Python数据分析I
Python数据分析概述
数据分析的含义与目标
统计分析方法
提取有用信息
研究、概括、总结
Python与数据分析
Python: Guido Van Rossum Christmas Holiday, 1989
特点:简介 开发效率搞 运算速度慢(相对于C++和Java) 胶水特性(集成C语言)
数据分析:numpy、scipy、matplotlib、pandas、scikit-learn、keras
Python数据分析大家族
numpy(Numeric Python): 数据结构基础。是Python的一种开源的数值计算扩展。这种工具可用来存储和处理大型矩阵,比Python自身的嵌套列表(nested list structure)结构要高效的多(该结构也可以用来表示矩阵(matrix))。据说NumPy将Python相当于变成一种免费的更强大的MatLab系统。
scipy: 强大的科学计算方法(矩阵分析、信号和图像分析、数理分析……)
matplotlib: 丰富的可视化套件
pandas: 基础数据分析套件。该工具是为了解决数据分析任务而创建的。Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具。pandas提供了大量能使我们快速便捷地处理数据的函数和方法。Pandas最初被作为金融数据分析工具而开发出来,因此,pandas为时间序列分析提供了很好的支持。 Pandas的名称来自于面板数据(panel data)和python数据分析(data analysis)。
scikit-learn: 强大的数据分析建模库
keras: (深度)人工神经网络
Python环境搭建
平台:Windows、Linux、MacOS
科学计算工具:Anaconda
Python数据分析基础技术
I. numpy
关键词: 开源 数据计算扩展
功能: ndarray 多维操作 线性代数
ndarray
#encoding=utf-8
import numpy as np
def main():
lst=[[1,2,3],[2,4,6]]
print(type(lst))
np_lst=np.array(lst)
print(type(lst))
np_lst=np.array(lst,dtype=np.float)
# bool
# int,int8,int16,int32,int64,int128
# uint8,uint16,uint32,uint64,uint128,
# float16/32/64,complex64/128
print(np_lst.shape) # 行列数
print(np_lst.ndim) # 维数
print(np_lst.dtype) # 数据类型
print(np_lst.itemsize) # 每个数据的数据存储大小
print(np_lst.size) # 元素个数
some kinds of array
#encoding=utf-8
import numpy as np
def main():
print(np.zeros([2, 4]))
print(np.ones([3, 5]))
print("Rand:")
print(np.random.rand()) # 0-1内均匀分布随机数
print(np.random.rand(2, 4))
print("RandInt:")
print(np.random.randint(1, 10, 3)) # 3个1-10内随机分布整数
print("Randn:")
print(np.random.randn(2, 4)) # 标准正态随机数
print("Choice:")
print(np.random.choice([10, 20, 30])) # 指定范围内的随机数
print("Distribute:")
print(np.random.beta(1, 10, 100)) # 比如Beta分布,Dirichlet分布etc
opeartion
#encoding=utf-8
import numpy as np
def main():
print(np.arange(1, 11).reshape([2, 5]))
lst = np.arange(1, 11).reshape([2, 5])
print("Exp:")
print(np.exp(lst))
print("Exp2:")
print(np.exp2(lst))
print("Sqrt:")
print(np.sqrt(lst))
print("Sin:")
print(np.sin(lst))
print("Log:")
print(np.log(lst))
lst = np.array([[[1, 2, 3, 4],
[4, 5, 6, 7]],
[[7, 8, 9, 10],
[10, 11, 12, 13]],
[[14, 15, 16, 17],
[18, 19, 20, 21]]
])
print(lst)
print("Sum:")
print(lst.sum()) # 所有元素求和
print(lst.sum(axis=0)) # 最外层求和
print(lst.sum(axis=1)) # 第二层求和
print(lst.sum(axis=-1)) # 最里层求和
print("Max:")
print(lst.max())
print("Min:")
print(lst.min())
lst1 = np.array([10, 20, 30, 40])
lst2 = np.array([4, 3, 2, 1])
print("Add:")
print(lst1 + lst2)
print("Sub:")
print(lst1 - lst2)
print("Mul:")
print(lst1 * lst2)
print("Div:")
print(lst1 / lst2)
print("Square:")
print(lst1 ** lst2)
print("Dot:")
print(np.dot(lst1.reshape([2, 2]), lst2.reshape([2, 2])))
print("Cancatenate")
print(np.concatenate((lst1, lst2), axis=0))
print(np.vstack((lst1, lst2))) # 按照行拼接
print(np.hstack((lst1, lst2))) # 按照列拼接
print(np.split(lst1, 2)) # 向量拆分
print(np.copy(lst1)) # 向量拷贝
liner algebra
#encoding=utf-8
import numpy as np
from numpy.linalg import *
def main():
## Liner
print(np.eye(3))
lst = np.array([[1, 2],
[3, 4]])
print("Inv:")
print(inv(lst))
print("T:")
print(lst.transpose())
print("Det:")
print(det(lst))
print("Eig:")
print(eig(lst))
y = np.array([[5], [7]])
print("Solve")
print(solve(lst, y))
others
#encoding=utf-8
import numpy as np
def main():
## Other
print("FFT:")
print(np.fft.fft(np.array([1, 1, 1, 1, 1, 1, 1, 1, 1])))
print("Coef:")
print(np.corrcoef([1, 0, 1], [0, 2, 1]))
print("Poly:")
print(np.poly1d([2, 1, 3])) #一元多次方程
II. matplotlib
关键词: 绘图库
Line
#encoding=utf-8
import numpy as np
import matplotlib.pyplot as plt
def Main():
## line
x = np.linspace(-np.pi, np.pi, 256, endpoint=True)
c, s = np.cos(x), np.sin(x)
plt.plot(x, c)
plt.figure(1)
plt.plot(x, c, color="blue", linewidth=1.5, linestyle="-", label="COS", alpha=0.6)
plt.plot(x, s, "r*", label="SIN", alpha=0.6)
plt.title("Cos & Sin", size=16)
ax = plt.gca() # 轴编辑器
ax.spines["right"].set_color("none")
ax.spines["top"].set_color("none")
ax.spines["left"].set_position(("data", 0))
ax.spines["bottom"].set_position(("data", 0))
ax.xaxis.set_ticks_position("bottom")
ax.yaxis.set_ticks_position("left")
plt.xticks([-np.pi, -np.pi/2, 0, np.pi/2, np.pi], [r'$-\pi$', r'$-\pi/2$', r'$0$', r'$\pi/2$', r'$\pi$']) # 正则表达
plt.yticks(np.linspace(-1, 1, 5, endpoint=True))
for label in ax.get_xticklabels()+ax.get_yticklabels():
label.set_fontsize(16)
label.set_bbox(dict(facecolor="white", edgecolor="none", alpha=0.2))
plt.legend(loc="upper left")
plt.grid()
# plt.axis([-2, 1, -0.5, 1])
# fill:填充
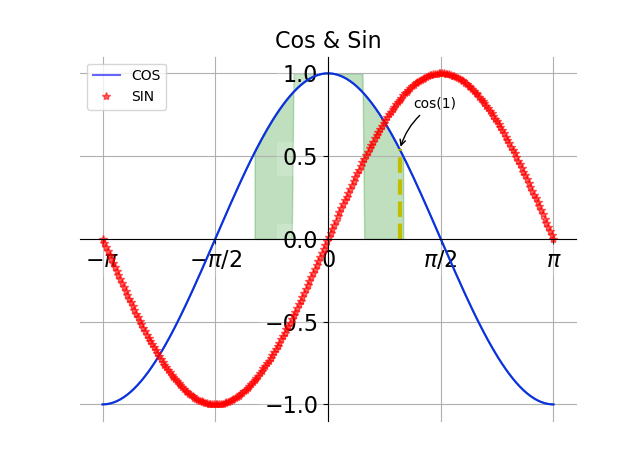
plt.fill_between(x, np.abs(x) < 0.5, c, c > 0.5, color="green", alpha=0.25)
t = 1
plt.plot([t, t], [0, np.cos(t)], "y", linewidth=3, linestyle="--")
plt.annotate("cos(1)", xy=(t, np.cos(1)), xycoords="data", xytext=(+10, +30),textcoords="offset points", arrowprops=dict(arrowstyle="->", connectionstyle="arc3,rad=.2"))
plt.fill_between(x, np.abs(x) < 0.5, c, c > 0.5, color="green", alpha=0.25)
第一个参数x表示x轴,第二个参数 np.abs(x)表示x的绝对值,np.abs(x) < 0.5是一个判定变量,c表示y轴,c > 0.5是一个判定条件。
当np.abs(x) < 0.5为真(1),从y轴的1(满足c>0.5)开始往两边填充(当然X轴上是-0.5到0.5之间的区域),此时填充的也就是图上方的两小块。当np.abs(x) >= 0.5为假(0),从y轴的0开始向上填充,当然只填充c>0.5的区域,也就是图中那两个大的对称区域。
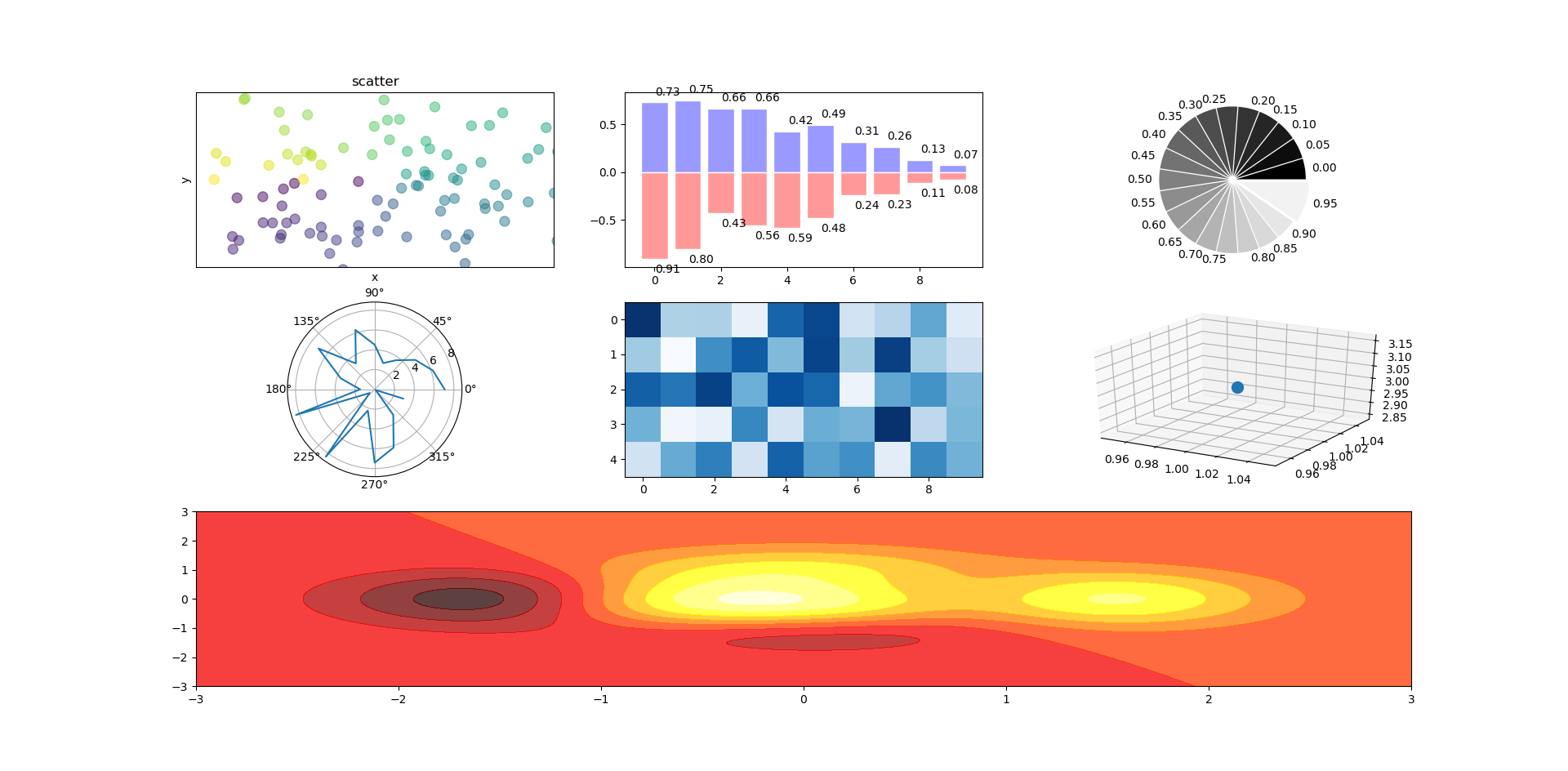
Many types of figures
#encoding=utf-8
import numpy as np
import matplotlib.pyplot as plt
def Main():
fig = plt.figure()
## scatter
ax = fig.add_subplot(3, 3, 1)
n = 128
X = np.random.normal(0, 1, n)
Y = np.random.normal(0, 1, n)
T = np.arctan2(Y, X)
# plt.axes([0.025, 0.025, 0.95, 0.95])
plt.scatter(X, Y, s=75, c=T, alpha=.5)
plt.xlim(-1.5, 1.5), plt.xticks([])
plt.ylim(-1.5, 1.5), plt.yticks([])
plt.axis()
plt.title("scatter")
plt.xlabel("x")
plt.ylabel("y")
## bar
fig.add_subplot(332)
n = 10
X = np.arange(n)
Y1 = (1 - X / float(n)) * np.random.uniform(0.5, 1, n)
Y2 = (1 - X / float(n)) * np.random.uniform(0.5, 1, n)
plt.bar(X, +Y1, facecolor='#9999ff', edgecolor='white')
plt.bar(X, -Y2, facecolor='#ff9999', edgecolor='white')
for x, y in zip(X,Y1):
plt.text(x + 0.4, y + 0.05, '%.2f' % y, ha='center', va='bottom')
for x, y in zip(X,Y2):
plt.text(x + 0.4, - y - 0.05, '%.2f' % y, ha='center', va='top')
## Pie
fig.add_subplot(333)
n = 20
Z = np.ones(n)
Z[-1] *= 2
# explode扇形离中心距离
plt.pie(Z, explode=Z*.05, colors=['%f' % (i / float(n)) for i in range(n)],
labels=['%.2f' % (i / float(n)) for i in range(n)])
plt.gca().set_aspect('equal') # 圆形
plt.xticks([]), plt.yticks([])
## polar
fig.add_subplot(334, polar=True)
n = 20
theta = np.arange(0, 2 * np.pi, 2 * np.pi / n)
radii = 10 * np.random.rand(n)
plt.polar(theta, radii)
# plt.plot(theta, radii)
## heatmap
fig.add_subplot(335)
from matplotlib import cm
data = np.random.rand(5, 10)
cmap = cm.Blues
map = plt.imshow(data, interpolation='nearest', cmap=cmap, aspect='auto', vmin=0, vmax=1)
## 3D
from mpl_toolkits.mplot3d import Axes3D
ax = fig.add_subplot(336, projection="3d")
ax.scatter(1, 1, 3, s=100)
## hot map
fig.add_subplot(313)
def f(x, y):
return (1 - x / 2 + x ** 5 + y ** 3) * np.exp(- x ** 2 - y ** 2)
n = 256
x = np.linspace(-3, 3, n * 2)
y = np.linspace(-3, 3, n)
X, Y = np.meshgrid(x, y)
plt.contourf(X, Y, f(X, Y), 8, alpha=.75, cmap=plt.cm.hot)
plt.savefig("./data/fig.png")
plt.show()
Python数据分析I的更多相关文章
- [Python数据分析]新股破板买入,赚钱几率如何?
这是本人一直比较好奇的问题,网上没搜到,最近在看python数据分析,正好自己动手做一下试试.作者对于python是零基础,需要从头学起. 在写本文时,作者也没有完成这个小分析目标,边学边做吧. == ...
- 【Python数据分析】Python3多线程并发网络爬虫-以豆瓣图书Top250为例
基于上两篇文章的工作 [Python数据分析]Python3操作Excel-以豆瓣图书Top250为例 [Python数据分析]Python3操作Excel(二) 一些问题的解决与优化 已经正确地实现 ...
- 【Python数据分析】Python3操作Excel(二) 一些问题的解决与优化
继上一篇[Python数据分析]Python3操作Excel-以豆瓣图书Top250为例 对豆瓣图书Top250进行爬取以后,鉴于还有一些问题没有解决,所以进行了进一步的交流讨论,这期间得到了一只尼玛 ...
- 【搬砖】【Python数据分析】Pycharm中plot绘图不能显示出来
最近在看<Python数据分析>这本书,而自己写代码一直用的是Pycharm,在练习的时候就碰到了plot()绘图不能显示出来的问题.网上翻了一下找到知乎上一篇回答,试了一下好像不行,而且 ...
- Python 数据分析(二 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识
Python 数据分析(二) 本实验将学习利用 Python 数据聚合与分组运算,时间序列,金融与经济数据应用等相关知识 第1节 groupby 技术 第2节 数据聚合 第3节 分组级运算和转换 第4 ...
- Python数据分析(二): Numpy技巧 (1/4)
In [1]: import numpy numpy.__version__ Out[1]: '1.13.1' In [2]: import numpy as np
- Python数据分析(二): Numpy技巧 (2/4)
numpy.pandas.matplotlib(+seaborn)是python数据分析/机器学习的基本工具. numpy的内容特别丰富,我这里只能介绍一下比较常见的方法和属性. 昨天晚上发了第一 ...
- Python数据分析(二): Numpy技巧 (3/4)
numpy.pandas.matplotlib(+seaborn)是python数据分析/机器学习的基本工具. numpy的内容特别丰富,我这里只能介绍一下比较常见的方法和属性. 昨天晚上发了第一 ...
- Python数据分析(二): Numpy技巧 (4/4)
numpy.pandas.matplotlib(+seaborn)是python数据分析/机器学习的基本工具. numpy的内容特别丰富,我这里只能介绍一下比较常见的方法和属性. 第一部分: ht ...
- 【读书笔记与思考】《python数据分析与挖掘实战》-张良均
[读书笔记与思考]<python数据分析与挖掘实战>-张良均 最近看一些机器学习相关书籍,主要是为了拓宽视野.在阅读这本书前最吸引我的地方是实战篇,我通读全书后给我印象最深的还是实战篇.基 ...
随机推荐
- 在VMware下的Linux中的RAID10校验位算法下的磁盘管理
988年由加利福尼亚大学伯克利分校发表的文章首次提到并定义了RAID,当今CPU性能每年可提升30%-50%但硬盘仅提升7%,渐渐的已经成为计算机整体性能的瓶颈,并且为了避免硬盘的突然损坏导致数据丢失 ...
- [考试反思]0921csp-s模拟测试49:困顿
太弱.还是太弱. 拉不开分差,离第一机房分数线估计还是300多分. 但是,还是要骂:XX出题人. 部分分非常少且没有意义,T1基本只有0/纯暴力20/100三个档, T2正解是n2但是n3一分不给,还 ...
- javascript 作用域链及性能优化
在JavaScript中,函数也是对象,实际上,JavaScript里一切都是对象.函数对象和其它对象一样,拥有可以通过代码访问的属性和一系列仅供JavaScript引擎访问的内部属性.其中一个内部属 ...
- 05 MySQL之查询、插入、更新与删除
01-查询数据 语法格式: select * | 字段列表 from 表1, 表2 where 表达式 group by ... having ... order by ... limit .. # ...
- 树上神奇 逆 逆序对(我的叫法)hh的小纸条 重中之重!!!!!
HH是一位十分爱好数学的大佬,尤其喜爱数数,一天百无聊赖的他写下了一个1-N的排列,并且在小纸条上记下了每个数前面有多少个数比他小,但HH不小心忘记了这个排列.现在只有当时记下的小纸条,现在请你还原出 ...
- tarjan学习(复习)笔记(持续更新)(各类找环模板)
题目背景 缩点+DP 题目描述 给定一个n个点m条边有向图,每个点有一个权值,求一条路径,使路径经过的点权值之和最大.你只需要求出这个权值和. 允许多次经过一条边或者一个点,但是,重复经过的点,权值只 ...
- python 爬取豆瓣书籍信息
继爬取 猫眼电影TOP100榜单 之后,再来爬一下豆瓣的书籍信息(主要是书的信息,评分及占比,评论并未爬取).原创,转载请联系我. 需求:爬取豆瓣某类型标签下的所有书籍的详细信息及评分 语言:pyth ...
- PHP 在Swoole中使用双IoC容器实现无污染的依赖注入
简介: 容器(container)技术(可以理解为全局的工厂方法), 已经是现代项目的标配. 基于容器, 可以进一步实现控制反转, 依赖注入. Laravel 的巨大成功就是构建在它非常强大的IoC容 ...
- MathType转Word公式(OMML)
背景 由于之前个人喜欢在Word里做笔记,而有很多笔记里存在着大量的公式.在早期,由于对Word自身的公式的不理解,所以便使用了MathType这个工具来编写公式.但是现在本人已经转战到LatTeX了 ...
- [LC]747题 Largest Number At Least Twice of Others (至少是其他数字两倍的最大数)
①中文题目 在一个给定的数组nums中,总是存在一个最大元素 . 查找数组中的最大元素是否至少是数组中每个其他数字的两倍. 如果是,则返回最大元素的索引,否则返回-1. 示例 1: 输入: nums ...