潭州课堂25班:Ph201805201 爬虫高级 第五课 sclapy 框架 日志和 settings 配置 模拟登录(课堂笔记)





当要对一个页面进行多次请求时,
设 dont_filter = True 忽略去重
在 scrapy 框架中模拟登录
创建项目

创建运行文件
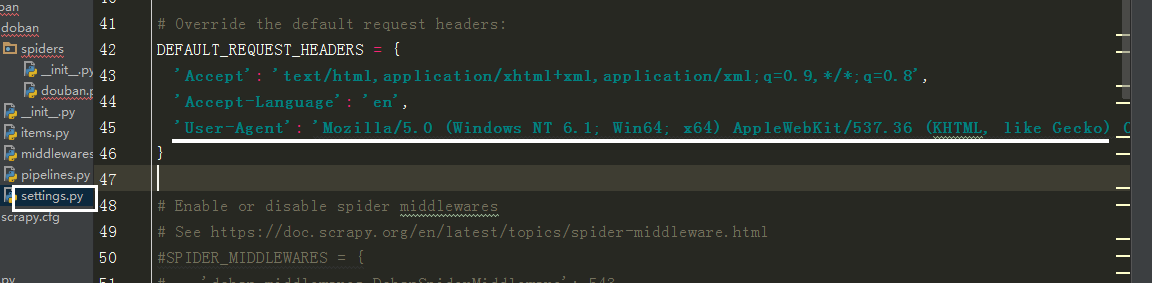
设请求头
# -*- coding: utf-8 -*-
import scrapy
import requests class DoubanSpider(scrapy.Spider):
name = 'douban'
# allowed_domains = ['douban.com']
# 登录页面
start_urls = ['https://accounts.douban.com/login']
log_url = 'https://accounts.douban.com/login'
c_g_url = 'https://www.douban.com/'
def parse(self, response):
# 如果出现验证码
# 验证码
captcha_url = response.xpath('//img[@id="captcha_image"]/@src').extract_first()
# 如果没有验证码
if not captcha_url:
print('没有验证码')
data = {
'source': 'index_nav',
'redir':'https://www.douban.com/people/184159212/',
'form_email': '13605938437',
'form_password': '17906808lmlmlm',
'login':'登录'
}
else:
print('出现验证码')
captcha_id = response.xpath('//input[@name="captcha-id"]/@value').extract_first()
# 下载图片验证码
with open('1.jpg','wb')as f:
f.write(requests.get(captcha_url).content)
captcha_solution = input('>>>>>')
data = {
'source': 'None',
'redir':'https://www.douban.com/',
'captcha-solution':captcha_solution,
'captcha-id':captcha_id,
'form_email': '账号',
'form_password': '密码',
'login':'登录'
} # 返回url , 参数 , 回调函数
yield scrapy.FormRequest(url=self.log_url,formdata=data,callback=self.login_after) def login_after(self,response):
# 判断是否登录成功
text ={
'ck': '7nL_',
'comment':' 哈哈....哈哈....哈哈....'
}
name = response.xpath('//*[@id="db-global-nav"]/div/div[1]/ul/li[2]/a/span[1]//text()').extract()
if name:
print('登录成功,当前用户是%s'%name)
yield scrapy.FormRequest(url=self.c_g_url,formdata=text)
else:print('登录失败')
潭州课堂25班:Ph201805201 爬虫高级 第五课 sclapy 框架 日志和 settings 配置 模拟登录(课堂笔记)的更多相关文章
- 潭州课堂25班:Ph201805201 爬虫高级 第七课 sclapy 框架 爬前程网 (课堂笔)
定时对该网页数据采集,所以每次只爬第一个页面就可以, 创建工程 scrapy startproject qianchen 创建运行文件 cd qianchenscrapy genspider qian ...
- 潭州课堂25班:Ph201805201 爬虫高级 第六课 sclapy 框架 中间建 与selenium对接 (课堂笔记)
因为每次请求得到的响应不一定是正常的, 也可以在中间建中与个类的方法,自动更换头自信,代理Ip, 在设置文件中添加头信息列表, 在中间建中导入刚刚的列表,和随机函数 class UserAgent ...
- 潭州课堂25班:Ph201805201 爬虫高级 第四课 sclapy 框架 crawispider类 (课堂笔记)
以上内容以 spider 类 获取 start_urls 里面的网页 在这里平时只写一个,是个入口,之后 通过 xpath 生成 url,继续请求, crawispider 中 多了个 rules ...
- 潭州课堂25班:Ph201805201 爬虫高级 第三课 sclapy 框架 腾讯 招聘案例 (课堂笔记)
到指定目录下,创建个项目 进到 spiders 目录 创建执行文件,并命名 运行调试 执行代码,: # -*- coding: utf-8 -*- import scrapy from ..items ...
- 潭州课堂25班:Ph201805201 爬虫高级 第十三 课 代理池爬虫检测部分 (课堂笔记)
1,通过爬虫获取代理 ip ,要从多个网站获取,每个网站的前几页2,获取到代理后,开进程,一个继续解析,一个检测代理是否有用 ,引入队列数据共享3,Queue 中存放的是所有的代理,我们要分离出可用的 ...
- 潭州课堂25班:Ph201805201 爬虫高级 第十一课 Scrapy-redis分布 项目实战 (课堂笔
- 潭州课堂25班:Ph201805201 爬虫高级 第十课 Scrapy-redis分布 (课堂笔记)
利用 redis 数据库,做 request 队列,去重,多台数据共享, scrapy 调度 基于文件每户,默认只能在单机运行, scrapy-redis 默认把数据放到 redis 中,实现数据共享 ...
- 潭州课堂25班:Ph201805201 爬虫高级 第八课 AP抓包 SCRAPY 的图片处理 (课堂笔记)
装好模拟器设置代理到 Fiddler 中, 代理 IP 是本机 IP, 端口是 8888, 抓包 APP斗鱼 用 format 设置翻页
- 潭州课堂25班:Ph201805201 爬虫基础 第五课 (案例) 豆瓣分析 (课堂笔记)
动态讲求 , 翻页参数: # -*- coding: utf-8 -*- # 斌彬电脑 # @Time : 2018/9/1 0001 3:44 import requests,json class ...
随机推荐
- lxde 的安装和卸载以及注意事项,lubuntu
安装: $ sudo apt install lxde $ sudo apt install lxde-common 安装完毕后,可能没法关机及logout,可以使用如下安装: $ sudo apt ...
- nodejs async series 小白向
async.series({ flag1:function(done){ //flag1 是一个流程标识,用户自定义 //逻辑处理 done(null,"返回结果&qu ...
- springboot系列十三、springboot集成swaggerUI
一.Swagger介绍 Swagger能成为最受欢迎的REST APIs文档生成工具之一,有以下几个原因: Swagger 可以生成一个具有互动性的API控制台,开发者可以用来快速学习和尝试API. ...
- C++编程命名规则
原文地址:http://www.cnblogs.com/ggjucheng/archive/2011/12/15/2289291.html 如果想要有效的管理一个稍微复杂一点的体系,针对其中事物的一套 ...
- C++经典面试题(最全,面中率最高)
C++经典面试题(最全,面中率最高) 1.new.delete.malloc.free关系 delete会调用对象的析构函数,和new对应free只会释放内存,new调用构造函数.malloc与fre ...
- saltstack自动化运维系列⑩SaltStack二次开发初探
saltstack自动化运维系列⑩SaltStack二次开发初探 1.当salt运行在公网或者网络环境较差的条件下,需要配置timeout时间vim /etc/salt/master timeout: ...
- asp.net core 2.0 api ajax跨域问题
API配置: services.AddCors(options => { options.AddPolicy("any", builder => { builder.W ...
- hdu5256 二分求LIS+思维
解题的思路很巧,为了让每个数之间都留出对应的上升空间,使a[i]=a[i]-i,然后再求LIS 另外二分求LIS是比较快的 #include<bits/stdc++.h> #define ...
- brew装snappy
brew装snappy,我在mac上已经开了socks5代理,也尝试了lantern或者duotai.org,结果都下载不动. 解决方法:把snappy包手动从浏览器下载,然后放到缓存目录,再执行br ...
- DDD领域模型AutoMapper实现DTO(七)
DTO的应用场景: 定义产品类: public class Product { public string ProductName { get; set; } public decimal Produ ...