如何使用 python 爬取酷我在线音乐
前言
写这篇博客的初衷是加深自己对网络请求发送和响应的理解,仅供学习使用,请勿用于非法用途!文明爬虫,从我做起。下面进入正题。
获取歌曲信息列表
在酷我的搜索框中输入关键词 aiko,回车之后可以看到所有和 aiko 相关的歌曲。打开开发者模式,在网络面板下按下 ctrl + f,搜索 二人,可以找到响应结果中包含 二人 的请求,这个请求就是用来获取歌曲信息列表的。
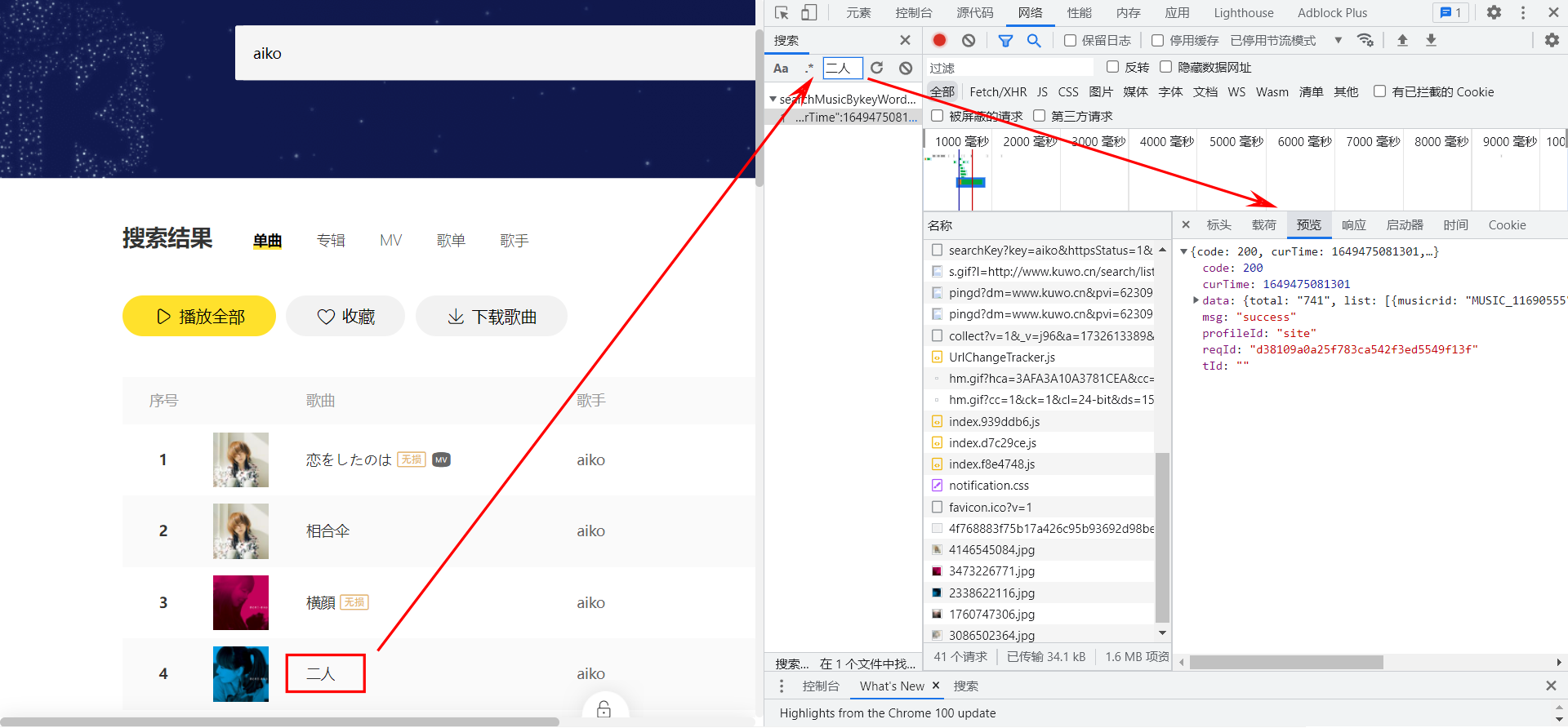
请求参数分析
请求的具体格式如下图所示,可以看到请求路径为 http://www.kuwo.cn/api/www/search/searchMusicBykeyWord,请求参数包括:
key: 搜索关键词,此处为aikopn: 页码,page number的缩写,此处为1rn: 每页条目数,应该是row number的缩写,默认为30httpsStatus:https 的状态?感觉没啥大用,看了源代码里面是直接写死t.url = t.url + "?reqId=".concat(n, "&httpsStatus=1")reqId:请求标识,刷新页面之后值会发生改变,不知道有啥用,待会儿模拟请求的时候试着不带上他会怎么样
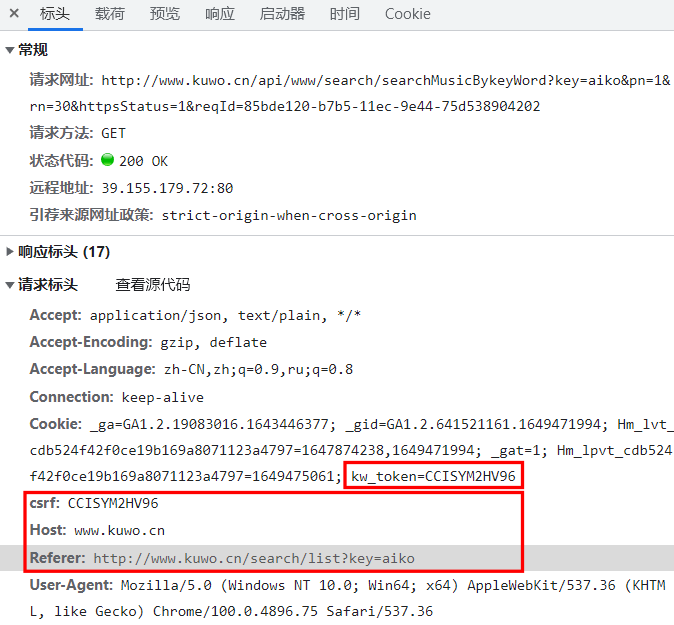
打开 Apifox(当然 postman 也行),新建一个接口,把请求路径和参数设置为下图所示的样子,为了让响应结果简短点,这里把每页的条目数设置为 1 而非默认的 30:
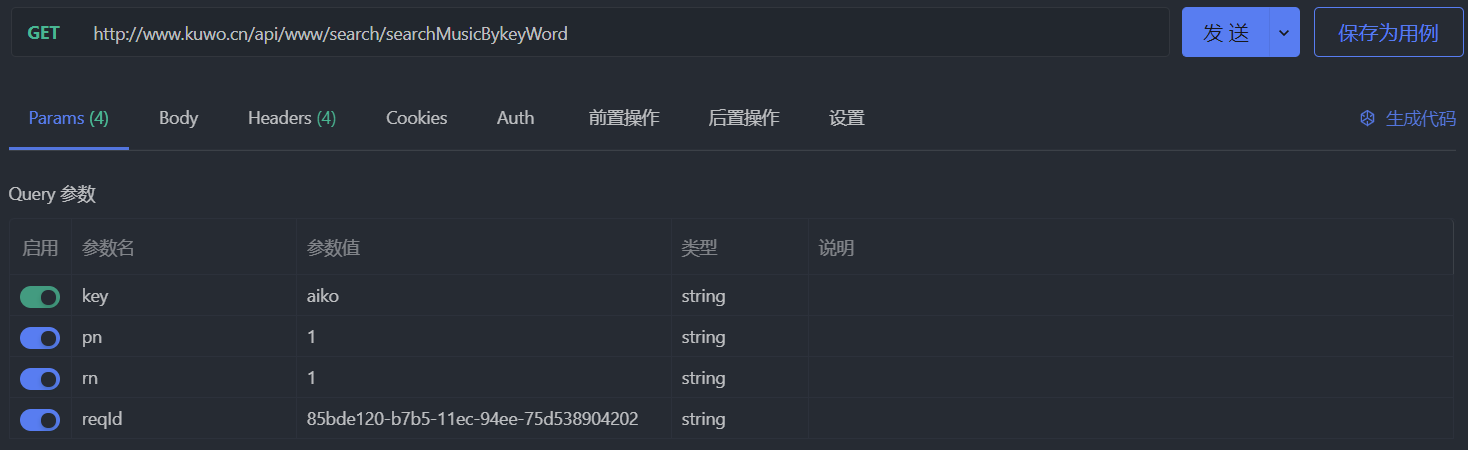
在没有设置额外请求头的情况下发个请求试试,发现 403 Forbidden 了,emmmmm,应该是防盗链所致:
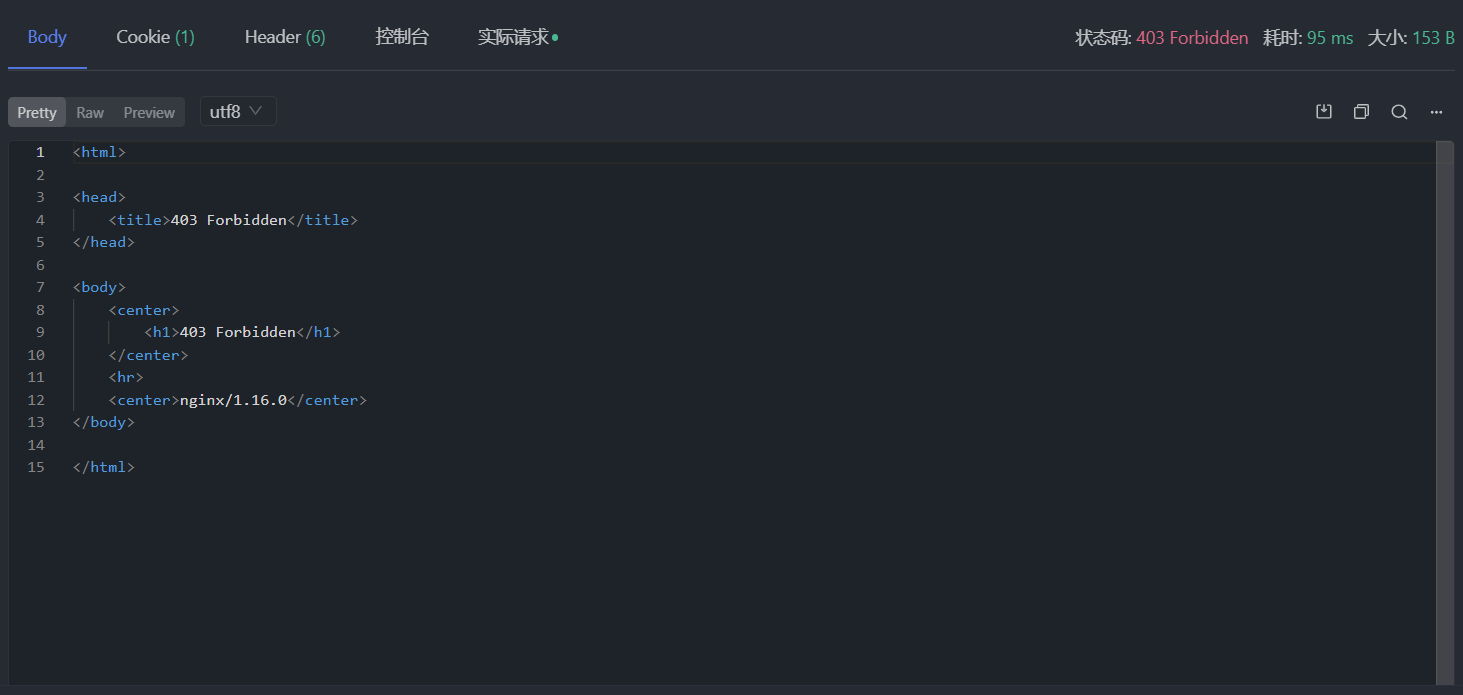
可以看到浏览器发出的请求的请求头中有设置 Referer 字段,把它加上,应该不会再报错了吧:
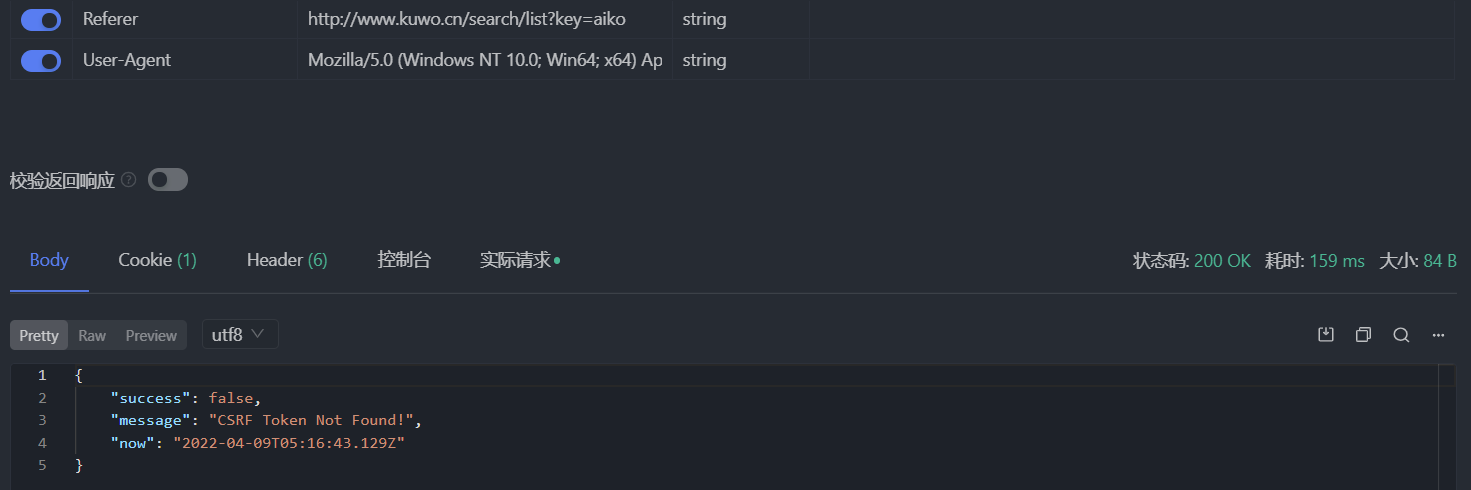
这次状态码为 200,但是没有收到任何数据,success 为 false 说明请求失败了,message 指明了失败原因是缺少 CSRF token。问题不大,接着把浏览器发出的请求中的 csrf 加到 Apifox 请求头中,再发请求,还是报错 CSRF token Invalid!。算了,还是老老实实把 Cookie 也加上吧,但也不是全部加上,只加 kw_token=CCISYM2HV96 部分,因为 Cookie 里面只有这个字段和 token 有关系且它的值和 csrf 相同。
在源代码面板按下 ctrl + shift + f,搜索一下 csrf,可以看到 csrf 本来就是来自 Object(h.b)("kw_token"),这个函数用来取出 document.cookie 中的 kw_token 字段值。至于 Cookie 中的 kw_token 怎么计算得到的,那就是服务器的事情了,咱们只管 CV 操作即可。
准备好参数和请求头,重新发送请求,可以得到想要的数据。如果去掉 reqId 参数,也可以拿到数据,但是会有略微的不同,这里就不贴出来了:
{
"code": 200,
"curTime": 1649482287185,
"data": {
"total": "741",
"list": [
{
"musicrid": "MUSIC_11690555",
"barrage": "0",
"ad_type": "",
"artist": "aiko",
"mvpayinfo": {
"play": 0,
"vid": 8530326,
"down": 0
},
"nationid": "0",
"pic": "http://img4.kuwo.cn/star/starheads/500/24/88/4146545084.jpg",
"isstar": 0,
"rid": 11690555,
"duration": 362,
"score100": "42",
"ad_subtype": "0",
"content_type": "0",
"track": 1,
"hasLossless": true,
"hasmv": 1,
"releaseDate": "1970-01-01",
"album": "",
"albumid": 0,
"pay": "16515324",
"artistid": 1907,
"albumpic": "http://img4.kuwo.cn/star/starheads/500/24/88/4146545084.jpg",
"originalsongtype": 0,
"songTimeMinutes": "06:02",
"isListenFee": false,
"pic120": "http://img4.kuwo.cn/star/starheads/120/24/88/4146545084.jpg",
"name": "恋をしたのは",
"online": 1,
"payInfo": {
"play": "1100",
"nplay": "00111",
"overseas_nplay": "11111",
"local_encrypt": "1",
"limitfree": 0,
"refrain_start": 89150,
"feeType": {
"song": "1",
"vip": "1"
},
"down": "1111",
"ndown": "11111",
"download": "1111",
"cannotDownload": 0,
"overseas_ndown": "11111",
"refrain_end": 126247,
"cannotOnlinePlay": 0
},
"tme_musician_adtype": "0"
}
]
},
"msg": "success",
"profileId": "site",
"reqId": "4b55cf4b0171253c33ce1d71b999c42f",
"tId": ""
}
请求代码
响应结果的 data 字段中有很多东西,这里只提取需要的部分。在提取之前先来定义一下歌曲信息实体类,这样在其他函数中要一首歌曲的信息时只要把实体类的实例传入即可。
# coding:utf-8
from copy import deepcopy
from dataclasses import dataclass
class Entity:
""" Entity abstract class """
def __setitem__(self, key, value):
self.__dict__[key] = value
def __getitem__(self, key):
return self.__dict__[key]
def get(self, key, default=None):
return self.__dict__.get(key, default)
def copy(self):
return deepcopy(self)
@dataclass
class SongInfo(Entity):
""" Song information """
file: str = None
title: str = None
singer: str = None
album: str = None
year: int = None
genre: str = None
duration: int = None
track: int = None
trackTotal: int = None
disc: int = None
discTotal: int = None
createTime: int = None
modifiedTime: int = None
上述代码显示定义了实体类的基类,并且重写了 __getitem__ 和 __setitem__ 魔法方法,这样我们可以像访问字典一样来访问实体类对象的属性。接着让歌曲信息实体类继承了实体类基类,并且使用 @dataclass 装饰器,这是 python 3.7 引入的新特性,使用它装饰之后的实体类无需实现构造函数、__str__等常用函数,python 会帮我们自动生成。
在发送请求的过程中可能会遇到各种异常,如果在代码里面写 try except 语句会显得很乱,这里同样可以用装饰器来解决这个问题。
# coding:utf-8
from copy import deepcopy
def exceptionHandler(*default):
""" decorator for exception handling
Parameters
----------
*default:
the default value returned when an exception occurs
"""
def outer(func):
def inner(*args, **kwargs):
try:
return func(*args, **kwargs)
except BaseException as e:
print(e)
value = deepcopy(default)
if len(value) == 0:
return None
elif len(value) == 1:
return value[0]
else:
return value
return inner
return outer
下面是发送获取歌曲信息请求的代码,使用 exception_handler 装饰了 getSongInfos 方法,这样发生异常时会打印异常信息并返回默认值:
# coding:utf-8
import json
from urllib import parse
from typing import List, Tuple
import requests
class KuWoMusicCrawler:
""" Crawler of KuWo Music """
def __init__(self):
super().__init__()
self.headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) '
'AppleWebKit/537.36 (KHTML, like Gecko) Chrome/71.0.3578.98 Safari/537.36',
'Cookie': 'kw_token=C713RK6IJ8J',
'csrf': 'C713RK6IJ8J',
'Host': 'www.kuwo.cn',
'Referer': ''
}
@exceptionHandler([], 0)
def getSongInfos(self, key_word: str, page_num=1, page_size=10) -> Tuple[List[SongInfo], int]:
key_word = parse.quote(key_word)
# configure request header
headers = self.headers.copy()
headers["Referer"] = 'http://www.kuwo.cn/search/list?key='+key_word
# send request for song information
url = f'http://www.kuwo.cn/api/www/search/searchMusicBykeyWord?key={key_word}&pn={page_num}&rn={page_size}&reqId=c06e0e50-fe7c-11eb-9998-47e7e13a7206'
response = requests.get(url, headers=headers)
response.raise_for_status()
# parse the response data
song_infos = []
data = json.loads(response.text)['data']
for info in data['list']:
song_info = SongInfo()
song_info['rid'] = info['rid']
song_info.title = info['name']
song_info.singer = info['artist']
song_info.album = info['album']
song_info.year = info['releaseDate'].split('-')[0]
song_info.track = info['track']
song_info.trackTotal = info['track']
song_info.duration = info["duration"]
song_info.genre = 'Pop'
song_info['coverPath'] = info.get('albumpic', '')
song_infos.append(song_info)
return song_infos, int(data['total'])
获取歌曲下载链接
免费歌曲
虽然我们实现了搜索歌曲的功能,但是没拿到每一首歌的播放地址,也就没办法把歌曲下载下来。我们先来播放一首不收费的歌曲试试。可以看到浏览器发送了一个获取播放链接的请求,路径为 http://www.kuwo.cn/api/v1/www/music/playUrl,有两个需要关注的参数:
mid:音乐 Id,此处的值为941583,和页面 url 中的编号一致,由于我们是通过点击搜索结果页面中二人跳转过来的,而二人这条结果也是动态加载出来的,超链接中的 Id 肯定也来自于上一节中响应结果的某个字段。二人是第四条记录,通过对比可以发现data.list[3].rid就是mid;type:音乐类型?此处的值为music,发送请求的时候也设置为music即可
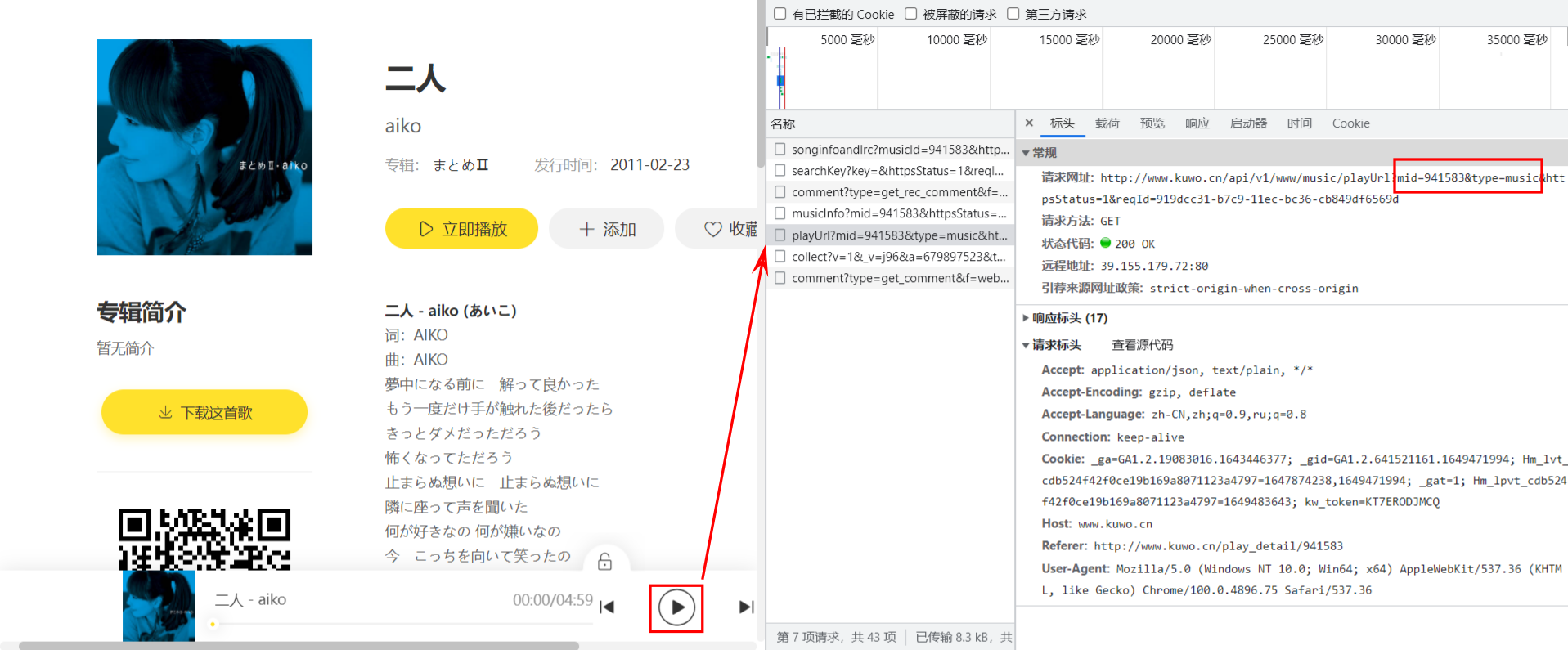
在 Apifox 中新建一个获取歌曲播放地址的请求,如下所示,发现可以成功拿到播放地址:

付费歌曲
现在换一首歌,比如 aiko - 横颜,点击歌曲页面上的播放按钮时会弹出要求在客户端中付费收听的对话框。直接发送请求,响应结果会是下面这个样子,状态码为 403:
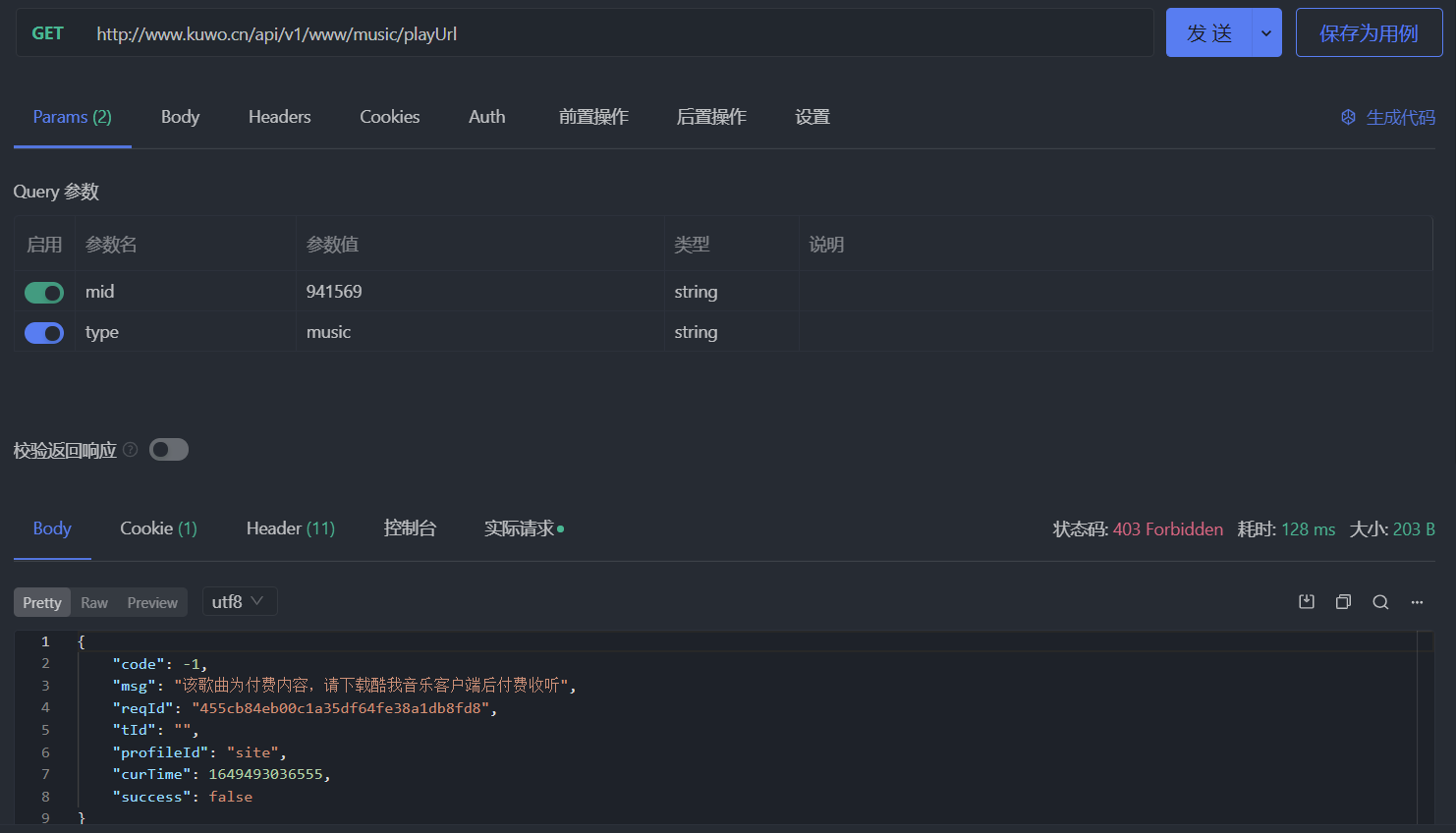
其实酷我在 2021 年 9 月份的时候换过获取播放地址的接口,那时候的请求接口为 http://www.kuwo.cn/url,支持以下几个参数:
format: 在线音乐的格式,可以是mp3type: 和现在的接口中的type参数一样,但是值为convert_url3rid: 音乐 Id,和mid一样br: 在线音乐的比特率,越大则音质越高,可选的有128kmp3、192kmp3和320kmp3
这个接口不管是付费音乐还是免费音乐都可以用。如果将现在这个接口的 type 参数的值换成 convert_url3,请求结果如下所示,说明成功了:
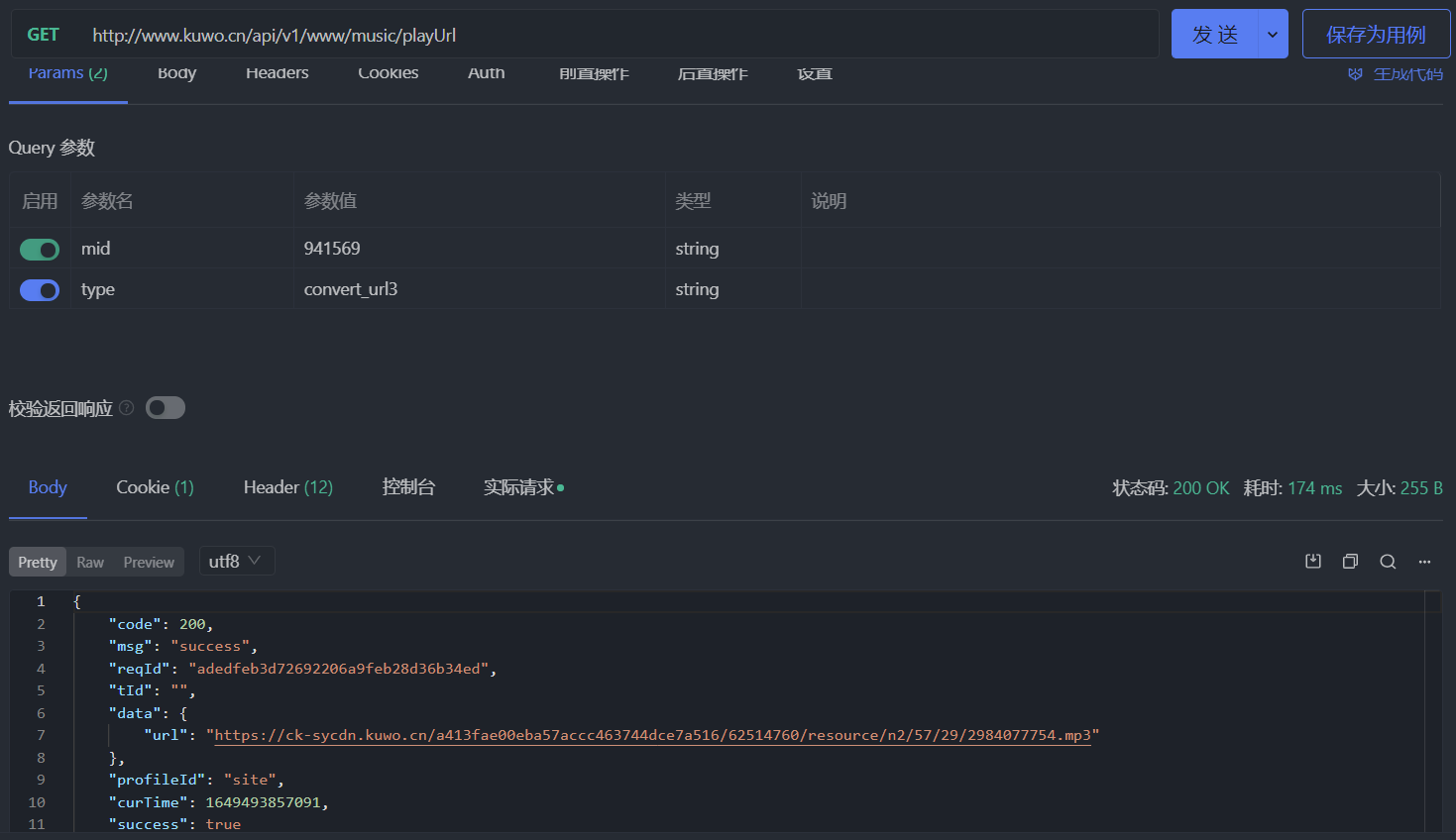
请求代码
下面是获取在线音乐播放链接的代码,只需调用 downloadSong 函数并把爬取到的歌曲传入就能完成歌曲的下载:
@exceptionHandler('')
def getSongUrl(self, song_info: SongInfo) -> str:
# configure request header
headers = self.headers.copy()
headers.pop('Referer')
headers.pop('csrf')
# send request for play url
url = f"http://www.kuwo.cn/api/v1/www/music/playUrl?mid={song_info['rid']}&type=convert_url3"
response = requests.get(url, headers=headers)
response.raise_for_status()
play_url = json.loads(response.text)['data']['url']
return play_url
@exceptionHandler('')
def downloadSong(self, song_info: SongInfo, save_dir: str) -> str:
# get play url
url = self.getSongUrl(song_info)
if not url:
return ''
# send request for binary data of audio
headers = self.headers.copy()
headers.pop('Referer')
headers.pop('csrf')
headers.pop('Host')
response = requests.get(url, headers=headers)
response.raise_for_status()
# save audio file
song_path = os.path.join(
save_dir, f"{song_info.singer} - {song_info.title}.mp3")
with open(song_path, 'wb') as f:
f.write(data)
return song
后记
除了获取歌曲的详细信息和播放地址外,我们还能拿到歌词、歌手信息等,方法是类似的,在我的 Groove 中提供了在线歌曲的功能,一部分接口就是来自酷我,还有一些来自酷狗和网易云,爬虫的代码在 app/common/crawler 目录下,喜欢的话可以给个 star 哦,以上~~
如何使用 python 爬取酷我在线音乐的更多相关文章
- python爬取酷狗音乐排行榜
本文为大家分享了python爬取酷狗音乐排行榜的具体代码,供大家参考,具体内容如下
- Python爬取网易云音乐歌手歌曲和歌单
仅供学习参考 Python爬取网易云音乐网易云音乐歌手歌曲和歌单,并下载到本地 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做 ...
- 用Python爬取网易云音乐热评
用Python爬取网易云音乐热评 本文旨在记录Python爬虫实例:网易云热评下载 由于是从零开始,本文内容借鉴于各种网络资源,如有侵权请告知作者. 要看懂本文,需要具备一点点网络相关知识.不过没有关 ...
- python爬取酷我音乐
我去!!!我之后一定按照搜索方式下载歌曲~~~~~~~~~ 1.首先打开我们本次主讲链接:http://www.kuwo.cn/ 2.刚开始我就随便点了一个地方,然后开始在后台找歌曲的链接地址.但是 ...
- python爬取网易云音乐歌曲评论信息
网易云音乐是广大网友喜闻乐见的音乐平台,区别于别的音乐平台的最大特点,除了“它比我还懂我的音乐喜好”.“小清新的界面设计”就是它独有的评论区了——————各种故事汇,各种金句频出.我们可以透过歌曲的评 ...
- python爬取酷我音乐(收费也可)
第一次创作,请多指教 环境:Python3.8,开发工具:Pycharm 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做案例的 ...
- python爬取网易云音乐歌单音乐
在网易云音乐中第一页歌单的url:http://music.163.com/#/discover/playlist/ 依次第二页:http://music.163.com/#/discover/pla ...
- python爬取酷狗音乐
url:https://www.kugou.com/yy/html/rank.html 我们随便访问一个歌曲可以看到url有个hash https://www.kugou.com/song/#hash ...
- 如何用Python网络爬虫爬取网易云音乐歌曲
今天小编带大家一起来利用Python爬取网易云音乐,分分钟将网站上的音乐down到本地. 跟着小编运行过代码的筒子们将网易云歌词抓取下来已经不再话下了,在抓取歌词的时候在函数中传入了歌手ID和歌曲名两 ...
随机推荐
- Net之多线程用法
1.多线程 2.线程池 3.Task using System; using System.Collections.Generic; using System.Linq; using System.T ...
- 『现学现忘』Docker基础 — 28、Docker容器数据卷介绍
目录 1.什么是Docker容器数据卷 2.数据卷的作用 3.数据卷的使用 1.什么是Docker容器数据卷 Docker容器数据卷,即Docker Volume(卷). 当Docker容器运行的时候 ...
- Arch Linux 系统迁移
镜像下载.域名解析.时间同步请点击 阿里巴巴开源镜像站 备份 Arch Linux 系统 安装 pigz 使用 pigz 多线程压缩比使用 tar 单线程压缩速度明显提升多倍 sudo pacman ...
- PMP之挣值管理(PV、EV、AC、SV、CV、SPI、CPI)的记忆方法
挣值管理法中的PV.EV.AC.SV.CV.SPI.CPI这些英文简写相信把大家都搞得晕头转向的.在挣值管理法中,需要记忆理解的有三个参数:PV.AC.EV. PV:计划值,在即定时间点前计划完成活动 ...
- linux mac 命令行 远程连接ssh提示IT IS POSSIBLE THAT SOMEONE IS DOING SOMETHING NASTY解决
➜ ~ ssh adleytales@192.168.1.10 @@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@@ @ WARNIN ...
- 嵌套OOPS导致系统卡死 每个CPU都上报softlockup的问题
问题现象:在ARM服务器上,构造oops异常,本应该产生panic,进入dump流程,并且系统重启,但是系统并未重启,而是出现了卡死,在串口会隔一段时间就循环打印调用栈信息.如下所示 linux-fA ...
- Java基础——方法的调用
Java基础--方法的调用 总结: 1. 在同一个类中-- 对于静态方法,其他的静态和非静态方法都可以直接通过"方法名"或者"类名.方法名"调用它. 对 ...
- bzoj4241/AT1219 历史研究(回滚莫队)
bzoj4241/AT1219 历史研究(回滚莫队) bzoj它爆炸了. luogu 题解时间 我怎么又在做水题. 就是区间带乘数权众数. 经典回滚莫队,一般对于延长区间简单而缩短区间难的莫队题可以考 ...
- dfs:10元素取5个元素的组合数
#include "iostream.h" #include "string.h" #include "stdlib.h" int sele ...
- Java Byte不能用equals