大数据学习——下载集群根目录下的文件到E盘
代码如下:
package cn.itcast.hdfs; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path; public class TestHDFS {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration(); //伪造root用户身份
System.setProperty("HADOOP_USER_NAME","root"); //1首先需要一个hdfs的客户端对象
conf.set("fs.defaultFS", "hdfs://mini1:9000");
FileSystem fs = FileSystem.get(conf);
fs.copyToLocalFile( new Path("/hello.txt"),new Path("E://"));
fs.close();
}
}
此时会报空指针异常
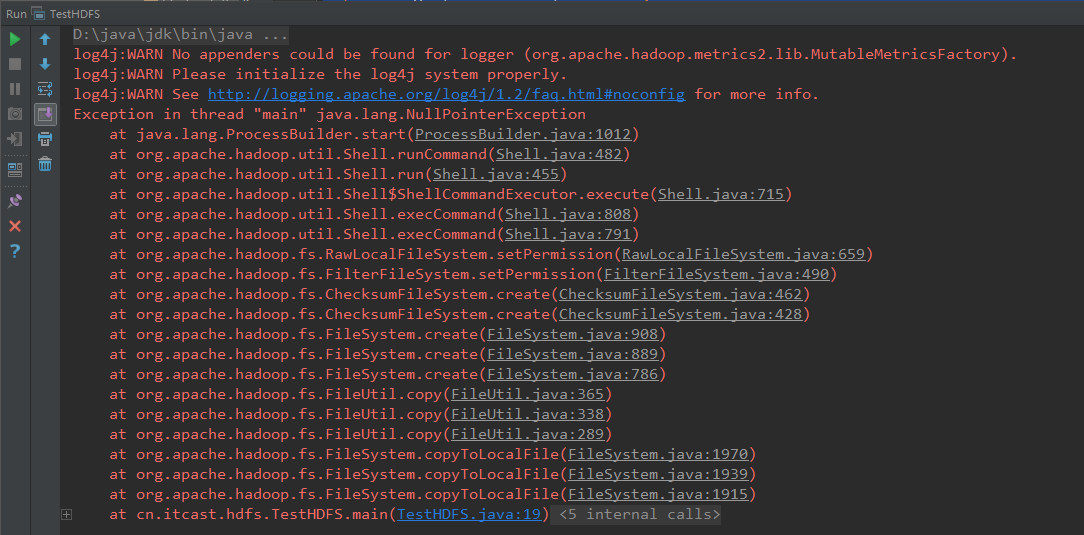
修改后代码如下:
package cn.itcast.hdfs; import java.io.IOException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path; public class TestHDFS {
public static void main(String[] args) throws IOException {
Configuration conf = new Configuration(); //伪造root用户身份
System.setProperty("HADOOP_USER_NAME", "root"); //1首先需要一个hdfs的客户端对象
conf.set("fs.defaultFS", "hdfs://mini1:9000");
FileSystem fs = FileSystem.get(conf);
// fs.copyToLocalFile( new Path("/hello.txt"),new Path("E://"));
fs.copyToLocalFile(false, new Path("/hello.txt"), new Path("E://"), true);
fs.close();
}
}
注意,出现以上的问题是没有配环境变量造成的
window下开发的说明
建议在linux下进行hadoop应用的开发,不会存在兼容性问题。如在window上做客户端应用开发,需要设置以下环境:
A、用老师给的windows平台下编译的hadoop安装包解压一份到windows的任意一个目录下
B、在window系统中配置HADOOP_HOME指向你解压的安装包目录
C、在windows系统的path变量中加入HADOOP_HOME的bin目录
大数据学习——下载集群根目录下的文件到E盘的更多相关文章
- 大数据学习——HADOOP集群搭建
4.1 HADOOP集群搭建 4.1.1集群简介 HADOOP集群具体来说包含两个集群:HDFS集群和YARN集群,两者逻辑上分离,但物理上常在一起 HDFS集群: 负责海量数据的存储,集群中的角色主 ...
- 大数据学习——Kafka集群部署
1下载安装包 2解压安装包 -0.9.0.1.tgz -0.9.0.1 kafka 3修改配置文件 cp server.properties server.properties.bak # Lice ...
- 大数据学习——Storm集群搭建
安装storm之前要安装zookeeper 一.安装storm步骤 1.下载安装包 2.解压安装包 .tar.gz storm 3.修改配置文件 mv /root/apps/storm/conf/st ...
- 大数据学习——hdfs集群启动
第一种方式: 1 格式化namecode(是对namecode进行格式化) hdfs namenode -format(或者是hadoop namenode -format) 进入 cd /root/ ...
- 大数据学习——hadoop集群搭建2.X
1.准备Linux环境 1.0先将虚拟机的网络模式选为NAT 1.1修改主机名 vi /etc/sysconfig/network NETWORKING=yes HOSTNAME=itcast ### ...
- 大数据学习——yarn集群启动
启动yarn命令: start-yarn.sh 验证是否启动成功 jps查看进程 http://192.168.74.100:8088页面 关闭 stop-yarn.sh
- 大数据测试之hadoop集群配置和测试
大数据测试之hadoop集群配置和测试 一.准备(所有节点都需要做):系统:Ubuntu12.04java版本:JDK1.7SSH(ubuntu自带)三台在同一ip段的机器,设置为静态IP机器分配 ...
- CDH构建大数据平台-配置集群的Kerberos认证安全
CDH构建大数据平台-配置集群的Kerberos认证安全 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 当平台用户使用量少的时候我们可能不会在一集群安全功能的缺失,因为用户少,团 ...
- 朝花夕拾之--大数据平台CDH集群离线搭建
body { border: 1px solid #ddd; outline: 1300px solid #fff; margin: 16px auto; } body .markdown-body ...
随机推荐
- Codeforces Round #418 (Div. 2) C
Description Nadeko's birthday is approaching! As she decorated the room for the party, a long garlan ...
- 线段树(单点更新) HDU 1754 I Hate It
题目传送门 /* 线段树基本功能:区间最大值,修改某个值 */ #include <cstdio> #include <cstring> #include <algori ...
- 题解报告:poj 2480 Longge's problem(欧拉函数)
Description Longge is good at mathematics and he likes to think about hard mathematical problems whi ...
- STM32CUBEMX使用注意:
一 注意堆栈大小,简单来说,栈空间用于局部变量空间(size=0x400一般够用),堆(size=0x200一般够用)空间用于 alloc 或者 malloc函数动态申请变量空间
- 基于CentOS 7.2个人网盘的实现
首先使用YUM安装依赖环境: [root@sishen ~]#yum install python python-setuptools python-imaging python-ldap pytho ...
- php一致性hash性能测试(flexihash/memcache/memcached)
一致性hash的使用在PHP中有三种选择分别是原生的memcache扩展,memcached扩展,还有一个是网上比较流行的flexihash类. 最近有项目需要使用flexihash类操作memcac ...
- html语法第 -2
1 <html> 2 <head> 3 <title>这是第一节课网页标题</title> 4 <meta charset="UTF-8 ...
- 一段字符串中间提取json字符串
项目过程中经常打日志:LOG.error("[failure][CreateOrder] param:{}", JSON.toJSONString(userCreateOrderD ...
- Thrift入门及Java实例演示【转】
概述 Thrift是一个软件框架,用来进行可扩展且跨语言的服务的开发.它结合了功能强大的软件堆栈和代码生成引擎,以构建在 C++.Java.Python.PHP.Ruby.Erlang.Perl.Ha ...
- 位bit,字节byte,K,M,G(转)
字节是由8个位所组成,可代表一个字符(A~Z).数字(0~9).或符号(,.?!%&+-*/),是内存储存数据的基本单位.1 byte = 8 bit 1 KB = 1024 bytes1 ...