Spark中groupBy groupByKey reduceByKey的区别
groupBy
和SQL中groupby一样,只是后面必须结合聚合函数使用才可以。
例如:
hour.filter($"version".isin(version: _*)).groupBy($"version").agg(countDistinct($"id"), count($"id")).show()
groupByKey
对Key-Value形式的RDD的操作。
例如(取自link):
val a = sc.parallelize(List("dog", "tiger", "lion", "cat", "spider", "eagle"), 2)
val b = a.keyBy(_.length)//给value加上key,key为对应string的长度
b.groupByKey.collect
//结果 Array((4,ArrayBuffer(lion)), (6,ArrayBuffer(spider)), (3,ArrayBuffer(dog, cat)), (5,ArrayBuffer(tiger, eagle)))
reduceByKey
与groupByKey功能一样,只是实现不一样。本函数会先在每个分区聚合然后再进行总的统计,如图:
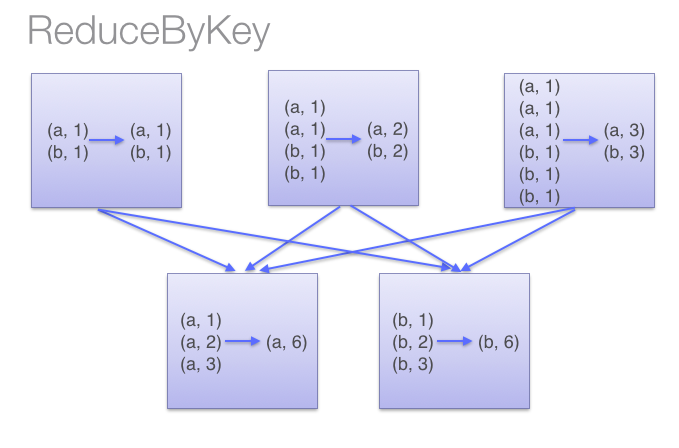
而groupByKey则是
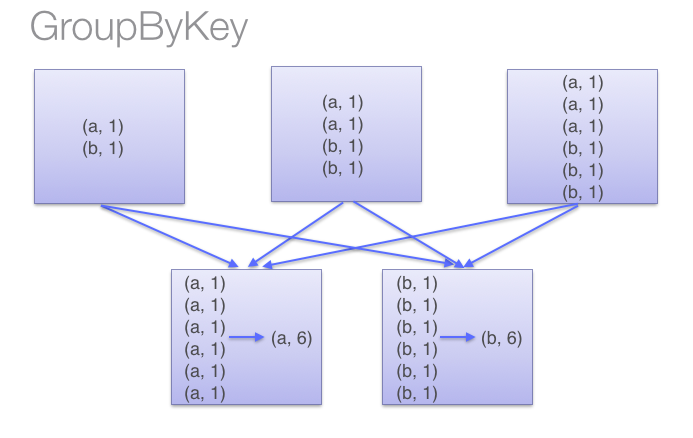
因此,本函数比groupByKey节省了传播的开销,尽量少用groupByKey
参考
- https://www.iteblog.com/archives/1357.html
- http://blog.csdn.net/guotong1988/article/details/50556871
- http://blog.cheyo.net/178.html
Spark中groupBy groupByKey reduceByKey的区别的更多相关文章
- [Spark RDD_add_1] groupByKey & reduceBykey 的区别
[groupByKey & reduceBykey 的区别] 在都能实现相同功能的情况下优先使用 reduceBykey Combine 是为了减少网络负载 1. groupByKey 是没有 ...
- Spark中ml和mllib的区别
转载自:https://vimsky.com/article/3403.html Spark中ml和mllib的主要区别和联系如下: ml和mllib都是Spark中的机器学习库,目前常用的机器学习功 ...
- 015 在Spark中关于groupByKey与reduceByKey的区别
1.groupByKey的源代码 2.groupByKey的使用缺点 不使用groupByKey的主要原因:在大规模的数据下,数据分布不均匀的情况下,可能导致OOM 3.reduceByKey的源代码 ...
- spark中map与flatMap的区别
作为spark初学者对,一直对map与flatMap两个函数比较难以理解,这几天看了和写了不少例子,终于把它们搞清楚了 两者的区别主要在于action后得到的值 例子: import org.apac ...
- Spark中cache和persist的区别
cache和persist都是用于将一个RDD进行缓存的,这样在之后使用的过程中就不需要重新计算了,可以大大节省程序运行时间. cache和persist的区别 基于Spark 1.6.1 的源码,可 ...
- Spark中repartition和partitionBy的区别
repartition 和 partitionBy 都是对数据进行重新分区,默认都是使用 HashPartitioner,区别在于partitionBy 只能用于 PairRDD,但是当它们同时都用于 ...
- spark中产生shuffle的算子
Spark中产生shuffle的算子 作用 算子名 能否替换,由谁替换 去重 distinct() 不能 聚合 reduceByKey() groupByKey groupBy() groupByKe ...
- Spark程序使用groupByKey后数据存入HBase出现重复的现象
最近在一个项目中做数据的分类存储,在spark中使用groupByKey后存入HBase,发现数据出现双份( 所有记录的 rowKey 是随机 唯一的 ) .经过不断的测试,发现是spark的运行参 ...
- Spark 中 GroupByKey 相对于 combineByKey, reduceByKey, foldByKey 的优缺点
避免使用GroupByKey 我们看一下两种计算word counts 的方法,一个使用reduceByKey,另一个使用 groupByKey: val words = Array("on ...
随机推荐
- spring hiberante 集成出现异常 java.lang.ClassNotFoundException: org.hibernate.engine.SessionFactoryImplementor
出现如题的异常是由于hibernate和spring集成时的的版本不一致所导致. 如下面,所示,如果你用的hibneate 4.0及以上版本,那么将会报错,因为这里用的事务管理是hibernate 3 ...
- UCP规模估算方法介绍 基于UCP方法的软件项目成本估计及其应用方法,软件,项目,UCP方法,应用,项目估算及软件及应用,软件估算,项目成本,软件项目
基于UCP方法的软件项目成本估计及其应用 UCP说明: UCP = 交易的UCP数 + Actor的UCP数,1.交易/Actor在估算时按复杂度分为简单.普通.复杂.主观类别,权重分别对应1.2.3 ...
- go interface 的坑
一.概述 [root@node175 demo]# tree . ├── lib │ └── world.go ├── README └── server.go directory, files ...
- <welcome-file>index.action</welcome-file>直接设置action,404和struts2中的解决方案
这几天的项目页面的访问全部改为.action访问,在修改首页时遇到了问题.将web.xml文件中<welcome-file>index.action</welcome-file> ...
- Mac OS下Android Studio的Java not found问题,androidfound
Android Studio正式版已经发布一段时间了,使用Mac版的Android Studio可能与遇到Java not found:Android Studio was unable to fin ...
- xtrabackup-工作原理
数据备份 xtrabackup是基于innodb的crash恢复功能之上的.它会拷贝innodb数据文件(这会导致数据不一致的),然后对文件执行crash恢复使其一致. 因为innodb维护了redo ...
- iphone 开发中使用zbar时遇到的几个典型问题解决方法。
iphone 开发中使用zbar时遇到的几个典型问题解决方法. 在近期的一个ios项目中使用到了一个二维码扫描库(Qrcode)--ZBar, 期间遇到2个问题. 1. zbar下载后使用其l ...
- Nginx启动/重启脚本详解
Nginx手动启动 停止操作 停止操作是通过向nginx进程发送信号(什么是信号请参阅linux文 章)来进行的步骤1:查询nginx主进程号ps -ef | grep nginx在进程列表里 面找m ...
- gcc cc1: all warnings being treated as errors
cc1: all warnings being treated as errors 在Makefile中找到 -Werror项,删除即可.删除后重新编译. 或设置环境变量 c工程设置 export C ...
- Mysql:MyIsam和InnoDB的区别
MyISAM: 这个是默认类型,它是基于传统的ISAM类型,ISAM是Indexed Sequential Access Method (有索引的 顺序访问方法) 的缩写,它是存储记录和文件的标准方法 ...