潭州课堂25班:Ph201805201 爬虫高级 第十课 Scrapy-redis分布 (课堂笔记)
利用 redis 数据库,做 request 队列,去重,多台数据共享,
scrapy 调度 基于文件每户,默认只能在单机运行,
scrapy-redis 默认把数据放到 redis 中,实现数据共享,
安装: pip install scrapy-redis
命令与 scrapy 没有不同

在该文件下导入 scrapy_redis

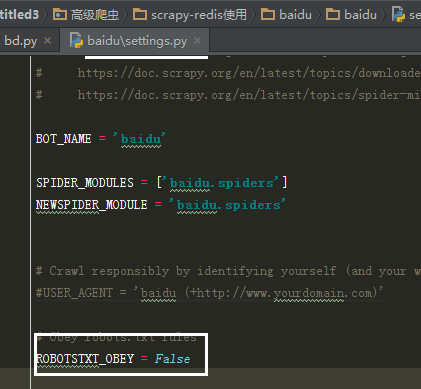
在配置文件中添加内容
1(必须). 使用了scrapy_redis的去重组件,在redis数据库里做去重
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
2(必须). 使用了scrapy_redis的调度器,在redis里分配请求
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
3(可选). 在redis中保持scrapy-redis用到的各个队列,从而True允许暂停和暂停后恢复,也就是不清理redis queues
SCHEDULER_PERSIST = True
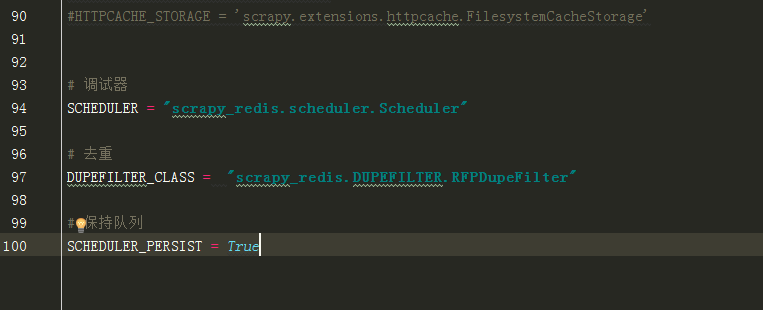
4(必须). 通过配置RedisPipeline将item写入key为 spider.name : items 的redis的list中,供后面的分布式处理item
这个已经由 scrapy-redis 实现,不需要我们写代码,直接使用即可
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 100
}
5(必须). 指定redis数据库的连接参数
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379
这里要改下

改成
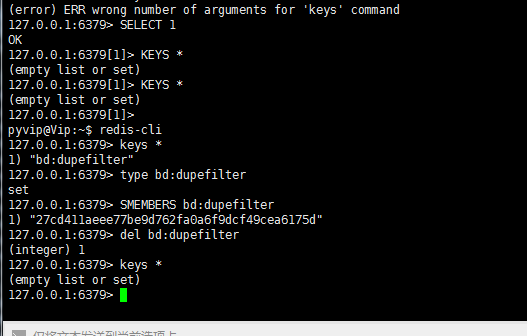

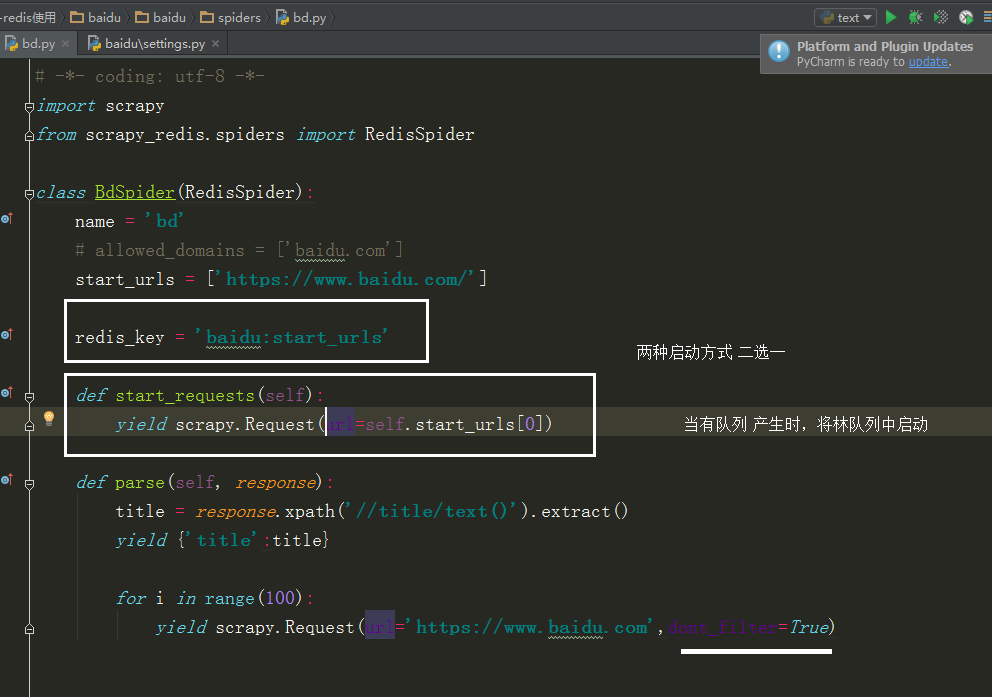
当选择 redis_key 启动时,会从 redis 中获取 url
所以在 redis 中用到下面这个命令,才会启动

redis 中查队列

潭州课堂25班:Ph201805201 爬虫高级 第十课 Scrapy-redis分布 (课堂笔记)的更多相关文章
- 潭州课堂25班:Ph201805201 爬虫高级 第十三 课 代理池爬虫检测部分 (课堂笔记)
1,通过爬虫获取代理 ip ,要从多个网站获取,每个网站的前几页2,获取到代理后,开进程,一个继续解析,一个检测代理是否有用 ,引入队列数据共享3,Queue 中存放的是所有的代理,我们要分离出可用的 ...
- 潭州课堂25班:Ph201805201 爬虫高级 第十二 课 Scrapy-redis分布 项目实战 (课堂笔记)
建代理池, 1,获取多个网站的免费代理IP, 2,对免费代理进行检测,>>>>>携带IP进行请求, 3,检测到的可用IP进行存储, 4,实现api接口,方便调用, 5,各 ...
- 潭州课堂25班:Ph201805201 爬虫高级 第十一课 Scrapy-redis分布 项目实战 (课堂笔
- 潭州课堂25班:Ph201805201 爬虫高级 第八课 AP抓包 SCRAPY 的图片处理 (课堂笔记)
装好模拟器设置代理到 Fiddler 中, 代理 IP 是本机 IP, 端口是 8888, 抓包 APP斗鱼 用 format 设置翻页
- 潭州课堂25班:Ph201805201 爬虫高级 第七课 sclapy 框架 爬前程网 (课堂笔)
定时对该网页数据采集,所以每次只爬第一个页面就可以, 创建工程 scrapy startproject qianchen 创建运行文件 cd qianchenscrapy genspider qian ...
- 潭州课堂25班:Ph201805201 爬虫高级 第六课 sclapy 框架 中间建 与selenium对接 (课堂笔记)
因为每次请求得到的响应不一定是正常的, 也可以在中间建中与个类的方法,自动更换头自信,代理Ip, 在设置文件中添加头信息列表, 在中间建中导入刚刚的列表,和随机函数 class UserAgent ...
- 潭州课堂25班:Ph201805201 爬虫高级 第五课 sclapy 框架 日志和 settings 配置 模拟登录(课堂笔记)
当要对一个页面进行多次请求时, 设 dont_filter = True 忽略去重 在 scrapy 框架中模拟登录 创建项目 创建运行文件 设请求头 # -*- coding: utf-8 ...
- 潭州课堂25班:Ph201805201 爬虫高级 第四课 sclapy 框架 crawispider类 (课堂笔记)
以上内容以 spider 类 获取 start_urls 里面的网页 在这里平时只写一个,是个入口,之后 通过 xpath 生成 url,继续请求, crawispider 中 多了个 rules ...
- 潭州课堂25班:Ph201805201 爬虫高级 第三课 sclapy 框架 腾讯 招聘案例 (课堂笔记)
到指定目录下,创建个项目 进到 spiders 目录 创建执行文件,并命名 运行调试 执行代码,: # -*- coding: utf-8 -*- import scrapy from ..items ...
随机推荐
- selenium+python-autoit文件上传
前言 关于非input文件上传,点上传按钮后,这个弹出的windows的控件了,已经跳出三界之外了,不属于selenium的管辖范围(selenium不是万能的,只能操作web上元素).autoit工 ...
- springboot动态多数据源切换
application-test.properties #datasource -- mysql multiple.datasource.master.url=jdbc:mysql://localho ...
- 步步为营-81-HttpModule(再谈Session)
说明:session用于记录数据信息并存放在服务器内存中,但是存在一些问题.例如当使用服务器集群是会出现session丢失等情况.虽然微软提供了一些解决方案(Session进程外存储,或者存到数据库中 ...
- HTTP协议请求头信息和响应头信息
阅读目录 http的请求部分 常用请头信息 常用响应头信息 http的请求部分 基本结构 请求行 GET /test/hello.html HTTP/1.1 消息头(并不是每一次请求都一样) 空行 ...
- 在Ubuntu内制作自己的VOC数据集
一.VOC数据集的简介 PASCAL VOC为图像的识别和分类提供了一整套标准化的优秀数据集,基本上就是目标检测数据集的模板.现在有VOC2007,VOC2012.主要有20个类.而现在主要的模型评估 ...
- 绘制ROC曲线
什么是ROC曲线 ROC曲线是什么意思,书面表述为: "ROC 曲线(接收者操作特征曲线)是一种显示分类模型在所有分类阈值下的效果的图表." 好吧,这很不直观.其实就是一个二维曲线 ...
- 谷歌浏览器Software Reporter Tool长时间占用CPU解决办法
什么是Software Reporter Tool Software Reporter Tool是一个Chrome清理工具,用于清理谷歌浏览器中不必要或恶意的扩展,应用程序,劫持开始页面等等.当你安装 ...
- constructor与prototype
在学习JS的面向对象过程中,一直对constructor与prototype感到很迷惑,看了一些博客与书籍,觉得自己弄明白了,现在记录如下: 我们都知道,在JS中有一个function的东西.一般人们 ...
- 学习笔记: 反射应用、原理,完成扩展,emit动态代码
using Ruanmou.DB.Interface; using Ruanmou.DB.MySql; using Ruanmou.DB.SqlServer; using Ruanmou.Model; ...
- 试验IFTTT同步发微博
没啥 测试下同步发微博