系数矩阵为Hessian矩阵时使用“Pearlmutter trick”或“有限差分法”近似的共轭梯度解法 —— Hession-free的共轭梯度法
共轭梯度法已经在前文中给出介绍:
共轭梯度法用来求解方程A*x=b,且A为正定矩阵。
在机器学习领域很多优化模型的求解最终可以写为A*x=b的形式,且A为正定矩阵或A为近似矩阵。在凸优化问题中A为正定矩阵是比较好满足的,在神经网络这类非线性问题中一般常用近似的技术方法来获得近似正定矩阵的A,相关见:https://www.zhihu.com/question/268719846/answer/351360155
而很多时候A*x=b中的A为Hession矩阵,即函数 f 对向量 w 的二次求导,如果w的size比较大,比如为1000000,那么这个Hession矩阵A的维度为1000000*1000000,然而这个大小的A矩阵是难以存储在内存中的。但是通过对共轭梯度法具体步骤的了解可以知道,在共轭梯度法的具体求解过程中我们其实并不是直接需要这个矩阵A进行参与计算的,我们需要直接参与计算的是A*p,由于A为Hession矩阵,因此我们有两种近似的方法来计算A*p,一种叫做“Pearlmutter trick”,一种叫做“有限差分法”。
利用“Pearlmutter trick”或“有限差分法” 近似的共轭梯度法又被称作Hession-free的共轭梯度法。
=======================================
使用共轭梯度法时,如果系数矩阵为Hessian矩阵,那么我们可以使用Pearlmutter trick技术或“有限差分法”来减少计算过程中的内存消耗,加速计算。
使用Pearlmutter trick和“有限差分法”的共轭梯度解法可以参考论文:
Fast Exact Multiplication by the Hessian
论文地址:
https://www.bcl.hamilton.ie/~barak/papers/nc-hessian.pdf
由于原论文中内容较多,所以我们介绍Pearlmutter trick技术和“有限差分法”的共轭梯度解法建议看的资料为其他网文blog:
https://justindomke.wordpress.com/2009/01/17/hessian-vector-products/
=======================================
1. 利用Pearlmutter trick的共轭梯度法
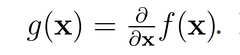
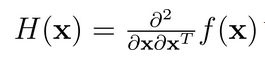
H(x)*p = ∂(g(x)*p)/∂x
=======================================
2. 利用有限差分法的共轭梯度法


依照上面内容解释一下:
Hession 矩阵 H(x) 为 f(x) 的二阶导数矩阵,因此有:
我们可以将 g(x) 按照泰勒公式展开为一阶导形式:
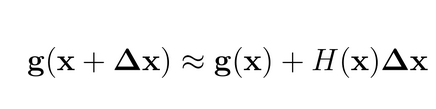
v 为一个向量vector,根据上面的公式我们可以得到:
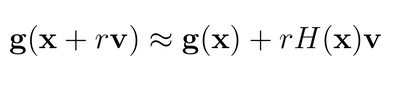
其中 γ 为标量系数,该系数极小,因此γv可以看做为Δx
因此我们可以得到下面形式的公式:
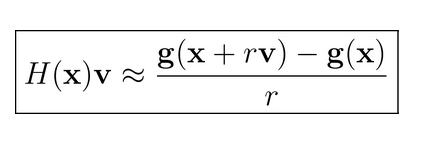

=======================================
3. Pearlmutter trick技术和“有限差分法”的共轭梯度解法的 H(x)*p部分代码:
因为 H(x) 必然为正定对称矩阵,因此我们对 H(x) * y = b 形式的求解式可以使用共轭梯度法,而共轭梯度法在计算过程中需要重复的计算 H(x)*p, 其中 p 为计算过程中的迭代向量,p是在迭代过程中不断变化的,而H(x) 是系数矩阵在迭代过程中是不变的。
Pearlmutter trick 这个技术给出的是近似解,这里知道这个技术即可,实际感觉好像用处也不多,有可能是自己理解的不深。关于H(x)*b与共轭梯度的结合代码这里就省略掉了。
import torch # 计算目标为: H*b, H为函数s关于变量w的hessian矩阵
# 变量w
w = torch.randn(4, requires_grad=True) # 关于变量w的函数s
data = torch.randn(1000*4).reshape((-1, 4))
label = torch.randn(1000)
s = torch.mean( torch.square(label - torch.matmul(data, w)) ) # 计算目标中的b
b = torch.randn(4) # s对w的一阶导
first_grad = torch.autograd.grad(s, w, create_graph=True)[0] # 使用标准公式计算 H*b
second_grad = []
for grad in first_grad:
second_grad.append(torch.autograd.grad(grad, w, retain_graph=True)[0][None, :])
H = torch.concatenate(second_grad, axis=0)
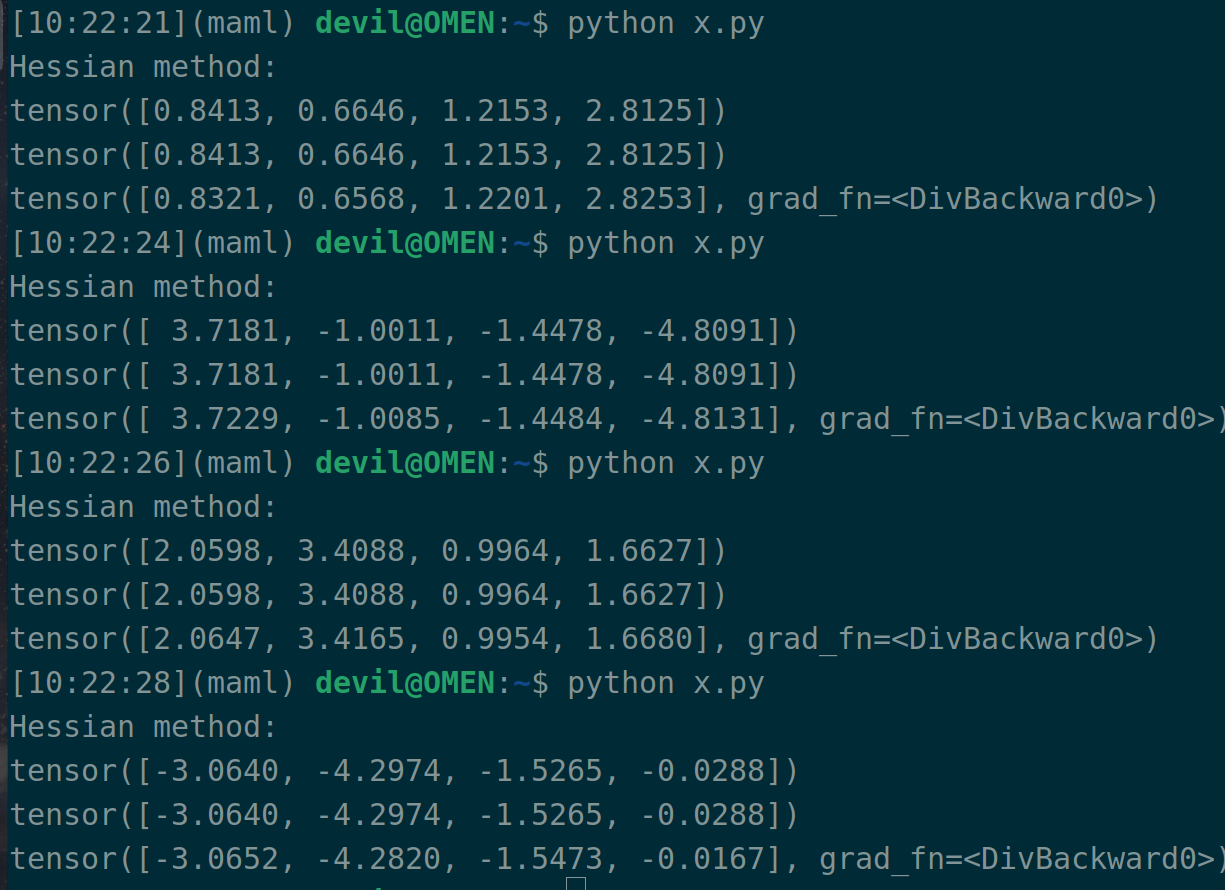
print("Hessian method:")
print(torch.matmul(H, b)) # 在目标函数s进行一阶导后点乘向量b, 然后再对w进行一次求导, 也就是 dot(first_grad, b)后再次求导
# 这样计算可以减少内存占用,因为该种计算方式不会在内存中对整个hessian矩阵进行展开
# 如果要重复计算 H*b,而b又每次迭代都变化的情况,此种方式的缺点是每次都需要再次求导,但是总计算量应该变化不大
tmp = torch.dot(first_grad, b)
print(torch.autograd.grad(tmp, w)[0]) # paper, Pearlmutter trick, 没太感觉出优势, 或许理解的不对
r = 0.0001
new_w = w+r*b
new_s = torch.mean( torch.square(label - torch.matmul(data, new_w)) ) new_first_grad = torch.autograd.grad(new_s, w)[0]
print( (new_first_grad - first_grad)/r )
注意:
这个代码一共输出三行,第一行是真实的 H(x)*b ,第二行是 Pearlmutter trick 技术计算的 H(x)*b,第三行是有限差分法计算的 H(x)*b 。
系数矩阵为Hessian矩阵时使用“Pearlmutter trick”或“有限差分法”近似的共轭梯度解法 —— Hession-free的共轭梯度法的更多相关文章
- Hessian矩阵【转】
http://blog.sina.com.cn/s/blog_7e1ecaf30100wgfw.html 在数学中,海塞矩阵是一个自变量为向量的实值函数的二阶偏导数组成的方块矩阵,一元函数就是二阶导, ...
- Hessian矩阵与多元函数极值
Hessian矩阵与多元函数极值 海塞矩阵(Hessian Matrix),又译作海森矩阵,是一个多元函数的二阶偏导数构成的方阵.虽然它是一个具有悠久历史的数学成果.可是在机器学习和图像处理(比如SI ...
- 三维重建面试4:Jacobian矩阵和Hessian矩阵
在使用BA平差之前,对每一个观测方程,得到一个代价函数.对多个路标,会产生一个多个代价函数的和的形式,对这个和进行最小二乘法进行求解,使用优化方法.相当于同时对相机位姿和路标进行调整,这就是所谓的BA ...
- 【机器学习】梯度、Hessian矩阵、平面方程的法线以及函数导数的含义
想必单独论及" 梯度.Hessian矩阵.平面方程的法线以及函数导数"等四个基本概念的时候,绝大部分人都能够很容易地谈个一二三,基本没有问题. 其实在应用的时候,这几个概念经常被混 ...
- 梯度、Hessian矩阵、平面方程的法线以及函数导数的含义
本文转载自: Xianling Mao的专栏 =========================================================================== 想 ...
- 梯度vs Jacobian矩阵vs Hessian矩阵
梯度向量 定义: 目标函数f为单变量,是关于自变量向量x=(x1,x2,-,xn)T的函数, 单变量函数f对向量x求梯度,结果为一个与向量x同维度的向量,称之为梯度向量: 1. Jacobian 在向 ...
- C#处理医学图像(二):基于Hessian矩阵的医学图像增强与窗宽窗位
根据本系列教程文章上一篇说到,在完成C++和Opencv对Hessian矩阵滤波算法的实现和封装后, 再由C#调用C++ 的DLL,(参考:C#处理医学图像(一):基于Hessian矩阵的血管肺纹理骨 ...
- Jacobian矩阵和Hessian矩阵
1.Jacobian矩阵 在矩阵论中,Jacobian矩阵是一阶偏导矩阵,其行列式称为Jacobian行列式.假设 函数 $f:R^n \to R^m$, 输入是向量 $x \in R^n$ ,输出为 ...
- Hessian矩阵
http://baike.baidu.com/link?url=o1ts6Eirjn5mHQCZUHGykiI8tDIdtHHOe6IDXagtcvF9ncOfdDOzT8tmFj41_DEsiUCr ...
- Jacobian矩阵、Hessian矩阵和Newton's method
在寻找极大极小值的过程中,有一个经典的算法叫做Newton's method,在学习Newton's method的过程中,会引入两个矩阵,使得理解的难度增大,下面就对这个问题进行描述. 1, Jac ...
随机推荐
- 使用 nsenter 排查容器网络问题
需求 我想进入容器中执行 curl 命令探测某个地址的连通性,但是容器镜像里默认没有 curl 命令.我这里是一个内网环境不太方便使用 yum 或者 apt 安装,怎么办? 这个需求比较典型,这里教大 ...
- n. Elasticsearch JAVA API操作
引言 Elasticsearch所支持的客户端连接方式有两种 Transport 连接 底层使用socket连接,用官方提供的TransPort客户端,网络IO框架使用的是netty Http连接(R ...
- 为什么不推荐使用Linq?
相信很多.NETer看了标题,都会忍不住好奇,点进来看看,并且顺便准备要喷作者! 这里,首先要申明一下,作者本人也非常喜欢Linq,也在各个项目中常用Linq. 我爱Linq,Linq优雅万岁!!!( ...
- 【FAQ】HarmonyOS SDK 闭源开放能力 —IAP Kit(2)
1.问题描述: 应用内支付IAP Kit和Payment Kit的区别以及适用场景? 解决方案: IAP Kit是四方支付,仅支持在线虚拟商品,如会员,游戏钻石等,双框架支持全球,目前单框架暂时只支持 ...
- LaTeX 编辑协作平台 Overleaf 安装和使用教程
在学术界和科技行业,LaTeX 已成为撰写高质量文档的标准工具.然而,传统的 LaTeX 使用体验常常伴随着以下挑战: 学习曲线陡峭 环境配置复杂 多人协作困难 实时预览不便 当然,市面上不乏很多在线 ...
- Java for循环倒序输出
1.实现一个for循环的倒序输出 在Java中,要实现一个for循环的倒序输出,通常我们会使用数组或集合(如ArrayList)作为数据源,然后通过倒序遍历这个数组或集合来实现.下面,我将给出一个详细 ...
- 基于 .net core 8.0 的 swagger 文档优化分享-根据命名空间分组显示
前言 公司项目是是微服务项目,网关是手撸的一个.net core webapi 项目,使用 refit 封装了 20+ 服务 SDK,在网关中进行统一调用和聚合等处理,以及给前端提供 swagger ...
- Nginx负载配置
目录 Nginx 负载均衡笔记 1. 概述 1.1 Nginx 简介 1.2 负载均衡概述 2. 四层负载均衡(传输层) 2.1 工作原理 2.2 特点 2.3 优缺点 优点 缺点 2.4 示例场景 ...
- Python数据分析方法与技巧
背景介绍 数据分析是数据科学领域的核心技能之一,它涉及到数据的收集.清洗.处理.分析和可视化. 数据分析是指通过收集.清洗.处理.分析和可视化数据来发现隐藏的模式.趋势和关系的过程. 数据分析是数据科 ...
- 松灵机器人scout mini小车 自主导航(2)——仿真指南
松灵机器人Scout mini小车仿真指南 之前介绍了如何通过CAN TO USB串口实现用键盘控制小车移动.但是一直用小车测试缺乏安全性.而松灵官方贴心的为我们准备了gazebo仿真环境,提供了完整 ...