潭州课堂25班:Ph201805201 爬虫高级 第三课 sclapy 框架 腾讯 招聘案例 (课堂笔记)
到指定目录下,创建个项目
进到 spiders 目录 创建执行文件,并命名
运行调试
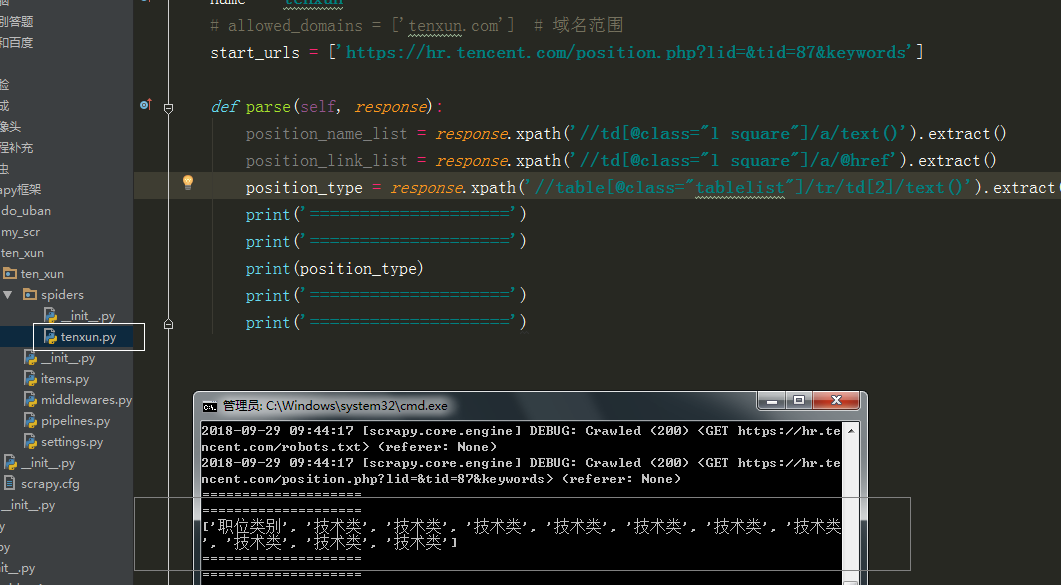
执行代码,:
# -*- coding: utf-8 -*-
import scrapy
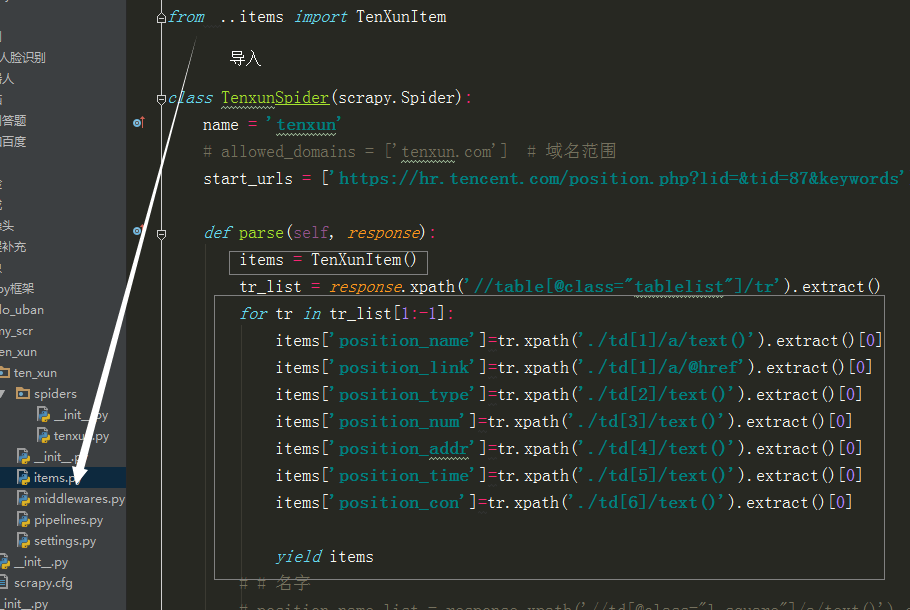
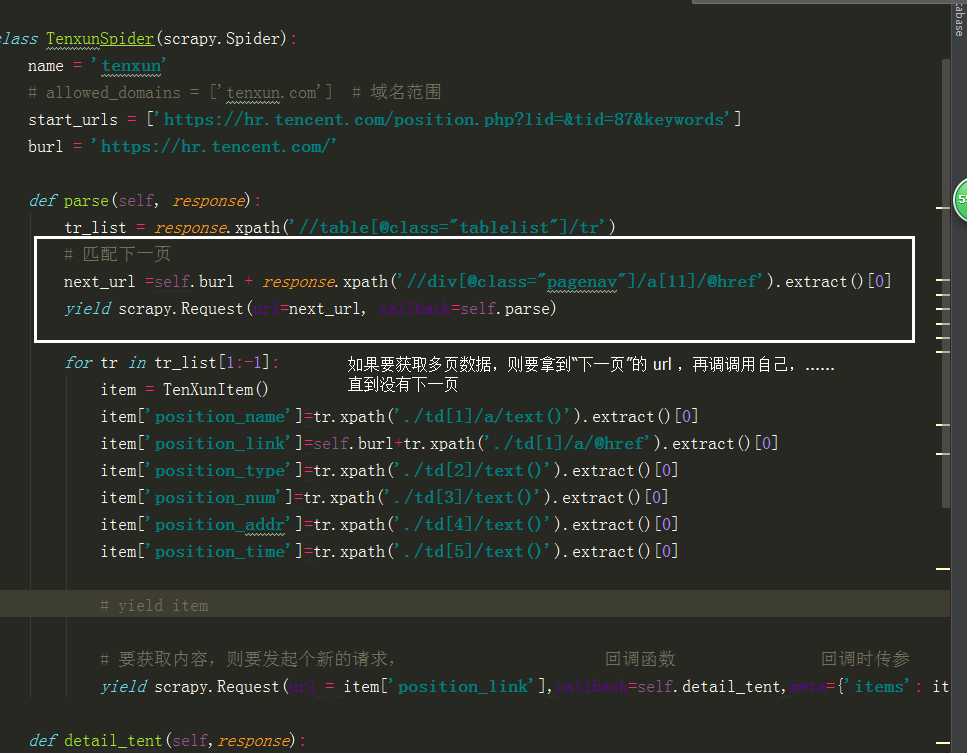
from ..items import TenXunItem class TenxunSpider(scrapy.Spider):
name = 'tenxun'
# allowed_domains = ['tenxun.com'] # 域名范围
start_urls = ['https://hr.tencent.com/position.php?lid=&tid=87&keywords']
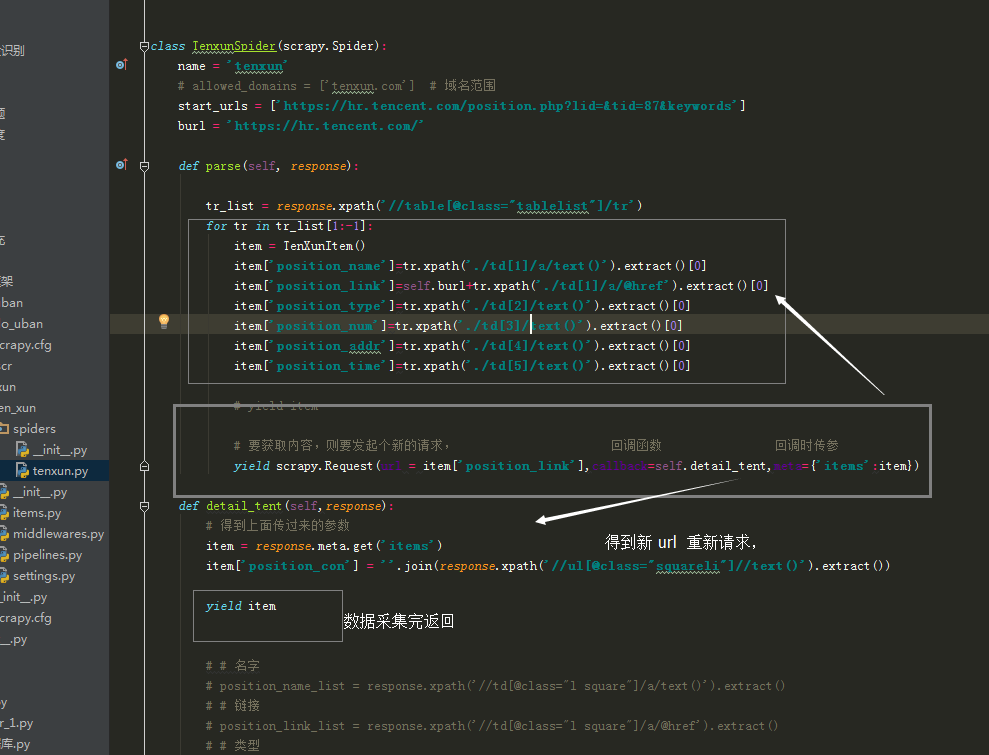
burl = 'https://hr.tencent.com/' def parse(self, response):
tr_list = response.xpath('//table[@class="tablelist"]/tr')
for tr in tr_list[1:-1]:
item = TenXunItem()
item['position_name']=tr.xpath('./td[1]/a/text()').extract()[0]
item['position_link']=self.burl+tr.xpath('./td[1]/a/@href').extract()[0]
item['position_type']=tr.xpath('./td[2]/text()').extract()[0]
item['position_num']=tr.xpath('./td[3]/text()').extract()[0]
item['position_addr']=tr.xpath('./td[4]/text()').extract()[0]
item['position_time']=tr.xpath('./td[5]/text()').extract()[0] # yield item # 匹配下一页
next_url =self.burl + response.xpath('//div[@class="pagenav"]/a[11]/@href').extract()[0]
yield scrapy.Request(url=next_url, callback=self.parse) # 要获取内容,则要发起个新的请求, 回调函数 回调时传参
yield scrapy.Request(url = item['position_link'],callback=self.detail_tent,meta={'items': item}) def detail_tent(self,response):
# 得到上面传过来的参数
item = response.meta.get('items')
item['position_con'] = ''.join(response.xpath('//ul[@class="squareli"]//text()').extract()) yield item # # 名字
# position_name_list = response.xpath('//td[@class="l square"]/a/text()').extract()
# # 链接
# position_link_list = response.xpath('//td[@class="l square"]/a/@href').extract()
# # 类型
# position_type_list = response.xpath('//table[@class="tablelist"]/tr/td[2]/text()').extract()
# # 人数
# position_num_list = response.xpath('//table[@class="tablelist"]/tr/td[3]/text()').extract()
# print('====================')
# print('====================')
# print(self.burl + tr_list[2].xpath('./td[1]/a/@href').extract()[0])
# print('====================')
# print('====================')
pipelines.py
# -*- coding: utf-8 -*- # Define your item pipelines here
#
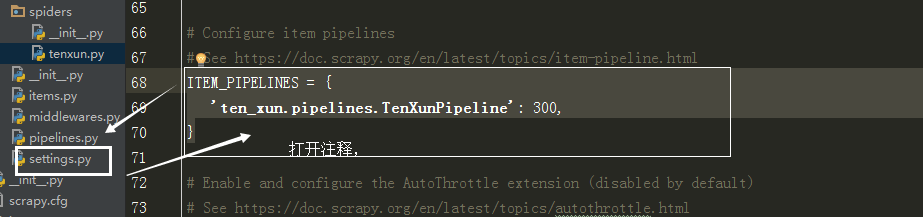
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://doc.scrapy.org/en/latest/topics/item-pipeline.html
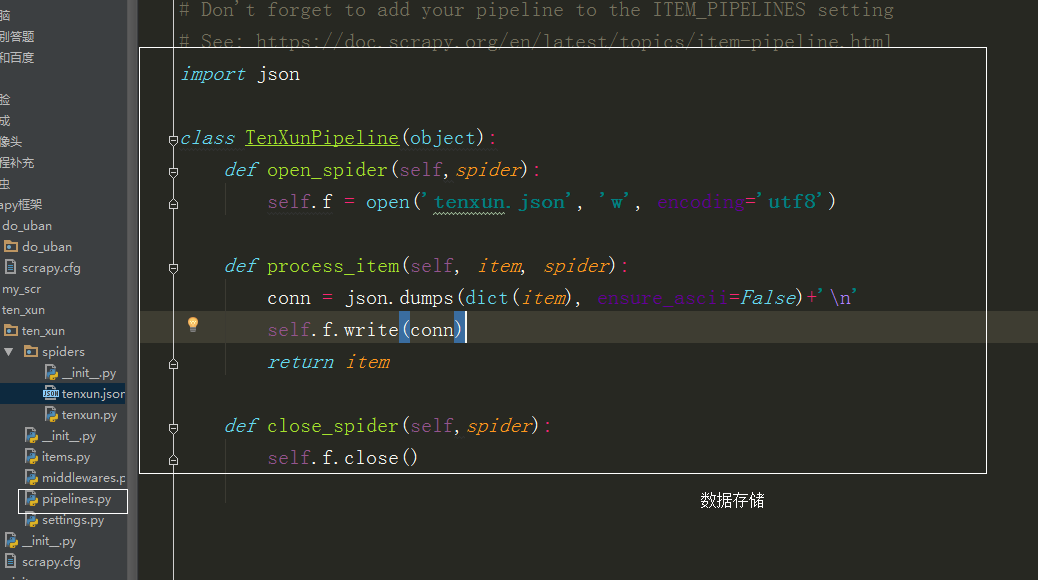
import json class TenXunPipeline(object):
def open_spider(self,spider):
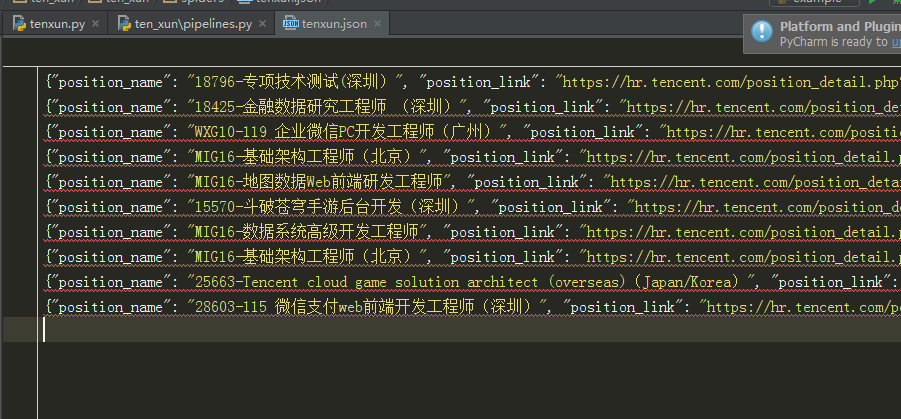
self.f = open('tenxun.json', 'w', encoding='utf8') def process_item(self, item, spider):
conn = json.dumps(dict(item), ensure_ascii=False)+'\n'
self.f.write(conn)
return item def close_spider(self,spider):
self.f.close()
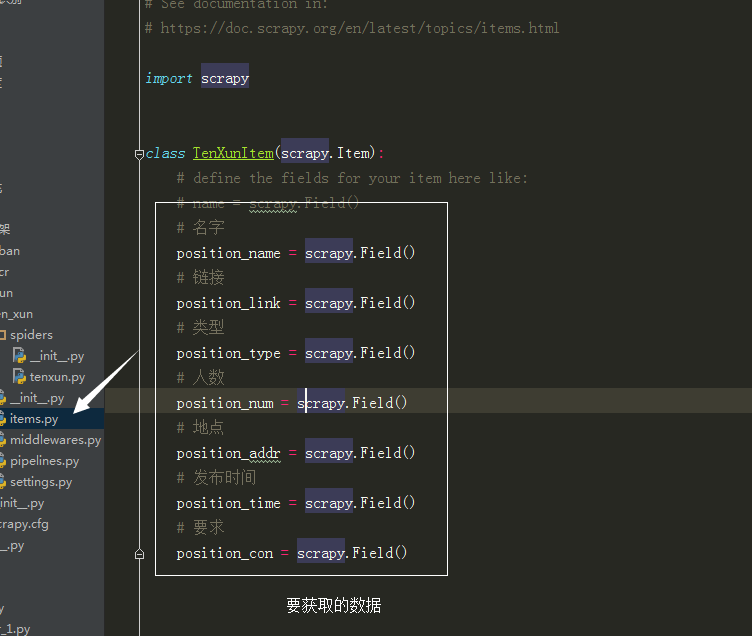
items.py
# -*- coding: utf-8 -*- # Define here the models for your scraped items
#
# See documentation in:
# https://doc.scrapy.org/en/latest/topics/items.html import scrapy class TenXunItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# 名字
print('00000000000000001111111111111111')
position_name = scrapy.Field()
# 链接
position_link = scrapy.Field()
# 类型
position_type = scrapy.Field()
# 人数
position_num = scrapy.Field()
# 地点
position_addr = scrapy.Field()
# 发布时间
position_time = scrapy.Field()
# 要求
position_con = scrapy.Field()
存入数据库:
潭州课堂25班:Ph201805201 爬虫高级 第三课 sclapy 框架 腾讯 招聘案例 (课堂笔记)的更多相关文章
- 潭州课堂25班:Ph201805201 爬虫高级 第七课 sclapy 框架 爬前程网 (课堂笔)
定时对该网页数据采集,所以每次只爬第一个页面就可以, 创建工程 scrapy startproject qianchen 创建运行文件 cd qianchenscrapy genspider qian ...
- 潭州课堂25班:Ph201805201 爬虫高级 第六课 sclapy 框架 中间建 与selenium对接 (课堂笔记)
因为每次请求得到的响应不一定是正常的, 也可以在中间建中与个类的方法,自动更换头自信,代理Ip, 在设置文件中添加头信息列表, 在中间建中导入刚刚的列表,和随机函数 class UserAgent ...
- 潭州课堂25班:Ph201805201 爬虫高级 第五课 sclapy 框架 日志和 settings 配置 模拟登录(课堂笔记)
当要对一个页面进行多次请求时, 设 dont_filter = True 忽略去重 在 scrapy 框架中模拟登录 创建项目 创建运行文件 设请求头 # -*- coding: utf-8 ...
- 潭州课堂25班:Ph201805201 爬虫高级 第四课 sclapy 框架 crawispider类 (课堂笔记)
以上内容以 spider 类 获取 start_urls 里面的网页 在这里平时只写一个,是个入口,之后 通过 xpath 生成 url,继续请求, crawispider 中 多了个 rules ...
- 潭州课堂25班:Ph201805201 爬虫高级 第十三 课 代理池爬虫检测部分 (课堂笔记)
1,通过爬虫获取代理 ip ,要从多个网站获取,每个网站的前几页2,获取到代理后,开进程,一个继续解析,一个检测代理是否有用 ,引入队列数据共享3,Queue 中存放的是所有的代理,我们要分离出可用的 ...
- 潭州课堂25班:Ph201805201 爬虫高级 第十一课 Scrapy-redis分布 项目实战 (课堂笔
- 潭州课堂25班:Ph201805201 爬虫高级 第十课 Scrapy-redis分布 (课堂笔记)
利用 redis 数据库,做 request 队列,去重,多台数据共享, scrapy 调度 基于文件每户,默认只能在单机运行, scrapy-redis 默认把数据放到 redis 中,实现数据共享 ...
- 潭州课堂25班:Ph201805201 爬虫高级 第八课 AP抓包 SCRAPY 的图片处理 (课堂笔记)
装好模拟器设置代理到 Fiddler 中, 代理 IP 是本机 IP, 端口是 8888, 抓包 APP斗鱼 用 format 设置翻页
- 潭州课堂25班:Ph201805201 爬虫基础 第三课 urllib (课堂笔记)
Python网络请求urllib和urllib3详解 urllib是Python中请求url连接的官方标准库,在Python2中主要为urllib和urllib2,在Python3中整合成了url ...
随机推荐
- Django 查询集简述
通过模型中的管理器构造一个查询集(QuerySet),来从数据库中获取对象.查询集表示从数据库中取出来的对象的集合.它可以含有零个.一个或者多个过滤器.过滤器基于所给的参数限制查询的结果. 从SQL ...
- Windows系统FTP Shell
ftp open 10.0.0.0.2 21101 user passwd ls cd pwd delete get /home/err.log Error.log put err.log /home ...
- mysql分组排序取最大值所在行,类似hive中row_number() over partition by
如下图, 计划实现 :按照 parent_code 分组, 取组中code最大值所在的整条记录,如红色部分.(类似hive中: row_number() over(partition by)) sel ...
- Github之协同开发
一.协同开发 1.引子:假如三个人共同开发同一份代码,每个人都各自安排了任务,当每个人都完成了一半的时候,提交不提交呢? 要提交,提交到dev吗,都上传了一半,这样回家拿出来的代码根本跑不起来.所以, ...
- php协程
多任务 (并行和并发) 在讲协程之前,先谈谈多进程.多线程.并行和并发. 对于单核处理器,多进程实现多任务的原理是让操作系统给一个任务每次分配一定的 CPU 时间片,然后中断.让下一个任务执行一定的时 ...
- (一)什么是webservice?
第一节: 第一节:Webservice 简介 第二节: 第二节:CXF 简介 webservice 有的人一看到这个,估计会认为这个是一种新技术,一种新框架. 其实不是,严格的说,webservice ...
- js中字符串概念
字符串概念:所有带单引号和双引号的叫做字符串 字符串的数据类型:字符串既是基本数据类型,又是复合数据类型. 字符串存储在内存里[只读数据段]的地方.字符串的变量里存储的是字符串的地址. [注]使用起来 ...
- 更好用的cmd窗口
cmder是windows下的命令行工具,用来替代windows自带的cmd. 下载地址 下载后自建文件夹并解压,将Cmder.exe所在文件夹路径加入path, windows + r 键入cmde ...
- python 全栈开发,Day89(sorted面试题,Pycharm配置支持vue语法,Vue基础语法,小清单练习)
一.sorted面试题 面试题: [11, 33, 4, 2, 11, 4, 9, 2] 去重并保持原来的顺序 答案1: list1 = [11, 33, 4, 2, 11, 4, 9, 2] ret ...
- curl 命令模拟 HTTP GET/POST 请求
https://www.cnblogs.com/alfred0311/p/7988648.html