Python爬虫 爬取Web页面图片
从网页页面上批量下载jpg格式图片,并按照数字递增命名保存到指定的文件夹
Web地址:http://news.weather.com.cn/2017/12/2812347.shtml
打开网页,点击F12查看

代码实现:
import urllib
import urllib.request
import re #解析页面
def load_page(url):
request=urllib.request.Request(url) #发送网络请求
response=urllib.request.urlopen(request) #根据url打开页面
data=response.read() #获取页面响应数据
return data #下载图片
def get_image(html):
regx=r'http://[\S]*jpg' #定义正则表达式
pattern=re.compile(regx) #编译表达式构造匹配模式
get_image=re.findall(pattern,repr(html)) #进行正则匹配并返回结果 num = 1
#遍历获取的图片
for img in get_image:
image=load_page(img)
#将图片存入到指定文件夹
with open('E:\\Photo\\%s.jpg' %num,'wb') as fb:
fb.write(image)
print("正在下载第%s张图片" %num)
num = num + 1
print("下载完成!") url='http://news.weather.com.cn/2017/12/2812347.shtml'
html=load_page(url)
get_image(html)
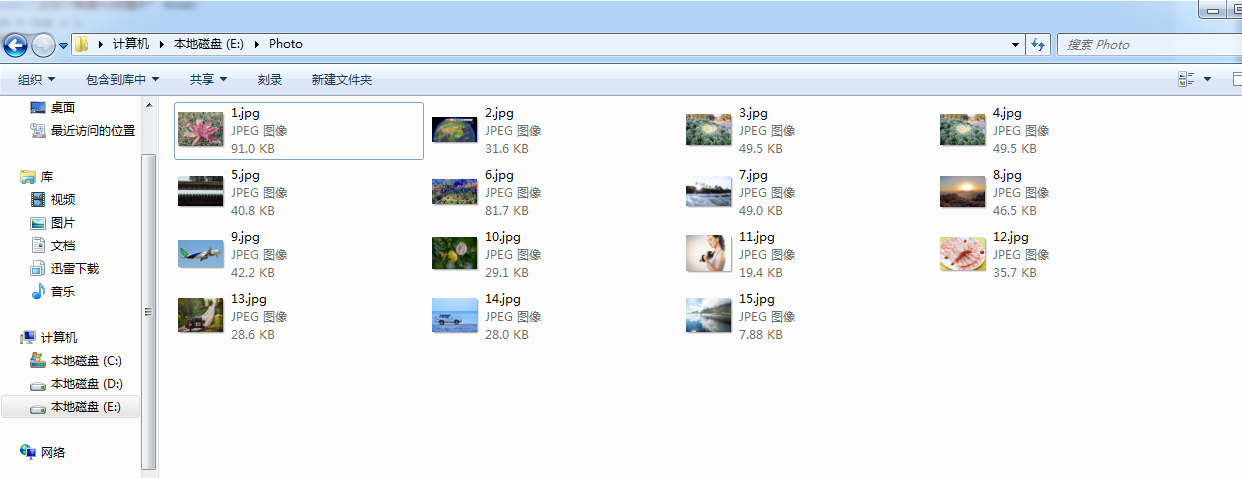
结果:
Python爬虫 爬取Web页面图片的更多相关文章
- 使用Python爬虫爬取网络美女图片
代码地址如下:http://www.demodashi.com/demo/13500.html 准备工作 安装python3.6 略 安装requests库(用于请求静态页面) pip install ...
- python爬虫——爬取NUS-WIDE数据库图片
实验室需要NUS-WIDE数据库中的原图,数据集的地址为http://lms.comp.nus.edu.sg/research/NUS-WIDE.htm 由于这个数据只给了每个图片的URL,所以需 ...
- python爬虫爬取汽车页面信息,并附带分析(静态爬虫)
环境: windows,python3.4 参考链接: https://blog.csdn.net/weixin_36604953/article/details/78156605 代码:(亲测可以运 ...
- python爬虫-爬取百度图片
python爬虫-爬取百度图片(转) #!/usr/bin/python# coding=utf-8# 作者 :Y0010026# 创建时间 :2018/12/16 16:16# 文件 :spider ...
- python爬虫---爬取王者荣耀全部皮肤图片
代码: import requests json_headers = { "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win ...
- 用Python爬虫爬取广州大学教务系统的成绩(内网访问)
用Python爬虫爬取广州大学教务系统的成绩(内网访问) 在进行爬取前,首先要了解: 1.什么是CSS选择器? 每一条css样式定义由两部分组成,形式如下: [code] 选择器{样式} [/code ...
- Python爬虫爬取全书网小说,程序源码+程序详细分析
Python爬虫爬取全书网小说教程 第一步:打开谷歌浏览器,搜索全书网,然后再点击你想下载的小说,进入图一页面后点击F12选择Network,如果没有内容按F5刷新一下 点击Network之后出现如下 ...
- python爬虫—爬取英文名以及正则表达式的介绍
python爬虫—爬取英文名以及正则表达式的介绍 爬取英文名: 一. 爬虫模块详细设计 (1)整体思路 对于本次爬取英文名数据的爬虫实现,我的思路是先将A-Z所有英文名的连接爬取出来,保存在一个cs ...
- 一个简单的python爬虫,爬取知乎
一个简单的python爬虫,爬取知乎 主要实现 爬取一个收藏夹 里 所有问题答案下的 图片 文字信息暂未收录,可自行实现,比图片更简单 具体代码里有详细注释,请自行阅读 项目源码: # -*- cod ...
随机推荐
- 【数据结构(C语言版)系列一】 线性表
最近开始看数据结构,该系列笔记简单记录总结下所学的知识,更详细的推荐博主StrayedKing的数据结构系列,笔记部分也摘抄了博主总结的比较好的内容. 一些基本概念和术语 数据是对客观事物的符号表示, ...
- [Usaco2008 Dec]Patting Heads 轻拍牛头
Description 今天是贝茜的生日,为了庆祝自己的生日,贝茜邀你来玩一个游戏. 贝茜让N(1≤N≤100000)头奶牛坐成一个圈.除了1号与N号奶牛外,i号奶牛与i-l号和i+l号奶牛相邻.N号 ...
- QT5每日一学(一)下载与安装
一.Qt SDK的下载和安装 1.下载 Qt官网主页提供了最新版Qt的下载,不过我们更倾向于去资源下载页面(https://download.qt.io/official_release ...
- ACM_数数?诶?这么简单?
数数?诶?这么简单? Time Limit: 2000/1000ms (Java/Others) Problem Description: 当看到GDUFE-GAME宣传海报上提到"场内人员 ...
- 188 Best Time to Buy and Sell Stock IV 买卖股票的最佳时机 IV
假设你有一个数组,其中第 i 个元素是第 i 天给定股票的价格.设计一个算法来找到最大的利润.您最多可以完成 k 笔交易.注意:你不可以同时参与多笔交易(你必须在再次购买前出售掉之前的股票). 详见: ...
- 基于Windows7下snort+apache+php 7 + acid(或者base) + adodb + jpgraph的入侵检测系统的搭建(图文详解)(博主推荐)
为什么,要写这篇论文? 是因为,目前科研的我,正值研三,致力于网络安全.大数据.机器学习.人工智能.区域链研究领域! 论文方向的需要,同时不局限于真实物理环境机器实验室的攻防环境.也不局限于真实物理机 ...
- 手写一套迷你版HTTP服务器
本文主要介绍如何通过netty来手写一套简单版的HTTP服务器,同时将关于netty的许多细小知识点进行了串联,用于巩固和提升对于netty框架的掌握程度. 服务器运行效果 服务器支持对静态文件css ...
- php高效率对一维数组进行去重
$input = array("a" => "green", "red", "b" => "gre ...
- taskctl的后台字符界面登录不了解决办法
今天在使用taskctl的designer时,十多分钟挂了2次,每次挂了之后就签不出来了,只能等半小时,然后在taskctl的QQ群里咨询了,给的解决方案是 http://www.taskctl.co ...
- ActiveX控件获取不到对象属性或者方法的原因分析
1.找不到调用的DLL或程序: 2.调用控件方法名称,与定义的函数名称不符合: 3.如果是网站网页调用ActiveX,检查控件是否添加安全对象: 4.如果是网站网页调用ActiveX,检查网页是否加入 ...