(数据科学学习手札128)在matplotlib中添加富文本的最佳方式
本文示例代码及文件已上传至我的
Github仓库https://github.com/CNFeffery/DataScienceStudyNotes
1 简介
长久以来,在使用matplotlib进行绘图时,一直都没有比较方便的办法像R中的ggtext那样,向图像中插入整段的混合风格富文本内容,譬如下面的例子:

而几天前我在逛github的时候偶然发现了一个叫做flexitext的第三方库,它设计了一套类似ggtext的语法方式,使得我们可以用一种特殊的语法在matplotlib中构建整段富文本,下面我们就来get它吧~
2 使用flexitext在matplotlib中创建富文本
在使用pip install flexitext完成安装之后,我们使用下列语句导入所需模块:
from flexitext import flexitext
2.1 基础用法
flexitext中定义富文本的语法有些类似html标签,我们需要将施加了特殊样式设置的内容包裹在成对的<>与</>中,并在<>中以属性名:属性值的方式完成各种样式属性的设置,譬如我们想要插入一段混合了不同粗细、色彩以及字体效果的富文本:
from flexitext import flexitext
import matplotlib.pyplot as plt
# 将幼圆与楷体插入到matplotlib字体库中
plt.rcParams['font.sans-serif'] = ['YouYuan', 'KaiTi'] + plt.rcParams['font.sans-serif']
fig, ax = plt.subplots(figsize=(9, 6))
flexitext(0.5,
0.5,
'''<size:30>这<color:yellow>是</>一段<weight:bold, name:DejaVu Sans>flexitext</><color: red, name:KaiTi>富文本</>测试</>''',
ha="center");

很舒服!我们使用flexitext()来替换ax.text()方法,它在兼容了ax.text()关于文字坐标以及对齐方式等常规参数的同时,帮助我们以特殊的格式定义文本内容及样式风格,下面我们就来进一步学习flexitext中支持的各种参数设置。
2.2 flexitext标签中的常用属性参数
在前面的例子中我们在标签中使用到了size、color、weight以及name等属性参数,而flexitext中标签支持的常用属性参数如下:
2.2.1 利用size设置文本像素大小
size属性非常简单,其用于定义标签所包裹文本内容的像素尺寸:
fig, ax = plt.subplots(figsize=(9, 6))
flexitext(0.5,
0.5,
'<size:20>size=20</><size:30>size=30</><size:40>size=40</><size:50>size=50</>',
ha="center")
plt.savefig('图3.png', dpi=300)
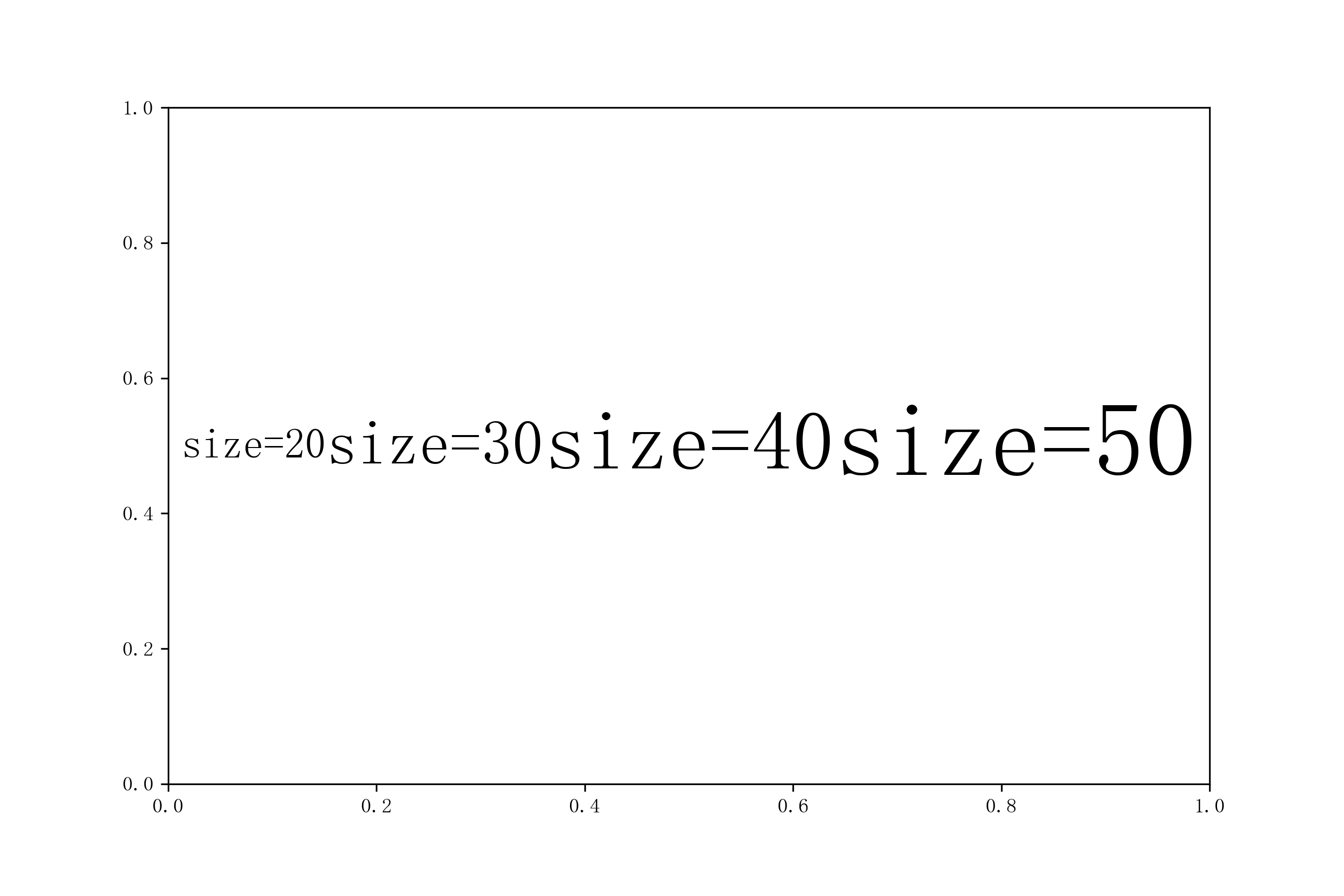
2.2.2 利用name设置字体
name属性可以用来设置具体的字体名称,关于matplotlib中的字体设置相关知识你可以参考我以前写过的搞定matplotlib中的字体设置https://www.cnblogs.com/feffery/p/14122415.html,下面分别演示系统自带的字体,以及自行注册导入的自定义字体是如何在flexitext中使用的(其中每种字体的name你可以通过font_manager.fontManager.ttflist查看):
from matplotlib import font_manager
# 从本地文件中注册新字体
font_manager.fontManager.addfont('Dark Twenty.otf')
font_manager.fontManager.addfont('Yozai-Regular.ttf')
font_manager.fontManager.addfont('LXGWWenKai-Regular.ttf')
fig, ax = plt.subplots(figsize=(9, 6))
flexitext(0.5,
0.5,
'<size:60, name:Dark Twenty>Dark Twenty</>\n<size:60, name:Yozai>悠哉字体</>\n<size:60, name:LXGW WenKai>霞鹜文楷</>',
ha="center")
plt.savefig('图4.png', dpi=300)

2.2.3 利用weight设置文本字体粗细
weight属性用于设置文本的粗细程度,可传入0到1000之间的数值,或是ultralight、light、normal、regular、book、medium、roman、semibold、demibold、demi、bold、heavy、extra bold、black中的选项,不过这个属性依赖具体的字体族(flexitext中使用family属性来定义)是否包含对应的粗细版本,所以有时候设置无效是正常的,譬如下面的例子中Times New Roman是完整的字体族,因此可以设置粗细:
fig, ax = plt.subplots(figsize=(9, 6))
flexitext(0.5,
0.5,
(
'<size:50, family:Times New Roman>weight:regular</>\n'
'<weight:bold, size:50, family:Times New Roman>weight:bold</>\n'
'<weight:bold, size:50, name:LXGW WenKai>霞鹜文楷bold无效</>'
),
ha="center",
ma='center')
plt.savefig('图5.png', dpi=300)

2.2.4 利用color、backgroundcolor设置文本颜色及背景色
color与backgroundcolor属性接受matplotlib中合法的颜色值输入,可用于对标签所囊括文本的色彩及背景色进行设置,譬如下面我们配合调色库palettable来制作一些花里胡哨的文字:
from palettable.colorbrewer.diverging import Spectral_6
fig, ax = plt.subplots(figsize=(9, 6))
text = ''
for i, s in enumerate(list('制造一场彩虹')):
text += '<size:50, name:LXGW WenKai, color:{}>{}</>'.format(Spectral_6.hex_colors[i], s)
flexitext(0.5,
0.6,
text,
ha="center",
ma='center')
flexitext(0.5,
0.4,
'<name:LXGW WenKai, size:50, color:white, backgroundcolor: {}>制造一场彩虹</>'.format(Spectral_6.hex_colors[2]),
ha="center",
ma='center')
plt.savefig('图6.png', dpi=300)

2.2.5 利用alpha调节文字透明度
alpha参数则用于设置文字的透明度,取值在0到1之间,来看一个简单的例子:
import numpy as np
fig, ax = plt.subplots(figsize=(9, 6))
flexitext(0.5,
0.4,
('<name:LXGW WenKai, size:50, alpha:{}>绘</>'*9).format(
*np.linspace(1, 0, 9).tolist()
),
ha="center",
ma='center')
plt.savefig('图7.png', dpi=300)

关于flexitext的其余可用参数等信息,感兴趣的朋友可以自行前往官方仓库进行查看:https://github.com/tomicapretto/flexitext
以上就是本文的全部内容,欢迎在评论区与我进行讨论~
(数据科学学习手札128)在matplotlib中添加富文本的最佳方式的更多相关文章
- (数据科学学习手札49)Scala中的模式匹配
一.简介 Scala中的模式匹配类似Java中的switch语句,且更加稳健,本文就将针对Scala中模式匹配的一些基本实例进行介绍: 二.Scala中的模式匹配 2.1 基本格式 Scala中模式匹 ...
- (数据科学学习手札32)Python中re模块的详细介绍
一.简介 关于正则表达式,我在前一篇(数据科学学习手札31)中已经做了详细介绍,本篇将对Python中自带模块re的常用功能进行总结: re作为Python中专为正则表达式相关功能做出支持的模块,提供 ...
- (数据科学学习手札143)为geopandas添加gdb文件写出功能
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 大家好我是费老师,很多读者朋友跟随着我先前写作的 ...
- (数据科学学习手札25)sklearn中的特征选择相关功能
一.简介 在现实的机器学习任务中,自变量往往数量众多,且类型可能由连续型(continuou)和离散型(discrete)混杂组成,因此出于节约计算成本.精简模型.增强模型的泛化性能等角度考虑,我们常 ...
- (数据科学学习手札126)Python中JSON结构数据的高效增删改操作
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在上一期文章中我们一起学习了在Python ...
- (数据科学学习手札131)pandas中的常用字符串处理方法总结
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 在日常开展数据分析的过程中,我们经常需要对 ...
- (数据科学学习手札136)Python中基于joblib实现极简并行计算加速
本文示例代码及文件已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 我们在日常使用Python进行各种数据计算 ...
- (数据科学学习手札146)geopandas中拓扑非法问题的发现、诊断与修复
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 大家好我是费老师,geopandas作为在Pyt ...
- (数据科学学习手札52)pandas中的ExcelWriter和ExcelFile
一.简介 pandas中的ExcelFile()和ExcelWriter(),是pandas中对excel表格文件进行读写相关操作非常方便快捷的类,尤其是在对含有多个sheet的excel文件进行操控 ...
随机推荐
- CleanArchitecture Application代码生成插件-让程序员告别CURD Ctrl+C Ctrl+V
这是一个根据Domain项目中定义的实体对象(Entity)生成符合Clean Architecture原则的Application项目所需要的功能代码,包括常用的Commands,Queries,V ...
- 012 基于FPGA的网口通信实例设计【转载】
一.网口通信设计分类 通过上面其他章节的介绍,网口千兆通信,可以使用TCP或者UDP协议,可以外挂PHY片或者不挂PHY片,总结下来就有下面几种方式完成通信: 图8‑17基于FPGA的网口通信实例设计 ...
- MySQL数据类型 储存引擎
存储引擎 日常生活中文件格式有很多种,并且针对不同的文件格式会有对应不同存储方式和处理机制(txt,pdf,word,mp4...) 针对不同的数据应该对应着不同的处理机制来存储 存储引擎就是不同的处 ...
- NOIP 模拟 7 寿司
题解 题目 这道题考试的时候直接打暴力,结果暴力连样例都过不了,最后放上去一个玄学东西,骗了 \(5pts\). 正解: 此题中我们可以看到原序列是一个环,所以我们要把它拆成一条链,那么我们需要暴力枚 ...
- 小白5分钟创建WPF
创建WPF应用程序 基于生产这里选择.Net Framework进行开发 添加控件 由于不熟悉 高效点 我们这里直接拖拽控件 如果你有一点前端基础 你可以在控件对应Code 根据属性 对控件进行设置 ...
- Wpf程序显示在任务栏
后台代码如下: using System; using System.Collections.Generic; using System.Drawing; using System.IO; using ...
- Wiring in Spring: @Autowired, @Resource and @Inject 区别
refer:https://www.baeldung.com/spring-annotations-resource-inject-autowire 主要是查找顺序不一致: @Resource Mat ...
- mysql:刚刚知道的冷知识(一)
唯一索引的值可以null 1.创建一张user表,name字段指定为唯一索引 create table user( id int primary key auto_increment, name va ...
- Linux基础——安装以及常用命令
Linux基础--常用命令 1.安装Vmware 进入VMware官网: https://www.vmware.com/cn.html下载安装 镜像推荐网址下载:https://www.linux. ...
- python操作图片
时间:2018-11-30 记录:byzqy 标题:python实现图片操作 地址:https://blog.csdn.net/baidu_34045013/article/details/79187 ...