Java集合---ConcurrentHashMap原理分析
一、背景:
线程不安全的HashMap
效率低下的HashTable容器
锁分段技术
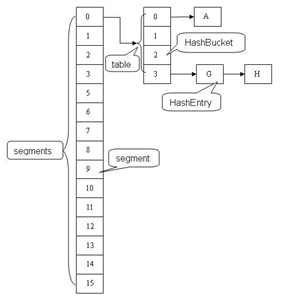
二、应用场景
三、源码解读
/**
* The segments, each of which is a specialized hash table
*/
final Segment<K,V>[] segments;
不变(Immutable)和易变(Volatile)
static final class HashEntry<K,V> {
final K key;
final int hash;
volatile V value;
final HashEntry<K,V> next;
}
其它
定位操作:
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
final Segment<K,V> segmentFor(int hash) {
return segments[(hash >>> segmentShift) & segmentMask];
}
数据结构
static final class Segment<K,V> extends ReentrantLock implements Serializable {
/**
* The number of elements in this segment's region.
*/
transient volatileint count;
/**
* Number of updates that alter the size of the table. This is
* used during bulk-read methods to make sure they see a
* consistent snapshot: If modCounts change during a traversal
* of segments computing size or checking containsValue, then
* we might have an inconsistent view of state so (usually)
* must retry.
*/
transient int modCount;
/**
* The table is rehashed when its size exceeds this threshold.
* (The value of this field is always <tt>(int)(capacity *
* loadFactor)</tt>.)
*/
transient int threshold;
/**
* The per-segment table.
*/
transient volatile HashEntry<K,V>[] table;
/**
* The load factor for the hash table. Even though this value
* is same for all segments, it is replicated to avoid needing
* links to outer object.
* @serial
*/
final float loadFactor;
}
删除操作remove(key)
public V remove(Object key) {
hash = hash(key.hashCode());
return segmentFor(hash).remove(key, hash, null);
}
V remove(Object key, int hash, Object value) {
lock();
try {
int c = count - 1;
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue = null;
if (e != null) {
V v = e.value;
if (value == null || value.equals(v)) {
oldValue = v;
// All entries following removed node can stay
// in list, but all preceding ones need to be
// cloned.
++modCount;
HashEntry<K,V> newFirst = e.next;
*for (HashEntry<K,V> p = first; p != e; p = p.next)
*newFirst = new HashEntry<K,V>(p.key, p.hash,
newFirst, p.value);
tab[index] = newFirst;
count = c; // write-volatile
}
}
return oldValue;
} finally {
unlock();
}
}


get操作
V get(Object key, int hash) {
if (count != 0) { // read-volatile 当前桶的数据个数是否为0
HashEntry<K,V> e = getFirst(hash); 得到头节点
while (e != null) {
if (e.hash == hash && key.equals(e.key)) {
V v = e.value;
if (v != null)
return v;
return readValueUnderLock(e); // recheck
}
e = e.next;
}
}
returnnull;
}
V readValueUnderLock(HashEntry<K,V> e) {
lock();
try {
return e.value;
} finally {
unlock();
}
}
put操作
V put(K key, int hash, V value, boolean onlyIfAbsent) {
lock();
try {
int c = count;
if (c++ > threshold) // ensure capacity
rehash();
HashEntry<K,V>[] tab = table;
int index = hash & (tab.length - 1);
HashEntry<K,V> first = tab[index];
HashEntry<K,V> e = first;
while (e != null && (e.hash != hash || !key.equals(e.key)))
e = e.next;
V oldValue;
if (e != null) {
oldValue = e.value;
if (!onlyIfAbsent)
e.value = value;
}
else {
oldValue = null;
++modCount;
tab[index] = new HashEntry<K,V>(key, hash, first, value);
count = c; // write-volatile
}
return oldValue;
} finally {
unlock();
}
}
- 是否需要扩容。在插入元素前会先判断Segment里的HashEntry数组是否超过容量(threshold),如果超过阀值,数组进行扩容。值得一提的是,Segment的扩容判断比HashMap更恰当,因为HashMap是在插入元素后判断元素是否已经到达容量的,如果到达了就进行扩容,但是很有可能扩容之后没有新元素插入,这时HashMap就进行了一次无效的扩容。
- 如何扩容。扩容的时候首先会创建一个两倍于原容量的数组,然后将原数组里的元素进行再hash后插入到新的数组里。为了高效ConcurrentHashMap不会对整个容器进行扩容,而只对某个segment进行扩容。
boolean containsKey(Object key, int hash) {
if (count != 0) { // read-volatile
HashEntry<K,V> e = getFirst(hash);
while (e != null) {
if (e.hash == hash && key.equals(e.key))
returntrue;
e = e.next;
}
}
returnfalse;
}
size()操作
参考:
Java集合---ConcurrentHashMap原理分析的更多相关文章
- Java 中 ConcurrentHashMap 原理分析
一.Java并发基础 当一个对象或变量可以被多个线程共享的时候,就有可能使得程序的逻辑出现问题. 在一个对象中有一个变量i=0,有两个线程A,B都想对i加1,这个时候便有问题显现出来,关键就是对i加1 ...
- ConcurrentHashMap原理分析(1.7与1.8)-put和 get 需要执行两次Hash
ConcurrentHashMap 与HashMap和Hashtable 最大的不同在于:put和 get 两次Hash到达指定的HashEntry,第一次hash到达Segment,第二次到达Seg ...
- Java 集合源码分析(一)HashMap
目录 Java 集合源码分析(一)HashMap 1. 概要 2. JDK 7 的 HashMap 3. JDK 1.8 的 HashMap 4. Hashtable 5. JDK 1.7 的 Con ...
- java集合源码分析(三):ArrayList
概述 在前文:java集合源码分析(二):List与AbstractList 和 java集合源码分析(一):Collection 与 AbstractCollection 中,我们大致了解了从 Co ...
- java集合源码分析(六):HashMap
概述 HashMap 是 Map 接口下一个线程不安全的,基于哈希表的实现类.由于他解决哈希冲突的方式是分离链表法,也就是拉链法,因此他的数据结构是数组+链表,在 JDK8 以后,当哈希冲突严重时,H ...
- Java Reference核心原理分析
本文转载自Java Reference核心原理分析 导语 带着问题,看源码针对性会更强一点.印象会更深刻.并且效果也会更好.所以我先卖个关子,提两个问题(没准下次跳槽时就被问到). 我们可以用Byte ...
- Java 线程池原理分析
1.简介 线程池可以简单看做是一组线程的集合,通过使用线程池,我们可以方便的复用线程,避免了频繁创建和销毁线程所带来的开销.在应用上,线程池可应用在后端相关服务中.比如 Web 服务器,数据库服务器等 ...
- Java集合源码分析(四)Vector<E>
Vector<E>简介 Vector也是基于数组实现的,是一个动态数组,其容量能自动增长. Vector是JDK1.0引入了,它的很多实现方法都加入了同步语句,因此是线程安全的(其实也只是 ...
- Java集合源码分析(三)LinkedList
LinkedList简介 LinkedList是基于双向循环链表(从源码中可以很容易看出)实现的,除了可以当做链表来操作外,它还可以当做栈.队列和双端队列来使用. LinkedList同样是非线程安全 ...
随机推荐
- 【社工】NodeJS 应用仓库钓鱼
前言 城堡总是从内部攻破的.再强大的系统,也得通过人来控制.如果将入侵直接从人这个环节发起,那么再坚固的防线,也都成为摆设. 下面分享一个例子,利用应用仓库,渗透到开发人员的系统中. 应用仓库 应用仓 ...
- 谈谈如何使用Netty开发实现高性能的RPC服务器
RPC(Remote Procedure Call Protocol)远程过程调用协议,它是一种通过网络,从远程计算机程序上请求服务,而不必了解底层网络技术的协议.说的再直白一点,就是客户端在不必知道 ...
- NET Core-TagHelper实现分页标签
这里将要和大家分享的是学习总结使用TagHelper实现分页标签,之前分享过一篇使用HtmlHelper扩展了一个分页写法地址可以点击这里http://www.cnblogs.com/wangrudo ...
- AFNetworking 3.0 源码解读(十)之 UIActivityIndicatorView/UIRefreshControl/UIImageView + AFNetworking
我们应该看到过很多类似这样的例子:某个控件拥有加载网络图片的能力.但这究竟是怎么做到的呢?看完这篇文章就明白了. 前言 这篇我们会介绍 AFNetworking 中的3个UIKit中的分类.UIAct ...
- 强强联合,Testin云测&云层天咨众测学院开课了!
Testin&云层天咨众测学院开课了! 共享经济时代,测试如何赶上大潮,利用碎片时间给女票或者自己赚点化妆品钱? 2016年12月13日,Testin联手云层天咨带领大家一起推开众测的大门 ...
- Ajax部分
Ajax的概念 AJAX即"Asynchronous Javascript And XML"(异步JavaScript和XML),是一种用于创建快速动态网页的技术. 动态网页:是指 ...
- bzoj1531: [POI2005]Bank notes
Description Byteotian Bit Bank (BBB) 拥有一套先进的货币系统,这个系统一共有n种面值的硬币,面值分别为b1, b2,..., bn. 但是每种硬币有数量限制,现在我 ...
- Yeoman 学习笔记
yoeman 简介:http://www.infoq.com/cn/news/2012/09/yeoman yeoman 官网: http://yeoman.io/ yeoman 是快速创建骨架应用程 ...
- Mono 3.2.7发布,JIT和GC进一步改进
Mono 3.2.7已经发布,带来了很多新特性,如改进的JIT.新的面向LINQ的解释器以及使用了64位原生指令等等. 这是一次主要特性发布,累积了大约5个月的开发工作.看上去大部分改进都是底层的性能 ...
- 让OMCS支持更多的视频采集设备
有些OMCS用户在他的系统使用了特殊的视频采集卡作为视频源(如AV-878采集卡),虽然这些采集卡可以虚拟为一个摄像头,但有些视频采集卡需要依赖于自带了sdk才能正常地完成视频采集工作.在这种情况下, ...