CUDA ---- 线程配置
前言
线程的组织形式对程序的性能影响是至关重要的,本篇博文主要以下面一种情况来介绍线程组织形式:
- 2D grid 2D block
线程索引
矩阵在memory中是row-major线性存储的:

在kernel里,线程的唯一索引非常有用,为了确定一个线程的索引,我们以2D为例:
- 线程和block索引
- 矩阵中元素坐标
- 线性global memory 的偏移
首先可以将thread和block索引映射到矩阵坐标:
ix = threadIdx.x + blockIdx.x * blockDim.x
iy = threadIdx.y + blockIdx.y * blockDim.y
之后可以利用上述变量计算线性地址:
idx = iy * nx + ix
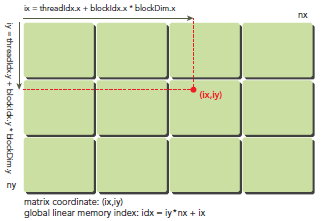
上图展示了block和thread索引,矩阵坐标以及线性地址之间的关系,谨记,相邻的thread拥有连续的threadIdx.x,也就是索引为(0,0)(1,0)(2,0)(3,0)...的thread连续,而不是(0,0)(0,1)(0,2)(0,3)...连续,跟我们线代里玩矩阵的时候不一样。
现在可以验证出下面的关系:
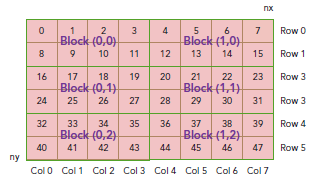
thread_id(2,1)block_id(1,0) coordinate(6,1) global index 14 ival 14
下图显示了三者之间的关系:
代码
int main(int argc, char **argv) {
printf("%s Starting...\n", argv[]);
// set up device
int dev = ;
cudaDeviceProp deviceProp;
CHECK(cudaGetDeviceProperties(&deviceProp, dev));
printf("Using Device %d: %s\n", dev, deviceProp.name);
CHECK(cudaSetDevice(dev));
// set up date size of matrix
int nx = <<;
int ny = <<;
int nxy = nx*ny;
int nBytes = nxy * sizeof(float);
printf("Matrix size: nx %d ny %d\n",nx, ny);
// malloc host memory
float *h_A, *h_B, *hostRef, *gpuRef;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
hostRef = (float *)malloc(nBytes);
gpuRef = (float *)malloc(nBytes);
// initialize data at host side
double iStart = cpuSecond();
initialData (h_A, nxy);
initialData (h_B, nxy);
double iElaps = cpuSecond() - iStart;
memset(hostRef, , nBytes);
memset(gpuRef, , nBytes);
// add matrix at host side for result checks
iStart = cpuSecond();
sumMatrixOnHost (h_A, h_B, hostRef, nx,ny);
iElaps = cpuSecond() - iStart;
// malloc device global memory
float *d_MatA, *d_MatB, *d_MatC;
cudaMalloc((void **)&d_MatA, nBytes);
cudaMalloc((void **)&d_MatB, nBytes);
cudaMalloc((void **)&d_MatC, nBytes);
// transfer data from host to device
cudaMemcpy(d_MatA, h_A, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(d_MatB, h_B, nBytes, cudaMemcpyHostToDevice);
// invoke kernel at host side
int dimx = ;
int dimy = ;
dim3 block(dimx, dimy);
dim3 grid((nx+block.x-)/block.x, (ny+block.y-)/block.y);
iStart = cpuSecond();
sumMatrixOnGPU2D <<< grid, block >>>(d_MatA, d_MatB, d_MatC, nx, ny);
cudaDeviceSynchronize();
iElaps = cpuSecond() - iStart;
printf("sumMatrixOnGPU2D <<<(%d,%d), (%d,%d)>>> elapsed %f sec\n", grid.x,
grid.y, block.x, block.y, iElaps);
// copy kernel result back to host side
cudaMemcpy(gpuRef, d_MatC, nBytes, cudaMemcpyDeviceToHost);
// check device results
checkResult(hostRef, gpuRef, nxy);
// free device global memory
cudaFree(d_MatA);
cudaFree(d_MatB);
cudaFree(d_MatC);
// free host memory
free(h_A);
free(h_B);
free(hostRef);
free(gpuRef);
// reset device
cudaDeviceReset();
return ();
}
编译运行:
$ nvcc -arch=sm_20 sumMatrixOnGPU-2D-grid-2D-block.cu -o matrix2D
$ ./matrix2D
输出:
./a.out Starting...
Using Device : Tesla M2070
Matrix size: nx ny
sumMatrixOnGPU2D <<<(,), (,)>>> elapsed 0.060323 sec
Arrays match.
接下来,我们更改block配置为32x16,重新编译,输出为:
sumMatrixOnGPU2D <<<(512,1024), (32,16)>>> elapsed 0.038041 sec
可以看到,性能提升了一倍,直观的来看,我们会认为第二个配置比第一个多了一倍的block所以性能提升一倍,实际上也确实是因为block增加了。但是,如果你继续增加block的数量,则性能又会降低:
sumMatrixOnGPU2D <<< (1024,1024), (16,16) >>> elapsed 0.045535 sec
下图展示了不同配置的性能;
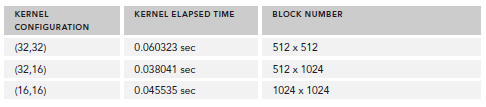
关于性能的分析将在之后的博文中总结,现在只是了解下,本文在于掌握线程组织的方法。
代码下载:CodeSamples.zip
CUDA ---- 线程配置的更多相关文章
- 最优的cuda线程配置
1 每个SM上面失少要有192个激活线程,寄存器写后读的数据依赖才能被掩盖 2 将 寄存器 的bank冲突降到最低,应尽量使每个block含有的线程数是64的倍数 3 block的数量应设置得 ...
- GPU编程自学2 —— CUDA环境配置
深度学习的兴起,使得多线程以及GPU编程逐渐成为算法工程师无法规避的问题.这里主要记录自己的GPU自学历程. 目录 <GPU编程自学1 -- 引言> <GPU编程自学2 -- CUD ...
- Tomcat 内存和线程配置优化
1. tomcat 的线程配置参数详情如下: 修改conf/server.xml中的<Connector .../> 节点如下: <Connector port="8080 ...
- 十五、springboot集成定时任务(Scheduling Tasks)(二)之(线程配置)
配置类: /** * 定时任务线程配置 * */ @Configuration public class SchedulerConfig implements SchedulingConfigurer ...
- 【深度学习】在linux和windows下anaconda+pycharm+tensorflow+cuda的配置
在linux和windows下anaconda+pycharm+tensorflow+cuda的配置 在linux和windows下anaconda+pycharm+tensorflow+cuda的配 ...
- OpenCV GPU CUDA OpenCL 配置
首先,正确安装OpenCV,并且通过测试. 我理解GPU的环境配置由3个主要步骤构成. 1. 生成关联文件,即makefile或工程文件 2. 编译生成与使用硬件相关的库文件,包括动态.静态库文件. ...
- CUDA学习笔记(二)——CUDA线程模型
转自:http://blog.sina.com.cn/s/blog_48b9e1f90100fm5b.html 一个grid中的所有线程执行相同的内核函数,通过坐标进行区分.这些线程有两级的坐标,bl ...
- GPU(CUDA)学习日记(十一)------ 深入理解CUDA线程层次以及关于设置线程数的思考
GPU线程以网格(grid)的方式组织,而每个网格中又包含若干个线程块,在G80/GT200系列中,每一个线程块最多可包含512个线程,Fermi架构中每个线程块支持高达1536个线程.同一线程块中的 ...
- 【CUDA】Win10 + VS2017新 CUDA 项目配置
一.新建项目 打开VS2017 → 新建项目 → Win32控制台应用程序 → “空项目”打钩 二.调整配置管理器平台类型 右键项目 → 属性 → 配置管理器 → 全改为“x64” 三.配置生成属性 ...
随机推荐
- java基础设计模式1——单例模式
概念:在应用这个模式时,单例对象的类必须保证只有一个实例存在.许多时候整个系统只需要拥有一个的全局对象,这样有利于我们协调系统整体的行为. 单例模式从实现上可以分为饿汉式单例和懒汉式单例两种,前者天生 ...
- 1-关于单片机通信数据传输(中断发送,大小端,IEEE754浮点型格式,共用体,空闲中断,环形队列)
补充: 程序优化 为避免普通发送和中断发送造成冲突(造成死机,复位重启),printf修改为中断发送 写这篇文章的目的呢,如题目所言,我承认自己是一个程序猿.....应该说很多很多学单片机的对于... ...
- jqgrid 谈谈给表格设置列头事件、行事件、内容事件
往往我们需要给显示的jqgrid表格赋予事件功能,比如:列头事件.行事件.内容事件.需要的效果可能如下: 如你所见,以上的超链接和按钮均是绑定的事件.那分别如何实现这些事件的绑定呢? 一.行事件 行事 ...
- Linux线程的信号量同步
信号量和互斥锁(mutex)的区别:互斥锁只允许一个线程进入临界区,而信号量允许多个线程同时进入临界区. 不多做解释,要使用信号量同步,需要包含头文件semaphore.h. 主要用到的函数: int ...
- 2_C语言中的数据类型 (九)数组
1 数组 1.1 一维数组定义与使用 int array[10];//定义一个一维数组,名字叫array,一共有10个元素,每个元素都是int类型的 array[0] = ...
- vector 去重
1.使用unique函数: sort(v.begin(),v.end()); v.erase(unique(v.begin(), v.end()), v.end()); //unique()函数将重复 ...
- centos7 安装 telnet
https://blog.csdn.net/wfh6732/article/details/55062016/ https://blog.csdn.net/typa01_kk/article/deta ...
- [hdu5503]EarthCup[霍尔定理]
题意 一共 \(n\) 只球队,两两之间会进行一场比赛,赢得一分输不得分,给出每只球队最后的得分,问能否构造每场比赛的输赢情况使得得分成立.多组数据 \(T\le 10,n\le 5\times 10 ...
- Sterling B2B Integrator与SAP交互 - 02 安装配置
系统组成: 1. 服务器OS及硬件: OS: Red Hat Enterprise Linux Server release 6.6 Hardware: Virtual Machine, x86_64 ...
- Linux环境下使用n更新node版本失败的原因与解决
Linux环境为CentOS 6.5 64位,阿里云低配服务器...学生优惠,然而下个月即将过期,真是个悲伤的故事 很久之前就安装了node,但是一直没有进行过升级,近日因为将部分异步代码更新为采用原 ...