和区域),添加下面的内容: <!-- timezo ...
- [Bayes ML] This is Bayesian Machine Learning
From: http://www.cnblogs.com/bayesianML/p/6377588.html#central_problem You can do it: Dirichlet Proc ...
- MAP参数估计
(学习这部分内容大约需要40分钟) 摘要 在贝叶斯参数估计中, 除了先验是特别选定的情况下, 通常要积分掉所有模型参数是没有解析解的. 在这种情况下, 最大后验(maximum a posterior ...
- ios开发之--armv7,armv7s,arm64,i386,x86_64详解
有时候在运行的时候,经常出现诸如i386的错误,最新一些可能会出现 No architectures to compile for (ONLY_ACTIVE_ARCH=YES, active arch ...
- iOS 优秀文章网址收录
1. iOS应用支持IPV6,就那点事儿 地址:http://www.jianshu.com/p/a6bab07c4062 2. iOS配置IPV6网络 地址:http://www.jianshu.c ...
- Jackson(ObjectMapper)的简单使用(可转xml)
参考文章:http://www.cnblogs.com/hoojo/archive/2011/04/22/2024628.html (原文章更详细哦,且有介绍xml与java对象的互转) 参考文章作 ...
- 【Postgres】PostgreSQL配置远程连接
1.开启相应的防火墙端口,缺省是5432 2.访问权限配置,D:\Program Files (x86)\PostgreSQL\9.2\data/pg_hba.conf中加入如下配置,开启远程访问 3 ...
- PostgreSQL存储过程(4)-return语句
1. return语句 有三个命令可以用来从函数中返回数据: RETURN RETURN NEXT RETURN QUERY 2. RETURN命令 语法: RETURN RETURN express ...