【十大经典数据挖掘算法】k-means
【十大经典数据挖掘算法】系列
1. 引言
k-means与kNN虽然都是以k打头,但却是两类算法——kNN为监督学习中的分类算法,而k-means则是非监督学习中的聚类算法;二者相同之处:均利用近邻信息来标注类别。
聚类是数据挖掘中一种非常重要的学习流派,指将未标注的样本数据中相似的分为同一类,正所谓“物以类聚,人以群分”嘛。k-means是聚类算法中最为简单、高效的,核心思想:由用户指定k个初始质心(initial centroids),以作为聚类的类别(cluster),重复迭代直至算法收敛。
2. 基本算法
在k-means算法中,用质心来表示cluster;且容易证明k-means算法收敛等同于所有质心不再发生变化。基本的k-means算法流程如下:
选取k个初始质心(作为初始cluster);
repeat:
对每个样本点,计算得到距其最近的质心,将其类别标为该质心所对应的cluster;
重新计算k个cluser对应的质心;
until 质心不再发生变化
对于欧式空间的样本数据,以平方误差和(sum of the squared error, SSE)作为聚类的目标函数,同时也可以衡量不同聚类结果好坏的指标:
\]
表示样本点\(x\)到cluster \(C_i\) 的质心 \(c_i\) 距离平方和;最优的聚类结果应使得SSE达到最小值。
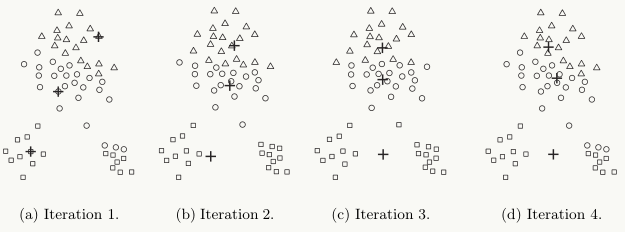
下图中给出了一个通过4次迭代聚类3个cluster的例子:

k-means存在缺点:
k-means是局部最优的,容易受到初始质心的影响;比如在下图中,因选择初始质心不恰当而造成次优的聚类结果(SSE较大):
同时,k值的选取也会直接影响聚类结果,最优聚类的k值应与样本数据本身的结构信息相吻合,而这种结构信息是很难去掌握,因此选取最优k值是非常困难的。
3. 优化
为了解决上述存在缺点,在基本k-means的基础上发展而来二分 (bisecting) k-means,其主要思想:一个大cluster进行分裂后可以得到两个小的cluster;为了得到k个cluster,可进行k-1次分裂。算法流程如下:
初始只有一个cluster包含所有样本点;
repeat:
从待分裂的clusters中选择一个进行二元分裂,所选的cluster应使得SSE最小;
until 有k个cluster
上述算法流程中,为从待分裂的clusters中求得局部最优解,可以采取暴力方法:依次对每个待分裂的cluster进行二元分裂(bisect)以求得最优分裂。二分k-means算法聚类过程如图:

从图中,我们观察到:二分k-means算法对初始质心的选择不太敏感,因为初始时只选择一个质心。
4. 参考资料
[1] Pang-Ning Tan, Michael Steinbach, Vipin Kumar, Introduction to Data Mining.
[2] Xindong Wu, Vipin Kumar, The Top Ten Algorithms in Data Mining.
【十大经典数据挖掘算法】k-means的更多相关文章
- 【十大经典数据挖掘算法】k
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 引言 k-means与kNN虽 ...
- 【十大经典数据挖掘算法】PageRank
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 我特地把PageRank作为[十大经 ...
- 【十大经典数据挖掘算法】SVM
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART SVM(Support Vector ...
- 【十大经典数据挖掘算法】Naïve Bayes
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 朴素贝叶斯(Naïve Bayes) ...
- 【十大经典数据挖掘算法】C4.5
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 决策树模型与学习 决策树(de ...
- 【十大经典数据挖掘算法】Apriori
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 关联分析 关联分析是一类非常有 ...
- 【十大经典数据挖掘算法】kNN
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 引言 顶级数据挖掘会议ICDM ...
- 【十大经典数据挖掘算法】CART
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 前言 分类与回归树(Class ...
- 【十大经典数据挖掘算法】EM
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 极大似然 极大似然(Maxim ...
随机推荐
- 用jquery实现瀑布流案例
一.瀑布流是我们常见的案例,这里主要讲述,用jquery的方式实现瀑布流的功能! 引言:我们经常见到很多网站的瀑布流功能,如淘宝.京东这些商品等等.. 实现它我们首先考虑几个问题:1.获取到数据 ...
- 【实战Java高并发程序设计6】挑战无锁算法:无锁的Vector实现
[实战Java高并发程序设计 1]Java中的指针:Unsafe类 [实战Java高并发程序设计 2]无锁的对象引用:AtomicReference [实战Java高并发程序设计 3]带有时间戳的对象 ...
- gdb调试工具vi编译器命令参考网址
vi编译器命令:参考http://www.cnblogs.com/junw_china/articles/1708967.html gbd调试命令:参考http://blog.chinaunix.ne ...
- Android动画
[浅谈Android动画] 总共四种:Tween Animation变换动画.Frame Animation帧动画 Layout Animation布局动画.Property Animation 属性 ...
- 《.NET之美》消息及勘误
<.NET之美>消息及勘误 编辑最终还是采用了<.NET之美>作为书名,尽管我一直觉得这个名字有点文艺了,而更倾向于使用<.NET专题解析>这个名称. 目前已经可以 ...
- SQL Server 2016 CTP2.2 安装手记
SQL Server 2016 CTP2.2 安装手记 下载一个iso文件,解压出来(大约2.8G左右),在该路径下双击Setup.exe即可开始安装. 安装之前请先安装.NET 3.5 SP1,在服 ...
- JavaScript面向对象之我见
序言 在JavaScript的大世界里讨论面向对象,都要提到两点:1.JavaScript是一门基于原型的面向对象语言 2.模拟类语言的面向对象方式.对于为什么要模拟类语言的面向对象,我个人认为:某些 ...
- C# Random生成多个不重复的随机数万能接口
C#,Radom.Next()提供了在一定范围生成一个随机数的方法,我现在有个业务场景是给其他部门推送一些数据供他们做抽样检查处理,假设我的数据库里面有N条数据,现在要定期给其随机推送数据,我需要先拿 ...
- 过段时间逐步使用HTML5新增的web worker等内容
想来快2017年了,2013年前的手机应该很少有人用了,以后逐渐使用HTML5新增的高级API吧. 先把web worker的内容再熟悉一下,因为微软虚拟学院的'面向有经验开发人员的 JavaScri ...
- 《第一本docker书》—— 读后总结
关于docker 这本书其实并没有读完,只不过最近工作比较繁忙,也无心再看这些用不到的书.以后要是工作需要,再仔细学习吧. 这次的阅读算是达到目的了,对docker有了一定的了解.它的作用.意义以及大 ...