Apache Spark源码走读之23 -- Spark MLLib中拟牛顿法L-BFGS的源码实现
欢迎转载,转载请注明出处,徽沪一郎。
概要
本文就拟牛顿法L-BFGS的由来做一个简要的回顾,然后就其在spark mllib中的实现进行源码走读。
拟牛顿法
数学原理









代码实现
L-BFGS算法中使用到的正则化方法是SquaredL2Updater。
算法实现上使用到了由scalanlp的成员项目breeze库中的BreezeLBFGS函数,mllib中自定义了BreezeLBFGS所需要的DiffFunctions.
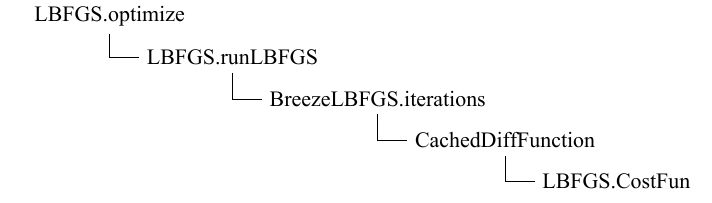
runLBFGS函数的源码实现如下
def runLBFGS(
data: RDD[(Double, Vector)],
gradient: Gradient,
updater: Updater,
numCorrections: Int,
convergenceTol: Double,
maxNumIterations: Int,
regParam: Double,
initialWeights: Vector): (Vector, Array[Double]) = {
val lossHistory = new ArrayBuffer[Double](maxNumIterations)
val numExamples = data.count()
val costFun =
new CostFun(data, gradient, updater, regParam, numExamples)
val lbfgs = new BreezeLBFGS[BDV[Double]](maxNumIterations, numCorrections, convergenceTol)
val states =
lbfgs.iterations(new CachedDiffFunction(costFun), initialWeights.toBreeze.toDenseVector)
/**
* NOTE: lossSum and loss is computed using the weights from the previous iteration
* and regVal is the regularization value computed in the previous iteration as well.
*/
var state = states.next()
while(states.hasNext) {
lossHistory.append(state.value)
state = states.next()
}
lossHistory.append(state.value)
val weights = Vectors.fromBreeze(state.x)
logInfo("LBFGS.runLBFGS finished. Last 10 losses %s".format(
lossHistory.takeRight(10).mkString(", ")))
(weights, lossHistory.toArray)
}
costFun函数是算法实现中的重点
private class CostFun(
data: RDD[(Double, Vector)],
gradient: Gradient,
updater: Updater,
regParam: Double,
numExamples: Long) extends DiffFunction[BDV[Double]] {
private var i = 0
override def calculate(weights: BDV[Double]) = {
// Have a local copy to avoid the serialization of CostFun object which is not serializable.
val localData = data
val localGradient = gradient
val (gradientSum, lossSum) = localData.aggregate((BDV.zeros[Double](weights.size), 0.0))(
seqOp = (c, v) => (c, v) match { case ((grad, loss), (label, features)) =>
val l = localGradient.compute(
features, label, Vectors.fromBreeze(weights), Vectors.fromBreeze(grad))
(grad, loss + l)
},
combOp = (c1, c2) => (c1, c2) match { case ((grad1, loss1), (grad2, loss2)) =>
(grad1 += grad2, loss1 + loss2)
})
/**
* regVal is sum of weight squares if it's L2 updater;
* for other updater, the same logic is followed.
*/
val regVal = updater.compute(
Vectors.fromBreeze(weights),
Vectors.dense(new Array[Double](weights.size)), 0, 1, regParam)._2
val loss = lossSum / numExamples + regVal
/**
* It will return the gradient part of regularization using updater.
*
* Given the input parameters, the updater basically does the following,
*
* w' = w - thisIterStepSize * (gradient + regGradient(w))
* Note that regGradient is function of w
*
* If we set gradient = 0, thisIterStepSize = 1, then
*
* regGradient(w) = w - w'
*
* TODO: We need to clean it up by separating the logic of regularization out
* from updater to regularizer.
*/
// The following gradientTotal is actually the regularization part of gradient.
// Will add the gradientSum computed from the data with weights in the next step.
val gradientTotal = weights - updater.compute(
Vectors.fromBreeze(weights),
Vectors.dense(new Array[Double](weights.size)), 1, 1, regParam)._1.toBreeze
// gradientTotal = gradientSum / numExamples + gradientTotal
axpy(1.0 / numExamples, gradientSum, gradientTotal)
i += 1
(loss, gradientTotal)
}
}
}
Apache Spark源码走读之23 -- Spark MLLib中拟牛顿法L-BFGS的源码实现的更多相关文章
- Apache Spark源码走读之16 -- spark repl实现详解
欢迎转载,转载请注明出处,徽沪一郎. 概要 之所以对spark shell的内部实现产生兴趣全部缘于好奇代码的编译加载过程,scala是需要编译才能执行的语言,但提供的scala repl可以实现代码 ...
- Apache Spark源码走读之9 -- Spark源码编译
欢迎转载,转载请注明出处,徽沪一郎. 概要 本来源码编译没有什么可说的,对于java项目来说,只要会点maven或ant的简单命令,依葫芦画瓢,一下子就ok了.但到了Spark上面,事情似乎不这么简单 ...
- Apache Spark源码走读之8 -- Spark on Yarn
欢迎转载,转载请注明出处,徽沪一郎. 概要 Hadoop2中的Yarn是一个分布式计算资源的管理平台,由于其有极好的模型抽象,非常有可能成为分布式计算资源管理的事实标准.其主要职责将是分布式计算集群的 ...
- Apache Spark源码走读之1 -- Spark论文阅读笔记
欢迎转载,转载请注明出处,徽沪一郎. 楔子 源码阅读是一件非常容易的事,也是一件非常难的事.容易的是代码就在那里,一打开就可以看到.难的是要通过代码明白作者当初为什么要这样设计,设计之初要解决的主要问 ...
- twitter storm源码走读之4 -- worker进程中线程的分类及用途
欢迎转载,转载请注明出版,徽沪一郎. 本文重点分析storm的worker进程在正常启动之后有哪些类型的线程,针对每种类型的线程,剖析其用途及消息的接收与发送流程. 概述 worker进程启动过程中最 ...
- Apache Spark源码走读之7 -- Standalone部署方式分析
欢迎转载,转载请注明出处,徽沪一郎. 楔子 在Spark源码走读系列之2中曾经提到Spark能以Standalone的方式来运行cluster,但没有对Application的提交与具体运行流程做详细 ...
- Apache Spark源码走读之13 -- hiveql on spark实现详解
欢迎转载,转载请注明出处,徽沪一郎 概要 在新近发布的spark 1.0中新加了sql的模块,更为引人注意的是对hive中的hiveql也提供了良好的支持,作为一个源码分析控,了解一下spark是如何 ...
- Apache Spark源码走读之22 -- 浅谈mllib中线性回归的算法实现
欢迎转载,转载请注明出处,徽沪一郎. 概要 本文简要描述线性回归算法在Spark MLLib中的具体实现,涉及线性回归算法本身及线性回归并行处理的理论基础,然后对代码实现部分进行走读. 线性回归模型 ...
- Apache Spark源码走读之15 -- Standalone部署模式下的容错性分析
欢迎转载,转载请注明出处,徽沪一郎. 概要 本文就standalone部署方式下的容错性问题做比较细致的分析,主要回答standalone部署方式下的包含哪些主要节点,当某一类节点出现问题时,系统是如 ...
随机推荐
- 深圳浩瀚技术有限公司(haohantech)推出的无线移动批发管理PDA解决方案------无线移动POS销售开单系统
办好大型行业展会/交易会使其发挥强大的营销广告宣传作用从而为企业带来巨大的经济效益是每个参展企业的美好愿望. 由于行业内有影响力的展会每年屈指可数, 甚至很多情况下每年就只有一到两次, 如果没能够很好 ...
- redis 的安装
1: redis 是什么 Redis is an open source (BSD licensed), in-memory data structure store, used as databas ...
- 解决js(ajax)提交后端的“ _xsrf' argument missing from POST” 的错误
首先先简述一下CSRF: CSRF是Cross Site Request Forgery的缩写(也缩写为XSRF),直译过来就是跨站请求伪造的意思,也就是在用户会话下对某个CGI做一些GET/POST ...
- 使用 Velocity 模板引擎快速生成代码
http://www.ibm.com/developerworks/cn/java/j-lo-velocity1/
- (转)POJ题目分类
初期:一.基本算法: (1)枚举. (poj1753,poj2965) (2)贪心(poj1328,poj2109,poj2586) (3)递归和分治法. (4)递推. ...
- BZOJ 2733 & splay的合并
题意: 带权联通块,添边与查询联通块中第k大. SOL: splay合并+并查集. 我以为splay可以用奇技淫巧来简单合并...调了一下午终于幡然醒悟...于是就只好一个一个慢慢插...什么启发式合 ...
- Android -- 自定义ProgressBar图片
注:所有的进度条都要配置 android:indeterminate="false" android:indeterminateDrawable="样式文件 ...
- jQuery 循环问题
$("#add2sub").click(function(){ var $sxarr=$(".add_shuxing_ul > .sx_add_bg"); ...
- osgearth_city例子总结
osgearth_city例子总结 转自:http://blog.csdn.net/taor1/article/details/8242480 int main(int argc, char** ar ...
- winform退出或关闭窗体时弹窗提示代码:转
winform退出或关闭窗体时弹窗提示代码,当我们点击窗体的 X 按钮时,会弹出一个对话框,询问我们是直接退出,还是最小化到托盘,还是取消这个行为.或是是否保存当前修改等等.以下以最小化到托盘为例. ...