【十大经典数据挖掘算法】k
【十大经典数据挖掘算法】系列
1. 引言
k-means与kNN虽然都是以k打头,但却是两类算法——kNN为监督学习中的分类算法,而k-means则是非监督学习中的聚类算法;二者相同之处:均利用近邻信息来标注类别。
聚类是数据挖掘中一种非常重要的学习流派,指将未标注的样本数据中相似的分为同一类,正所谓“物以类聚,人以群分”嘛。k-means是聚类算法中最为简单、高效的,核心思想:由用户指定k个初始质心(initial centroids),以作为聚类的类别(cluster),重复迭代直至算法收敛。
2. 基本算法
在k-means算法中,用质心来表示cluster;且容易证明k-means算法收敛等同于所有质心不再发生变化。基本的k-means算法流程如下:
选取k个初始质心(作为初始cluster);
repeat:
对每个样本点,计算得到距其最近的质心,将其类别标为该质心所对应的cluster;
重新计算k个cluser对应的质心;
until 质心不再发生变化对于欧式空间的样本数据,以平方误差和(sum of the squared error, SSE)作为聚类的目标函数,同时也可以衡量不同聚类结果好坏的指标:
SSE=k∑i=1∑x∈Cidist(x,ci)
表示样本点x到cluster Ci 的质心 ci 距离平方和;最优的聚类结果应使得SSE达到最小值。
下图中给出了一个通过4次迭代聚类3个cluster的例子:
k-means存在缺点:
k-means是局部最优的,容易受到初始质心的影响;比如在下图中,因选择初始质心不恰当而造成次优的聚类结果(SSE较大):
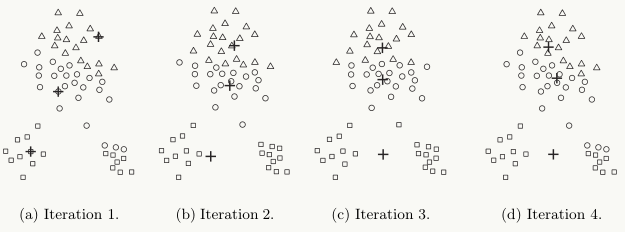
同时,k值的选取也会直接影响聚类结果,最优聚类的k值应与样本数据本身的结构信息相吻合,而这种结构信息是很难去掌握,因此选取最优k值是非常困难的。
3. 优化
为了解决上述存在缺点,在基本k-means的基础上发展而来二分 (bisecting) k-means,其主要思想:一个大cluster进行分裂后可以得到两个小的cluster;为了得到k个cluster,可进行k-1次分裂。算法流程如下:
初始只有一个cluster包含所有样本点;
repeat:
从待分裂的clusters中选择一个进行二元分裂,所选的cluster应使得SSE最小;
until 有k个cluster上述算法流程中,为从待分裂的clusters中求得局部最优解,可以采取暴力方法:依次对每个待分裂的cluster进行二元分裂(bisect)以求得最优分裂。二分k-means算法聚类过程如图:
从图中,我们观察到:二分k-means算法对初始质心的选择不太敏感,因为初始时只选择一个质心。
4. 参考资料
[1] Pang-Ning Tan, Michael Steinbach, Vipin Kumar, Introduction to Data Mining.
[2] Xindong Wu, Vipin Kumar, The Top Ten Algorithms in Data Mining.
【十大经典数据挖掘算法】k的更多相关文章
- 【十大经典数据挖掘算法】PageRank
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 我特地把PageRank作为[十大经 ...
- 【十大经典数据挖掘算法】SVM
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART SVM(Support Vector ...
- 【十大经典数据挖掘算法】Naïve Bayes
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 朴素贝叶斯(Naïve Bayes) ...
- 【十大经典数据挖掘算法】C4.5
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 决策树模型与学习 决策树(de ...
- 【十大经典数据挖掘算法】k-means
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 引言 k-means与kNN虽 ...
- 【十大经典数据挖掘算法】Apriori
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 关联分析 关联分析是一类非常有 ...
- 【十大经典数据挖掘算法】kNN
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 引言 顶级数据挖掘会议ICDM ...
- 【十大经典数据挖掘算法】CART
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 前言 分类与回归树(Class ...
- 【十大经典数据挖掘算法】EM
[十大经典数据挖掘算法]系列 C4.5 K-Means SVM Apriori EM PageRank AdaBoost kNN Naïve Bayes CART 1. 极大似然 极大似然(Maxim ...
随机推荐
- linux系统df和du命令的区别
发现一台用户的电脑,df检查出来的/磁盘空间占用了16G,比用du查看得到的磁盘空间大的多,du查看/下所有程序目录加起来还不到5G.这是什么原因呢? 即便是有隐藏文件,查了也很小啊. 因为df和 ...
- MappedByteBuffer以及ByteBufer的底层原理
最近在用java中的ByteBuffer,一直不明所以,尤其是对MappedByteBuffer使用的内存映射这个概念云里雾里. 于是首先补了物理内存.虚拟内存.页面文件.交换区的只是:小科普——物理 ...
- 【AtCoder】ARC086 E - Smuggling Marbles
[题目]E - Smuggling Marbles [题意]给定n+1个点的树(root=0),每个点可以选择放或不放弹珠,每一轮顺序进行以下操作: 1.将根节点0的弹珠加入答案. 2.每个点的弹珠移 ...
- 爬虫--Scrapy框架的基本使用
流程框架 安装Scrapy: (1)在pycharm里直接就可以进行安装Scrapy (2)若在conda里安装scrapy,需要进入cmd里输入指令conda install scrapy ...
- F - Debate CodeForces - 1070F 思维
题目链接:https://vjudge.net/problem/CodeForces-1070F 具体思路:首先把所有的00放进去,然后对于10 和01 的取两个数目最小值t,排完序后将前t个加起来, ...
- python 第二章 对象与类型
可变对象和不可变对象 1,可变对象,list(列表),dict(字典),集合(set),字节数组. 2,不可变对象,数值类型,字符串,字节串,元组(具体形式 ()). 注意条件:可变和不可变指的是该对 ...
- .NET Framework 4安装失败
#刚装系统遇到之前所遇到的问题.之前因为这个事情还被困扰了好一阵子.特此写出来分享给大家. 环境:WIN10 企业版 在使用一些需要较高.net版本的时候无法更新.你可以试一下.在服务里面开启再更新. ...
- SQLite3 C/C++ 开发接口简介(API函数)
from : http://www.sqlite.com.cn/MySqlite/5/251.Html 1.0 总览 SQLite3是SQLite一个全新的版本,它虽然是在SQLite 2.8.13的 ...
- python批量替换文件名
替换关键字 #-*-coding:utf-8-*- import os import re filepath = u'E:\\CMMI4\\07_测试文档' files = os.walk(filep ...
- 安装 Xamarin for Visual Studio
总得来说,Xamarin 有“联网自动安装”和“手动安装”两种方式. 说明:本文涉及得资源链接都是官网的,同时,在 我的网盘 也有相关备份. 现在,我就以 Windows 为例来大概说明……(-=-我 ...