系数矩阵为Hessian矩阵时使用“Pearlmutter trick”或“有限差分法”近似的共轭梯度解法 —— Hession-free的共轭梯度法
共轭梯度法已经在前文中给出介绍:
共轭梯度法用来求解方程A*x=b,且A为正定矩阵。
在机器学习领域很多优化模型的求解最终可以写为A*x=b的形式,且A为正定矩阵或A为近似矩阵。在凸优化问题中A为正定矩阵是比较好满足的,在神经网络这类非线性问题中一般常用近似的技术方法来获得近似正定矩阵的A,相关见:https://www.zhihu.com/question/268719846/answer/351360155
而很多时候A*x=b中的A为Hession矩阵,即函数 f 对向量 w 的二次求导,如果w的size比较大,比如为1000000,那么这个Hession矩阵A的维度为1000000*1000000,然而这个大小的A矩阵是难以存储在内存中的。但是通过对共轭梯度法具体步骤的了解可以知道,在共轭梯度法的具体求解过程中我们其实并不是直接需要这个矩阵A进行参与计算的,我们需要直接参与计算的是A*p,由于A为Hession矩阵,因此我们有两种近似的方法来计算A*p,一种叫做“Pearlmutter trick”,一种叫做“有限差分法”。
利用“Pearlmutter trick”或“有限差分法” 近似的共轭梯度法又被称作Hession-free的共轭梯度法。
=======================================
使用共轭梯度法时,如果系数矩阵为Hessian矩阵,那么我们可以使用Pearlmutter trick技术或“有限差分法”来减少计算过程中的内存消耗,加速计算。
使用Pearlmutter trick和“有限差分法”的共轭梯度解法可以参考论文:
Fast Exact Multiplication by the Hessian
论文地址:
https://www.bcl.hamilton.ie/~barak/papers/nc-hessian.pdf
由于原论文中内容较多,所以我们介绍Pearlmutter trick技术和“有限差分法”的共轭梯度解法建议看的资料为其他网文blog:
https://justindomke.wordpress.com/2009/01/17/hessian-vector-products/
=======================================
1. 利用Pearlmutter trick的共轭梯度法
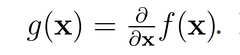
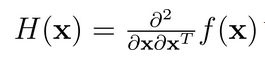
H(x)*p = ∂(g(x)*p)/∂x
=======================================
2. 利用有限差分法的共轭梯度法


依照上面内容解释一下:
Hession 矩阵 H(x) 为 f(x) 的二阶导数矩阵,因此有:
我们可以将 g(x) 按照泰勒公式展开为一阶导形式:
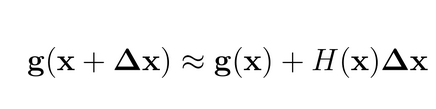
v 为一个向量vector,根据上面的公式我们可以得到:
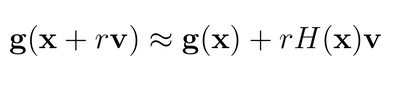
其中 γ 为标量系数,该系数极小,因此γv可以看做为Δx
因此我们可以得到下面形式的公式:
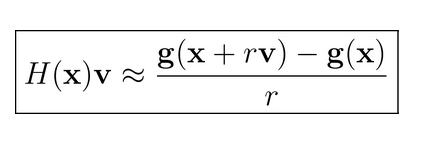

=======================================
3. Pearlmutter trick技术和“有限差分法”的共轭梯度解法的 H(x)*p部分代码:
因为 H(x) 必然为正定对称矩阵,因此我们对 H(x) * y = b 形式的求解式可以使用共轭梯度法,而共轭梯度法在计算过程中需要重复的计算 H(x)*p, 其中 p 为计算过程中的迭代向量,p是在迭代过程中不断变化的,而H(x) 是系数矩阵在迭代过程中是不变的。
Pearlmutter trick 这个技术给出的是近似解,这里知道这个技术即可,实际感觉好像用处也不多,有可能是自己理解的不深。关于H(x)*b与共轭梯度的结合代码这里就省略掉了。
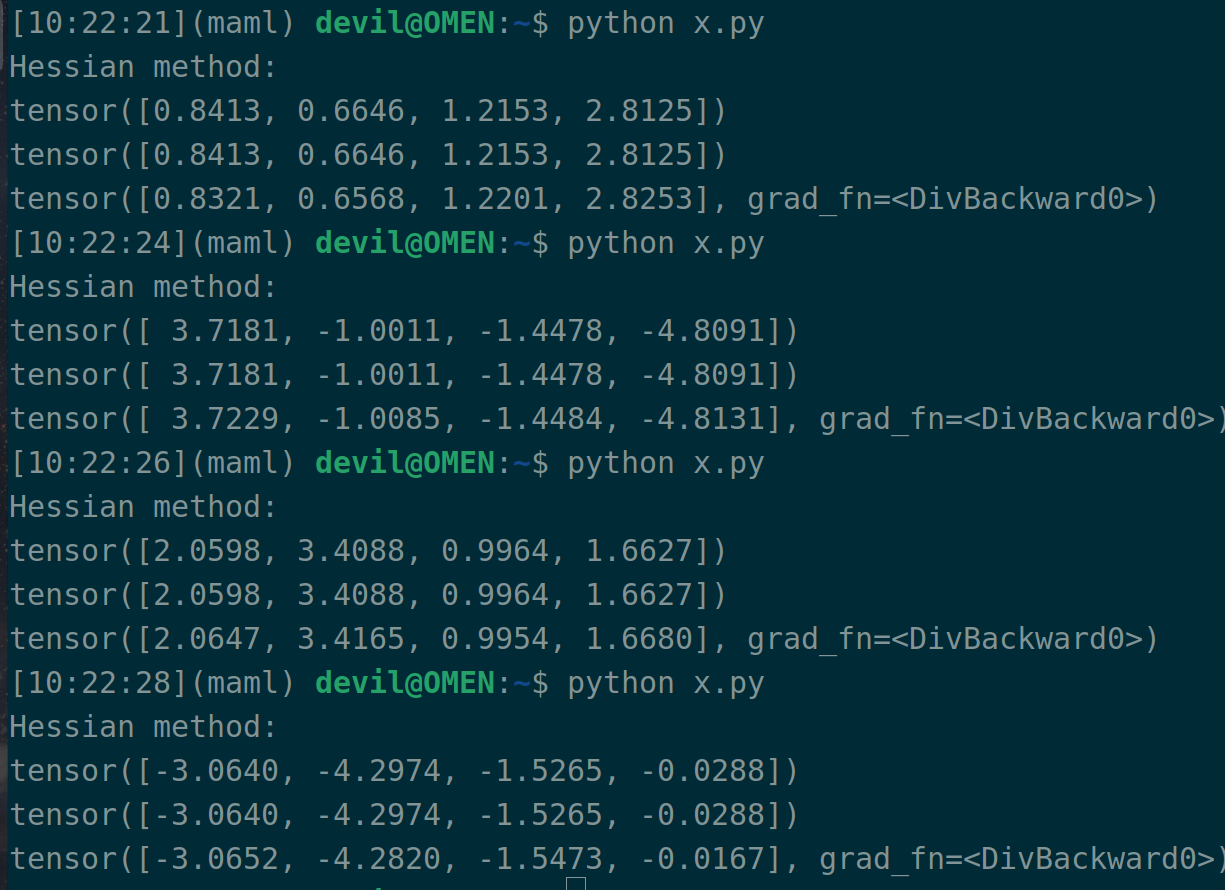
import torch # 计算目标为: H*b, H为函数s关于变量w的hessian矩阵
# 变量w
w = torch.randn(4, requires_grad=True) # 关于变量w的函数s
data = torch.randn(1000*4).reshape((-1, 4))
label = torch.randn(1000)
s = torch.mean( torch.square(label - torch.matmul(data, w)) ) # 计算目标中的b
b = torch.randn(4) # s对w的一阶导
first_grad = torch.autograd.grad(s, w, create_graph=True)[0] # 使用标准公式计算 H*b
second_grad = []
for grad in first_grad:
second_grad.append(torch.autograd.grad(grad, w, retain_graph=True)[0][None, :])
H = torch.concatenate(second_grad, axis=0)
print("Hessian method:")
print(torch.matmul(H, b)) # 在目标函数s进行一阶导后点乘向量b, 然后再对w进行一次求导, 也就是 dot(first_grad, b)后再次求导
# 这样计算可以减少内存占用,因为该种计算方式不会在内存中对整个hessian矩阵进行展开
# 如果要重复计算 H*b,而b又每次迭代都变化的情况,此种方式的缺点是每次都需要再次求导,但是总计算量应该变化不大
tmp = torch.dot(first_grad, b)
print(torch.autograd.grad(tmp, w)[0]) # paper, Pearlmutter trick, 没太感觉出优势, 或许理解的不对
r = 0.0001
new_w = w+r*b
new_s = torch.mean( torch.square(label - torch.matmul(data, new_w)) ) new_first_grad = torch.autograd.grad(new_s, w)[0]
print( (new_first_grad - first_grad)/r )
注意:
这个代码一共输出三行,第一行是真实的 H(x)*b ,第二行是 Pearlmutter trick 技术计算的 H(x)*b,第三行是有限差分法计算的 H(x)*b 。
系数矩阵为Hessian矩阵时使用“Pearlmutter trick”或“有限差分法”近似的共轭梯度解法 —— Hession-free的共轭梯度法的更多相关文章
- Hessian矩阵【转】
http://blog.sina.com.cn/s/blog_7e1ecaf30100wgfw.html 在数学中,海塞矩阵是一个自变量为向量的实值函数的二阶偏导数组成的方块矩阵,一元函数就是二阶导, ...
- Hessian矩阵与多元函数极值
Hessian矩阵与多元函数极值 海塞矩阵(Hessian Matrix),又译作海森矩阵,是一个多元函数的二阶偏导数构成的方阵.虽然它是一个具有悠久历史的数学成果.可是在机器学习和图像处理(比如SI ...
- 三维重建面试4:Jacobian矩阵和Hessian矩阵
在使用BA平差之前,对每一个观测方程,得到一个代价函数.对多个路标,会产生一个多个代价函数的和的形式,对这个和进行最小二乘法进行求解,使用优化方法.相当于同时对相机位姿和路标进行调整,这就是所谓的BA ...
- 【机器学习】梯度、Hessian矩阵、平面方程的法线以及函数导数的含义
想必单独论及" 梯度.Hessian矩阵.平面方程的法线以及函数导数"等四个基本概念的时候,绝大部分人都能够很容易地谈个一二三,基本没有问题. 其实在应用的时候,这几个概念经常被混 ...
- 梯度、Hessian矩阵、平面方程的法线以及函数导数的含义
本文转载自: Xianling Mao的专栏 =========================================================================== 想 ...
- 梯度vs Jacobian矩阵vs Hessian矩阵
梯度向量 定义: 目标函数f为单变量,是关于自变量向量x=(x1,x2,-,xn)T的函数, 单变量函数f对向量x求梯度,结果为一个与向量x同维度的向量,称之为梯度向量: 1. Jacobian 在向 ...
- C#处理医学图像(二):基于Hessian矩阵的医学图像增强与窗宽窗位
根据本系列教程文章上一篇说到,在完成C++和Opencv对Hessian矩阵滤波算法的实现和封装后, 再由C#调用C++ 的DLL,(参考:C#处理医学图像(一):基于Hessian矩阵的血管肺纹理骨 ...
- Jacobian矩阵和Hessian矩阵
1.Jacobian矩阵 在矩阵论中,Jacobian矩阵是一阶偏导矩阵,其行列式称为Jacobian行列式.假设 函数 $f:R^n \to R^m$, 输入是向量 $x \in R^n$ ,输出为 ...
- Hessian矩阵
http://baike.baidu.com/link?url=o1ts6Eirjn5mHQCZUHGykiI8tDIdtHHOe6IDXagtcvF9ncOfdDOzT8tmFj41_DEsiUCr ...
- Jacobian矩阵、Hessian矩阵和Newton's method
在寻找极大极小值的过程中,有一个经典的算法叫做Newton's method,在学习Newton's method的过程中,会引入两个矩阵,使得理解的难度增大,下面就对这个问题进行描述. 1, Jac ...
随机推荐
- ES备份恢复
1.官网提供snap快照备份恢复 https://www.elastic.co/guide/en/elasticsearch/reference/7.9/snapshot-restore.html 环 ...
- mysql报错 a foreign key constraint fails(外键约束错误)
报错信息如下: (pymysql.err.IntegrityError) (1452, u'Cannot add or update a child row: a foreign key constr ...
- es6.6.1 rest常规操作
ES 内置的REST接口/ 获取版本信息/index/_search 搜索指定索引下的数据 test/_search/_aliases 获取或者操作索引下的别名 _aliases/index/ 查看指 ...
- Apollo quick start SampleApp demo Java
<!--配置中心--> <dependency> <groupId>com.ctrip.framework.apollo</groupId> <a ...
- CNN -- Simple Residual Network
Smiling & Weeping ---- 我爱你,从这里一直到月亮,再绕回来 说明: 1.要解决的问题:梯度消失 2. 跳连接,H(x) = F(x)+x,张量维度必须一致,加完后再激活. ...
- 使用定时器:在logs目录,每两分钟产生一个文件
1.使用定时器:在logs目录,每两分钟产生一个文件(文件格式为:201711151323.log.201711151323.log.2017111513xx.log ...思路:定时器定时调用she ...
- 详解Web应用安全系列(8)不足的日志记录和监控
在Web安全领域,不足的日志记录和监控是一个重要的安全隐患,它可能导致攻击者能够更隐蔽地进行攻击,同时增加了攻击被检测和响应的难度.以下是对Web攻击中不足的日志记录和监控漏洞的详细介绍. 一.日志记 ...
- Quarkus初体验:动态加载和原生部署
在前面的文章<尝试官方的第一个SpringNative 0.11程序>中提到过Quarkus这门技术.这里就简单演示一下它的两个主要功能:Live Coding和Native Build. ...
- P9376 题解
首先考虑怎么暴力. 考虑把每个数进行 \(B\) 进制分解,然后我们惊奇的发现这两个操作就是把最低位去掉和往最低位后面插入一个数. 然后我们顺藤摸瓜,把每个数的分解扔到 Trie 树上,我们发现我们要 ...
- 利用Selenium和PhantomJS绕过接口加密的技术探索与实践
selenium+phantomjs绕过接口加密 我们为什么需要selenium 之前我们讲解了 Ajax 的分析方法,利用 Ajax 接口我们可以非常方便地完成数据的爬取.只要我们能找到 Ajax ...