pipeline和baseline是什么?
昨天和刚来项目的机器学习小白解释了一边什么baseline 和pipeline,今天在这里总结一下什么是baseline和pipeline。
1.pipeline
1.1 从管道符到pipeline
先从在linux的管道符讲起,
find ./ | grep wqbin | sort
inux体系下的各种命令工具的处理,可以使用管道符作为传递,这是一种良好的接口规范,工具的功能有公共的接口规范,就像流水线一样,一步接着一步。
而我们只需改动每个参数就可以获取我们想要的结果。该过程就被称之管道机制。
一个基础的 机器学习的Pipeline 主要包含了下述 5 个步骤:
- 数据读取
- 数据预处理
- 创建模型
- 评估模型结果
- 模型调参
上5个步骤可以抽象为一个包括多个步骤的流水线式工作,从数据收集开始至输出我们需要的最终结果。
因此,对以上多个步骤、进行抽象建模,简化为流水线式工作流程则存在着可行性,流水线式机器学习比单个步骤独立建模更加高效、易用。
管道机制在机器学习算法中得以应用的根源在于,参数集在新数据集(比如测试集)上的重复使用。
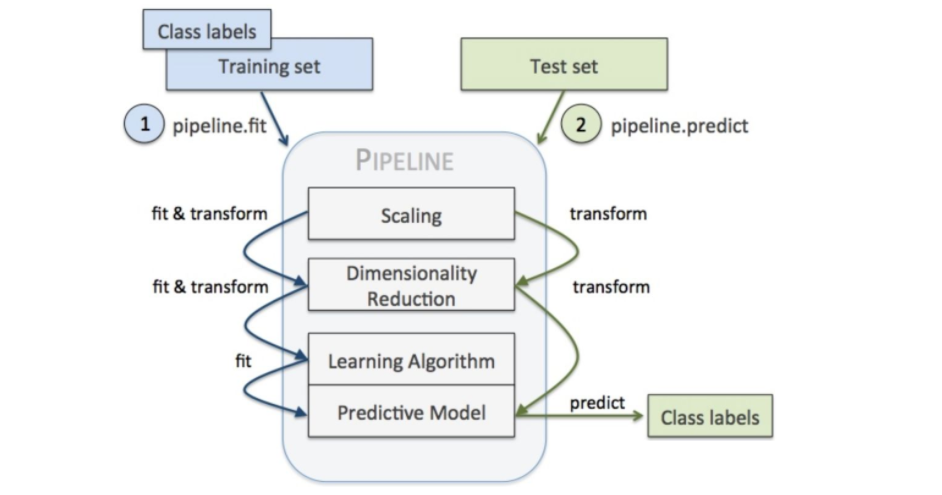
1.2sklearn中pipeline为例
sklearn也遵循pipeline机制,并封装到 sklearn.pipline命名空间下面
pipeline.FeatureUnion(transformer_list[, …]) Concatenates results of multiple transformer objects.
pipeline.Pipeline(steps[, memory]) Pipeline of transforms with a final estimator.
pipeline.make_pipeline(*steps, **kwargs) Construct a Pipeline from the given estimators.
pipeline.make_union(*transformers, **kwargs) Construct a FeatureUnion from the given trans
PIPELINE
sklearn中把机器学习处理过程抽象为estimator,其中estimator都有fit方法,表示数据进行初始化or训练。estimator有2种:
1、特征变换(transformer)
可以理解为特征工程,即:特征标准化、特征正则化、特征离散化、特征平滑、onehot编码等。该类型统一由一个transform方法,用于fit数据之后,输入新的数据,进行特征变换。
2、预测器(predictor)
即各种模型,所有模型fit进行训练之后,都要经过测试集进行predict所有,有一个predict的公共方法。
上面的抽象的好处即可实现机器学习的pipeline,显然特征变换是可能并行的,通过FeatureUnion实现。特征变换在训练集、测试集之间都需要统一,所以pipeline可以达到模块化的目的。举个NLP处理的例子:
# 生成训练数据、测试数据
X_train, X_test, y_train, y_test = train_test_split(X, y) # pipeline定义
pipeline = Pipeline([
('vect', CountVectorizer()),
('tfidf', TfidfTransformer()),
('clf', RandomForestClassifier())
]) # train classifier
pipeline.fit(X_train, y_train) # predict on test data
y_pred = pipeline.predict(X_test)
FEATUREUNION
上面看到特征变换往往需要并行化处理,即FeatureUnion所实现的功能。
pipeline = Pipeline([
('features', FeatureUnion([
('text_pipeline', Pipeline([
('vect', CountVectorizer(tokenizer=tokenize)),
('tfidf', TfidfTransformer())
])),
('findName', FineNameExtractor())
]))
('clf', RandomForestClassifier())
])
pipeline还可以嵌套pipeline,整个机器学习处理流程就像流水工人一样。
上面自定义了一个pipeline处理对象FineNameExtractor,该对象是transformer,自定义一个transformer是很简单的,创建一个对象,继承自BaseEstimator, TransformerMixin即可,
代码如下:
from sklearn.base import BaseEstimator, TransformerMixin
class FineNameExtractor(BaseEstimator, TransformerMixin): def find_name(self, text):
return True def fit(self, X, y=None):
return self def transform(self, X):
X_tagged = pd.Series(X).apply(self.find_name)
return pd.DataFrame(X_tagged)
执行一个PIPELINE,加上自动调参就可以了,sklearn的调参通过GridSearchCV实现=》pipeline+gridsearch。
GridSearchCV实际上也有fit、predict方法,所以,训练与预测高效抽象的,代码很简洁。
2.baseline
pipeline和baseline是什么?的更多相关文章
- One EEG preprocessing pipeline - EEG-fMRI paradigm
The preprocessing pipeline of EEG data from EEG-fMRI paradigm differs from that of regular EEG data, ...
- [Feature] Final pipeline: custom transformers
有视频:https://www.youtube.com/watch?v=BFaadIqWlAg 有代码:https://github.com/jem1031/pandas-pipelines-cust ...
- 等待 Redis 应答 Redis pipeline It's not just a matter of RTT
小结: 1.When pipelining is used, many commands are usually read with a single read() system call, and ...
- redis大幅性能提升之使用管道(PipeLine)和批量(Batch)操作
前段时间在做用户画像的时候,遇到了这样的一个问题,记录某一个商品的用户购买群,刚好这种需求就可以用到Redis中的Set,key作为productID,value 就是具体的customerid集合, ...
- Building the Testing Pipeline
This essay is a part of my knowledge sharing session slides which are shared for development and qua ...
- Scrapy:为spider指定pipeline
当一个Scrapy项目中有多个spider去爬取多个网站时,往往需要多个pipeline,这时就需要为每个spider指定其对应的pipeline. [通过程序来运行spider],可以通过修改配置s ...
- [函数] Firemonkey Windows 重新计算 Font Baseline
计算字型 Baseline 是一个不常用的函数,但如果想要显示不同大小文字下方对齐,就得用它来计算字型的 Baseline 才行,如果计算不准,显示的文字就会高高低低不整齐. 在 Firemonkey ...
- 图解Netty之Pipeline、channel、Context之间的数据流向。
声明:本文为原创博文,禁止转载. 以下所绘制图形均基于Netty4.0.28版本. 一.connect(outbound类型事件) 当用户调用channel的connect时,会发起一个 ...
- 初识pipeline
1.pipeline的产生 从一个现象说起,有一家咖啡吧生意特别好,每天来的客人络绎不绝,客人A来到柜台,客人B紧随其后,客人C排在客人B后面,客人D排在客人C后面,客人E排在客人D后面,一直排到店面 ...
随机推荐
- Docker不完全使用指南
Docker官方文档:https://docs.docker.com/ 神马是Docker? Docker可以轻松的为任何应用创建一个轻量级的.可移植的.自给自足的容器. 开发者在笔记本上编译测试通过 ...
- jumpserver跳板机(堡垒机)安装
jumpserver跳板机(堡垒机) Jumpserver 是一款由Python编写开源的跳板机(堡垒机)系统,实现了跳板机应有的功能,基于ssh协议来管理,客户端无需安装agent,助力互联网企业 ...
- DOS ftp
C:\>ftp /? 将文件传送到运行 FTP 服务器服务(经常称为后台程序)的计算机以及将文件从该计算机传出.可以交互使用 Ftp. FTP [-v] [-d] [-i] [-n] [-g] ...
- Swoft2.x 小白学习笔记 (一) ---控制器
Swoft通过官方文档进行学习,这里不做介绍,直接上手. 涉及到Swoft方面:(配置.注意的坑) 1.控制器(路由.验证器.中间件) 2.mysql (Model使用).Redis配置及通用池 3 ...
- 购物车以php原生cookie实现
index.php //入口文件 <?php /** * @name index.php * @decs * @author 老猫 <18368091722@163.com> * U ...
- Keepalive+双主
一.建立3台服务器之间ssh互信在mydb1,mydb2,mydb3服务器上分别执行:ssh-keygen -t rsassh-copy-id -i .ssh/id_rsa.pub root@192. ...
- VirtualBox网络之仅主机(Host-Only)网络
https://blog.csdn.net/dkfajsldfsdfsd/article/details/79441874
- ASP.NET_正则表达式_匹配HTML中的一行或多行
一.匹配数字串/flash/([0-9]+).htm 二.匹配不含双引号的字符串<p class=\"w490\">([^\"]+)</p> 三. ...
- SQL SERVER 语法
1.获取所有用户名: Select name FROM Sysusers where status='2' and islogin='1' islogin='1' :表示帐户 islogin='0' ...
- 二、maven学习
maven工程运行环境修改 例如maven自带Tomcat6,我们想使用Tomcat7 pom.xml #配置多一个Tomcat7<plugins> <plugin> < ...