Scrapy入门到放弃03:理解settings配置,监控Scrapy引擎
前言
代码未动,配置先行。本篇文章主要讲述一下Scrapy中的配置文件settings.py的参数含义,以及如何去获取一个爬虫程序的运行性能指标。
这篇文章无聊的一匹,没有代码,都是配置化的东西,但是呢不学还不行,属于Scrapy的枢纽,很关键。所以还请各位看官老爷耐得住这一章的寂寞。
settings.py
在我们创建一个Scrapy项目的时候,就会在项目下生成四个py文件,其中就有一个settings.py。其中大大小小配置也是有大几十个,这里只讲一些比较常见的,其他的还请移步官方文档。
官文配置参数说明url:
https://docs.scrapy.org/en/latest/topics/settings.html
常见参数
下面也罗列了小几十个配置,大部分都其实使用默认值即可,最值得我们关注的,就是下面几个:
- DOWNLOAD_DELAY
- CONCURRENT_REQUESTS
- CONCURRENT_REQUESTS_PER_DOMAIN
- CONCURRENT_REQUESTS_PER_IP
- SPIDER_MIDDLEWARES
- DOWNLOADER_MIDDLEWARES
- ITEM_PIPELINES
那么,为什么说Settings是Scrapy的枢纽?
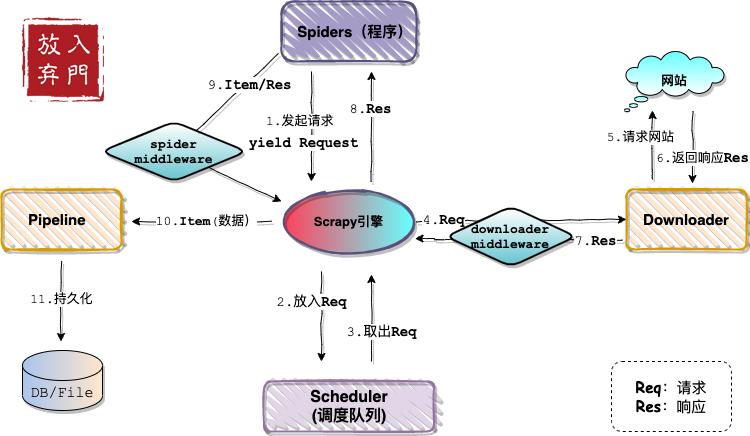
还记得我上篇文章画的架构图吗?还记得之前说过Scrapy的四大模块吗?每个模块在项目初始化时都是独立的,各个模块只有在Settings配置之后,请求、响应、数据才会在模块间流转。这一部分对应上面提到的配置5、6、7。
配置具体说明,详看下文:
# Scrapy settings for ScrapyDemo project
# 自动生成的配置,无需关注,不用修改
BOT_NAME = 'ScrapyDemo'
SPIDER_MODULES = ['ScrapyDemo.spiders']
NEWSPIDER_MODULE = 'ScrapyDemo.spiders'
# 设置UA,但不常用,一般都是在MiddleWare中添加
USER_AGENT = 'ScrapyDemo (+http://www.yourdomain.com)'
# 遵循robots.txt中的爬虫规则,很多人喜欢False,当然我也喜欢....
ROBOTSTXT_OBEY = True
# 对网站并发请求总数,默认16
CONCURRENT_REQUESTS = 32
# 相同网站两个请求之间的间隔时间,默认是0s。相当于time.sleep()
DOWNLOAD_DELAY = 3
# 下面两个配置二选一,但其值不能大于CONCURRENT_REQUESTS,默认启用PER_DOMAIN
# 对网站每个域名的最大并发请求,默认8
CONCURRENT_REQUESTS_PER_DOMAIN = 16
# 默认0,对网站每个IP的最大并发请求,会覆盖上面PER_DOMAIN配置,
# 同时DOWNLOAD_DELAY也成了相同IP两个请求间的间隔了
CONCURRENT_REQUESTS_PER_IP = 16
# 禁用cookie,默认是True,启用
COOKIES_ENABLED = False
# 请求头设置,这里基本上不用
DEFAULT_REQUEST_HEADERS = {
# 'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
# 'Accept-Language': 'en',
#}
# 配置启用Spider MiddleWares,Key是class,Value是优先级
SPIDER_MIDDLEWARES = {
'ScrapyDemo.middlewares.ScrapydemoSpiderMiddleware': 543,
}
# 配置启用Downloader MiddleWares
DOWNLOADER_MIDDLEWARES = {
'ScrapyDemo.middlewares.ScrapydemoDownloaderMiddleware': 543,
}
# 配置并启用扩展,主要是一些状态监控
EXTENSIONS = {
'scrapy.extensions.telnet.TelnetConsole': None,
}
# 配置启用Pipeline用来持久化数据
ITEM_PIPELINES = {
'ScrapyDemo.pipelines.ScrapydemoPipeline': 300,
}
# 禁止控制台使用telnet连接scrapy获取状态,默认是启用。我们使用默认值即可
TELNETCONSOLE_ENABLED = False
# Telnet终端使用的端口范围。默认: [6023, 6073],如果设置为 None 或 0 , 则使用动态分配的端口
# TELNETCONSOLE_PORT
# telnet账号,默认:scrapy
TELNETCONSOLE_USERNAME = None
# telnet密码:默认会自动生成一个密码
TELNETCONSOLE_PASSWORD
# Telnet终端监听的接口(interface)。默认: '127.0.0.1'
TELNETCONSOLE_HOST = '127.0.0.1'
# AutoThrottle是限速节流算法
# 让爬虫程序自适应download_delay和concurrent并发
AUTOTHROTTLE_ENABLED = True
# 爬虫程序启动时,开始对网站发起请求的延迟
AUTOTHROTTLE_START_DELAY = 5
# 请求到响应的最大允许的延迟时间,必须大于download_delay
AUTOTHROTTLE_MAX_DELAY = 60
# 并行发送到每个远程服务器的平均请求数,小于CONCURRENT_REQUESTS_PER_DOMAIN和CONCURRENT_REQUESTS_PER_IP
AUTOTHROTTLE_TARGET_CONCURRENCY = 1.0
# 为每个响应启用显示限制统计信息
AUTOTHROTTLE_DEBUG = False
# HttpCache主要是将每次的请求和响应缓存到本地,可以离线进行处理
# 配置启用HTTP Cache,默认不启用
HTTPCACHE_ENABLED = True
# 缓存的过期时间,0为永不过期
HTTPCACHE_EXPIRATION_SECS = 0
# 缓存目录名称
HTTPCACHE_DIR = 'httpcache'
# 设置不需要缓存的状态码请求
HTTPCACHE_IGNORE_HTTP_CODES = []
# 此类将缓存保存到本地文件系统,还可以使用其他类保存到数据库
HTTPCACHE_STORAGE = 'scrapy.extensions.httpcache.FilesystemCacheStorage'
像上面的Telnet配置使用默认即可,一般AutoThrottle限速算法和Http Cache用的也少,当然还有一些log日志、retry请求重试功能,这里就不一一列举了。
局部配置定义
settings.py中的配置,属于全局配置,是项目中所有爬虫共享的。改了一个,其他的爬虫也会受影响。
所以很多时候我们都会在爬虫程序内,定义字典类型的custom_settings成员变量,来实现局部配置。
custom_settings = {
'DOWNLOAD_DELAY': 10
}
这样DOWNLOAD_DELAY为10这个配置,只在当前程序中生效。
那这局部配置在什么时候用的多?
我用的最多的地方,就是使用Scrapy-Splash插件的时候,因为要发起的是SplashRequest,而不是之前的Request,所以要进行单独的配置。为了不改变全局配置、影响其他爬虫,通常在程序内定义这些配置。

这个后面Scrapy-Splash插件会讲。
启动时配置
我们在启动爬虫时,可以使用-s来指定配置。
scrapy crawl [spiderName] -s DOWNLOAD_DELAY=10
程序中获取配置
我们通常也将数据库的用户、密码、ip等信息配置在settings中,然后通过crawler对象来获取。该对象提供对所有Scrapy核心组件的访问,可以debug看一下。
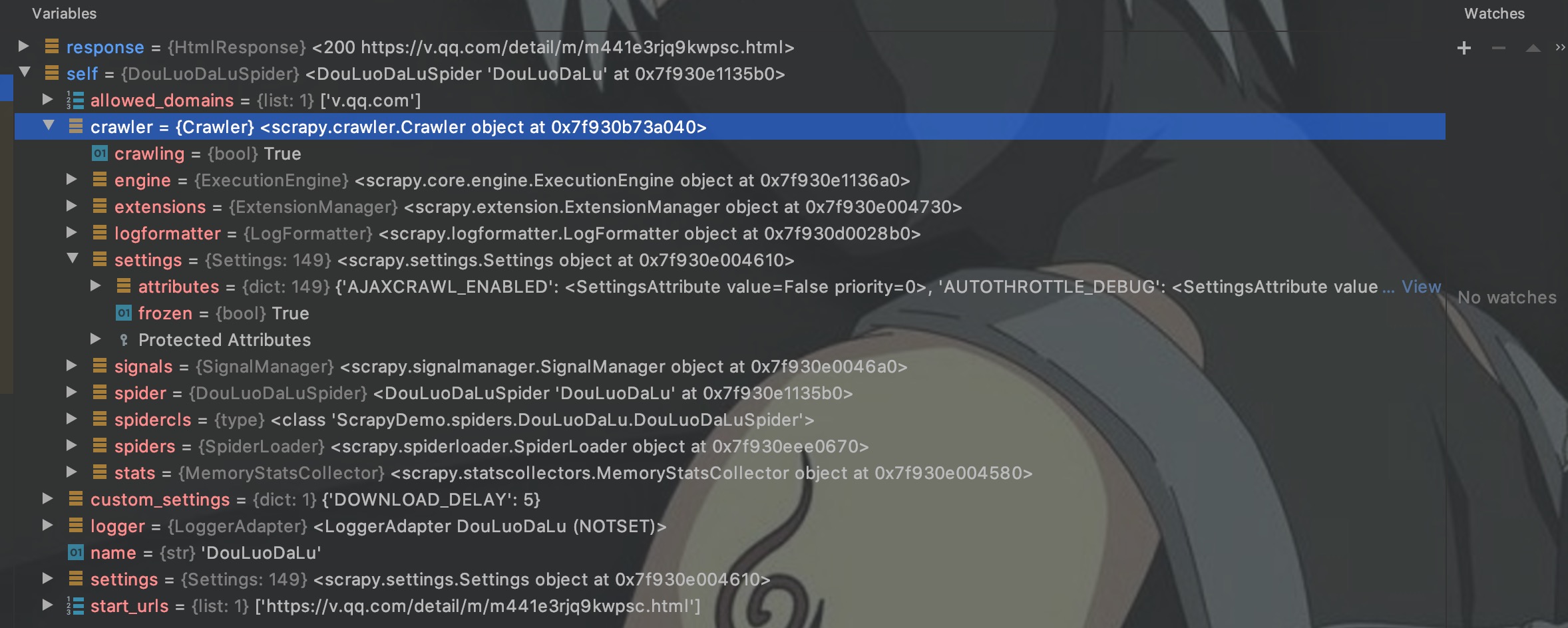
如图,可以通过crawler访问到settings配置、engine引擎、信号量signals、状态stat等。这里我们先只关注settings。
这里写一段代码,验证局部配置、启动时配置、以及配置三个功能。
import scrapy
class DouLuoDaLuSpider(scrapy.Spider):
name = 'DouLuoDaLu'
allowed_domains = ['v.qq.com']
start_urls = ['https://v.qq.com/detail/m/m441e3rjq9kwpsc.html']
# 自定义配置
custom_settings = {
'DOWNLOAD_DELAY': 10
}
def parse(self, response):
# 获取配置
delay = self.crawler.settings.get('DOWNLOAD_DELAY')
print(delay)
DOWNLOAD_DELAY在全局配置中我修改为3,如果没有在程序中定义custom_settings,则输出为3。
当我们定义custom_settings之后,启动程序,输出如下:

这里输出的就是10,是程序内的配置,覆盖了全局配置。当我们使用以下命令在启动爬虫时指定延迟为11。
scrapy crawl DouLuoDaLu -s DOWNLOAD_DELAY=11

则输出为11,覆盖了程序内变量。所以,我们也得出一个结论,同一配置的优先级为:
启动时配置 > 程序内配置 > 全局配置
引擎状态监控
关于引擎的定义:
Scrapy engine which controls the Scheduler, Downloader and Spiders
引擎状态是指现在调度器中有多少请求排队、下载器中有多少个请求正在下载、有多少响应在被处理等等,而监控是通过telnet来实现。
我的Scrapy中全局配置都是默认的,为了直观,我这里都使用局部配置。这里我发起100 * 10次请求,模拟一个一直运行的爬虫,代码如下:
import scrapy
from scrapy import Request
class DouLuoDaLuSpider(scrapy.Spider):
name = 'DouLuoDaLu'
allowed_domains = ['v.qq.com']
start_urls = ['https://v.qq.com/detail/m/m441e3rjq9kwpsc.html']
custom_settings = {
'DOWNLOAD_DELAY': 6,
'CONCURRENT_REQUESTS': 32,
'CONCURRENT_REQUESTS_PER_DOMAIN': 8,
# 账号默认就是scrapy
# 'TELNETCONSOLE_USERNAME' = 'scrapy'
'TELNETCONSOLE_PASSWORD': 'scrapy'
}
def start_requests(self):
for i in range(0, 100):
yield Request(url=self.start_urls[0], callback=self.parse, dont_filter=True)
def parse(self, response):
for i in range(0, 10):
yield Request(url=self.start_urls[0], callback=self.parse, dont_filter=True)
启动爬虫之后,使用以下命令进入telnet。
# telnet终端监听端口配置为*TELNETCONSOLE_PORT*,默认为6023。
telnet localhost 6023
输入账号和密码:
进入交互页面,输入est(),输出引擎状态指标。
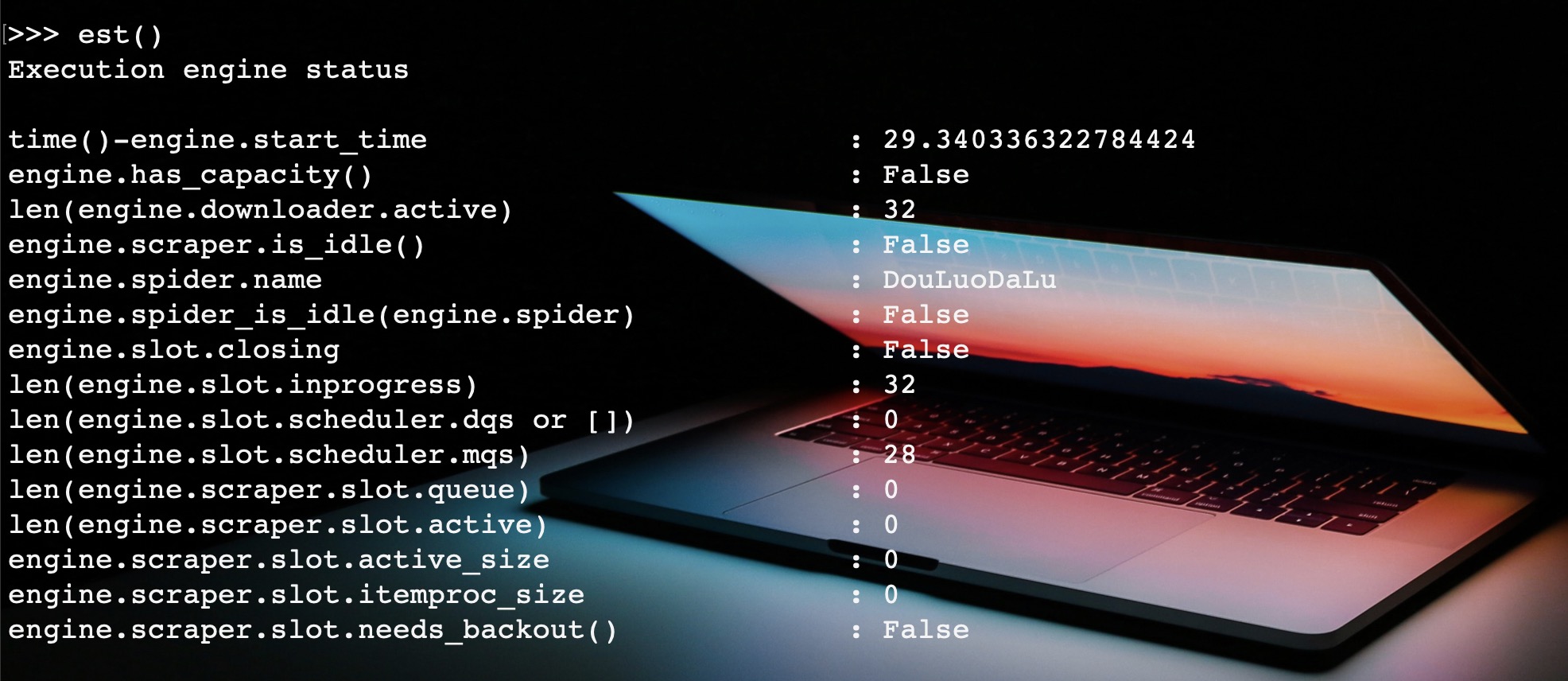
主要监控一下五个指标:
- engine.downloader.active:下载器中等待下载的请求,对应最大并发数。设置中为32,这里也是32,说明下载器已经满了,其他请求进不来了。
- engine.slot.scheduler.mqs:内存调度队列。进不去下载器的请求就只能在调度器中等待了,这里有28个请求在等待。
- engine.slot.scheduler.dqs:磁盘调度队列,可以设置,将请求放于磁盘之中。
- engine.scraper.slot.active:正在被处理的响应数量
- engine.scraper.slot.itemproc_size:pipeline处理的Item数量
同时也可以在交互命令中暂停、恢复、停止引擎。
engine.pause()
engine.unpause()
engine.stop()
当引擎被暂停或停止,下载器处理完队列中的请求之后,便处于空闲状态。
结语
本篇文章主要讲了一些基本的配置和Telnet引擎监控,主要目的还是为了将Scrapy架构掰扯清楚,后面用的时候才能了然于胸。
后面的文章接着写其他模块,下一篇讲MiddleWare中间件,下下篇就是Pipeline,下下下篇打算写一个完整的样例,将各个模块整合起来。期待下一次相遇。
95后小程序员,写的都是日常工作中的亲身实践,置身于初学者的角度从0写到1,详细且认真。文章会在公众号 [入门到放弃之路] 首发,期待你的关注。

Scrapy入门到放弃03:理解settings配置,监控Scrapy引擎的更多相关文章
- Scrapy入门到放弃01:开启爬虫2.0时代
前言 Scrapy is coming!! 在写了七篇爬虫基础文章之后,终于写到心心念念的Scrapy了.Scrapy开启了爬虫2.0的时代,让爬虫以一种崭新的形式呈现在开发者面前. 在18年实习的时 ...
- Scrapy入门到放弃04:下载器中间件,让爬虫更完美
前言 MiddleWare,顾名思义,中间件.主要处理请求(例如添加代理IP.添加请求头等)和处理响应 本篇文章主要讲述下载器中间件的概念,以及如何使用中间件和自定义中间件. MiddleWare分类 ...
- Scrapy入门到放弃05:让Item在Pipeline中飞一会儿
前言 "又回到最初的起点,呆呆地站在镜子前". 本来这篇是打算写Spider中间件的,但是因为这一块涉及到Item,所以这篇文章先将Item讲完,顺便再讲讲Pipeline,然后再 ...
- Scrapy入门到放弃06:Spider中间件
前言 写一写Spider中间件吧,都凌晨了,一点都不想写,主要是也没啥用...哦不,是平时用得少.因为工作上的事情,已经拖更好久了,这次就趁着半夜写一篇. Scrapy-deltafetch插件是在S ...
- scrapy反反爬虫策略和settings配置解析
反反爬虫相关机制 Some websites implement certain measures to prevent bots from crawling them, with varying d ...
- scrapy入门到放弃02:整一张架构图,开发一个程序
前言 Scrapy开门篇写了一些纯理论知识,这第二篇就要直奔主题了.先来讲讲Scrapy的架构,并从零开始开发一个Scrapy爬虫程序. 本篇文章主要阐述Scrapy架构,理清开发流程,掌握基本操作. ...
- Python爬虫从入门到放弃(十五)之 Scrapy框架中Spiders用法
Spider类定义了如何爬去某个网站,包括爬取的动作以及如何从网页内容中提取结构化的数据,总的来说spider就是定义爬取的动作以及分析某个网页 工作流程分析 以初始的URL初始化Request,并设 ...
- Python爬虫从入门到放弃(二十三)之 Scrapy的中间件Downloader Middleware实现User-Agent随机切换
总架构理解Middleware 通过scrapy官网最新的架构图来理解: 这个图较之前的图顺序更加清晰,从图中我们可以看出,在spiders和ENGINE提及ENGINE和DOWNLOADER之间都可 ...
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
随机推荐
- MySQL零散知识点(01)
内容概要 --- 表字段操作补充(掌握) --- python操作MySQL(掌握) --- 视图(了解) --- 触发器(了解) --- 存储过程(了解) --- 事务(掌握) --- 内置函数(了 ...
- Quill基本使用和配置 - DevUI
DevUI 是一款面向企业中后台产品的开源前端解决方案,它倡导沉浸.灵活.至简的设计价值观,提倡设计者为真实的需求服务,为多数人的设计,拒绝哗众取宠.取悦眼球的设计.如果你正在开发 ToB 的工具类产 ...
- Java编程技巧:if-else优化实践总结归纳
文/朱季谦 说实话,其实我很讨厌在代码里大量使用if-else,一是因为该类代码属于面向过程的,二嘛,则是会显得代码过于冗余.这篇笔记,主要记录一些自己在工作实践当中针对if-else的优化心得,将会 ...
- 微信订阅号中获取openid以及个人信息
采用的方式是利用另一个服务号获取用户信息. 其中有一个问题就是不关注这个服务号获取不了用户头像等信息.
- 温故知新,CSharp遇见异步编程(Async/Await),聊聊异步编程最佳做法
什么是异步编程(Async/Await) Async/Await本质上是通过编译器实现的语法糖,它让我们能够轻松的写出简洁.易懂.易维护的异步代码. Async/Await是C# 5引入的关键字,用以 ...
- 限流神器Sentinel,不了解一下吗?
概述 书接上回:你来说说什么是限流? ,限流的整体概述中,描述了 限流是什么,限流方式和限流的实现.在文章尾部的 分布式限流,没有做过多的介绍,选择了放到这篇文章中.给大伙细细讲解一下 Sentine ...
- 2、linux防火墙的使用(firewalld)
2.1.说明: 1.在 RHEL7 里有几种防火墙共存,firewalld.iptables,默认是使用 firewalld 来管理 netfilter 子系统,不过底层调用的命令仍然是 iptabl ...
- 27、Tomcat服务的安装与配置
服务器名称 ip地址 slave-node1 172.16.1.91 27.1. Tomcat简介: Tomcat是Apache软件基金会(Apache Software Foundation)的Ja ...
- 11、gitlab和Jenkins整合(2)
5.补充: (1)构建说明: 1)Jenkins会基于一些处理器任务后,构建发布一个稳健指数 (从0-100 ),这些任务一般以插件的方式实现. 2)它们可能包括单元测试(JUnit).覆盖率(Cob ...
- springcloud gateway(hystrix filter)
参考 https://blog.csdn.net/forezp/article/details/83792388 1.依赖pom.xml <project xmlns="http:// ...