Hadoop实战项目:小文件合并
项目背景
在实际项目中,输入数据往往是由许多小文件组成,这里的小文件是指小于HDFS系统Block大小的文件(默认128M),早期的版本所定义的小文件是64M,这里的hadoop-2.2.0所定义的小文件是128M。然而每一个存储在HDFS中的文件、目录和块都映射为一个对象,存储在NameNode服务器内存中,通常占用150个字节。 如果有1千万个文件,就需要消耗大约3G的内存空间。如果是10亿个文件呢,简直不可想象。所以在项目开始前, 我们要先了解一下 hadoop 处理小文件的各种方案,然后本课程选择一种适合的方案来解决本项目的小文件问题。Hadoop 自身提供了几种机制来解决相关的问题,包括HAR, SequeueFile和CombineFileInputFormat。
项目介绍
在本地 D://Code/EclipseCode/mergeSmallFilesTestData目录下有 2018-03-23 至 2018-03-29 一共7天的数据集,我们需要将这7天的数据集按日期合并为7个大文件上传至 HDFS。

思路分析
基于项目的需求,我们通过下面几个步骤完成:
1)首先通过 globStatus()方法过滤掉 svn 格式的文件,获取 D://Code/EclipseCode/mergeSmallFilesTestData目录下的其它所有文件路径。
2)然后循环第一步的所有文件路径,通过globStatus()方法获取所有 txt 格式文件路径。
3)最后通过IOUtils.copyBytes(in, out, 4096, false)方法将数据集合并为7个大文件,并上传至 HDFS。
程序
在Hadoop项目路径下新建MergeSmallFilesToHDFS.java:
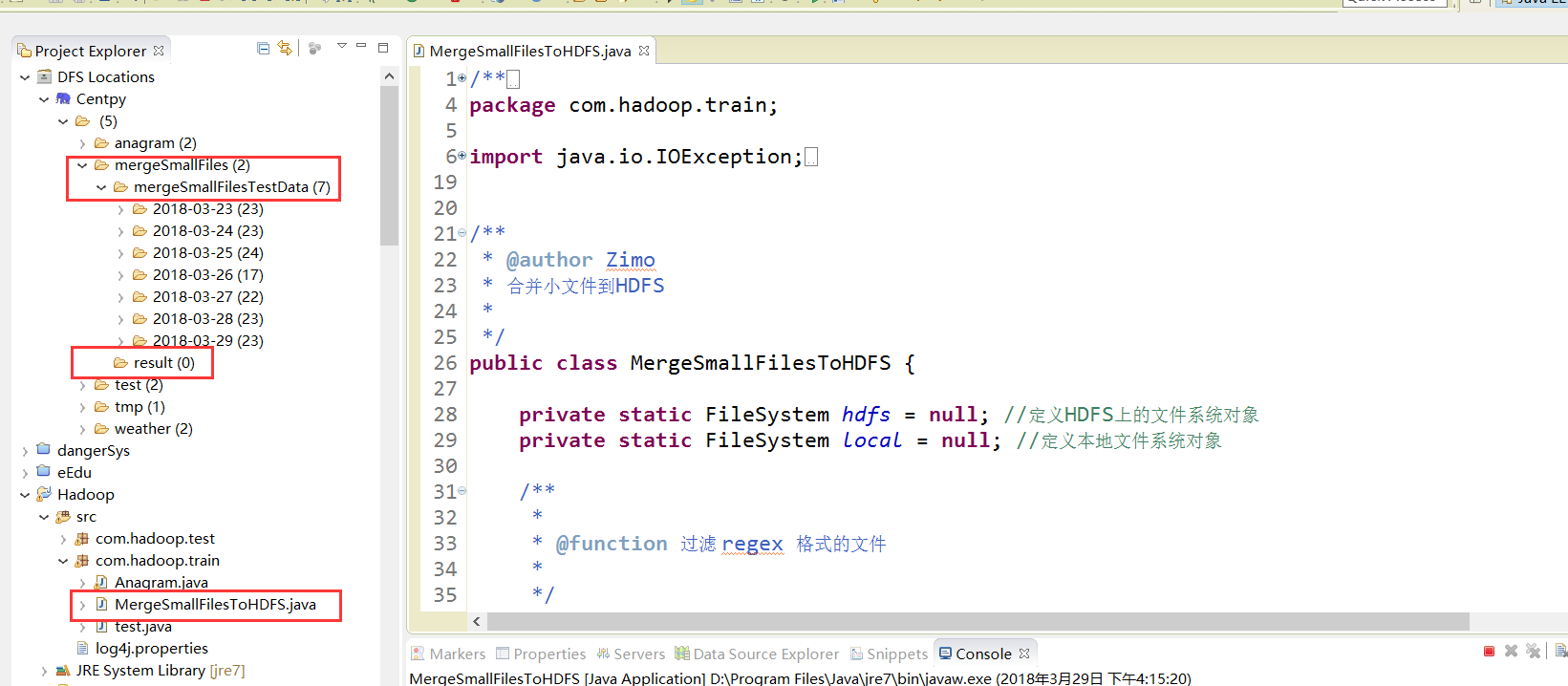
/**
*
*/
package com.hadoop.train; import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FileUtil;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.PathFilter;
import org.apache.hadoop.io.IOUtils; /**
* @author Zimo
* 合并小文件到HDFS
*
*/
public class MergeSmallFilesToHDFS { private static FileSystem hdfs = null; //定义HDFS上的文件系统对象
private static FileSystem local = null; //定义本地文件系统对象 /**
*
* @function 过滤 regex 格式的文件
*
*/
public static class RegexExcludePathFilter implements PathFilter
{ private final String regex; public RegexExcludePathFilter(String regex) {
// TODO Auto-generated constructor stub
this.regex = regex;
} @Override
public boolean accept(Path path) {
// TODO Auto-generated method stub
boolean flag = path.toString().matches(regex);
return !flag;
} } /**
*
* @function 接受 regex 格式的文件
*
*/
public static class RegexAcceptPathFilter implements PathFilter
{ private final String regex; public RegexAcceptPathFilter(String regex) {
// TODO Auto-generated constructor stub
this.regex = regex;
} @Override
public boolean accept(Path path) {
// TODO Auto-generated method stub
boolean flag = path.toString().matches(regex);
return flag;
} } /**
* @param args
* @throws IOException
* @throws URISyntaxException
*/
public static void main(String[] args) throws URISyntaxException, IOException {
// TODO Auto-generated method stub
list(); } private static void list() throws URISyntaxException, IOException {
// TODO Auto-generated method stub
Configuration conf = new Configuration();//读取Hadoop配置文件 //设置文件系统访问接口,并创建FileSystem在本地的运行模式
URI uri = new URI("hdfs://Centpy:9000");
hdfs = FileSystem.get(uri, conf); local = FileSystem.getLocal(conf);//获取本地文件系统 //过滤目录下的svn文件
FileStatus[] dirstatus = local.globStatus(new Path("D://Code/EclipseCode/mergeSmallFilesTestData/*"),
new RegexExcludePathFilter("^.*svn$")); //获取D:\Code\EclipseCode\mergeSmallFilesTestData目录下的所有文件路径
Path[] dirs = FileUtil.stat2Paths(dirstatus);
FSDataOutputStream out = null;
FSDataInputStream in = null;
for(Path dir:dirs)
{//比如拿2018-03-23为例 //将文件夹名称2018-03-23的-去掉,直接,得到20180323文件夹名称
String fileName = dir.getName().replace("-", "");//文件名称 //只接受2018-03-23日期目录下的.txt文件
FileStatus[] localStatus = local.globStatus(new Path(dir + "/*"),
new RegexAcceptPathFilter("^.*txt$")); // 获得2018-03-23日期目录下的所有文件
Path[] listPath = FileUtil.stat2Paths(localStatus); // 输出路径
Path outBlock = new Path("hdfs://Centpy:9000/mergeSmallFiles/result/"+ fileName + ".txt");
System.out.println("合并后的文件名称:"+fileName+".txt"); // 打开输出流
out = hdfs.create(outBlock); //循环操作2018-03-23日期目录下的所有文件
for(Path p:listPath)
{
in = local.open(p);// 打开输入流
IOUtils.copyBytes(in, out, , false);// 复制数据
in.close();// 关闭输入流
} if (out != null) {
out.close();// 关闭输出流
}
} } }
测试结果
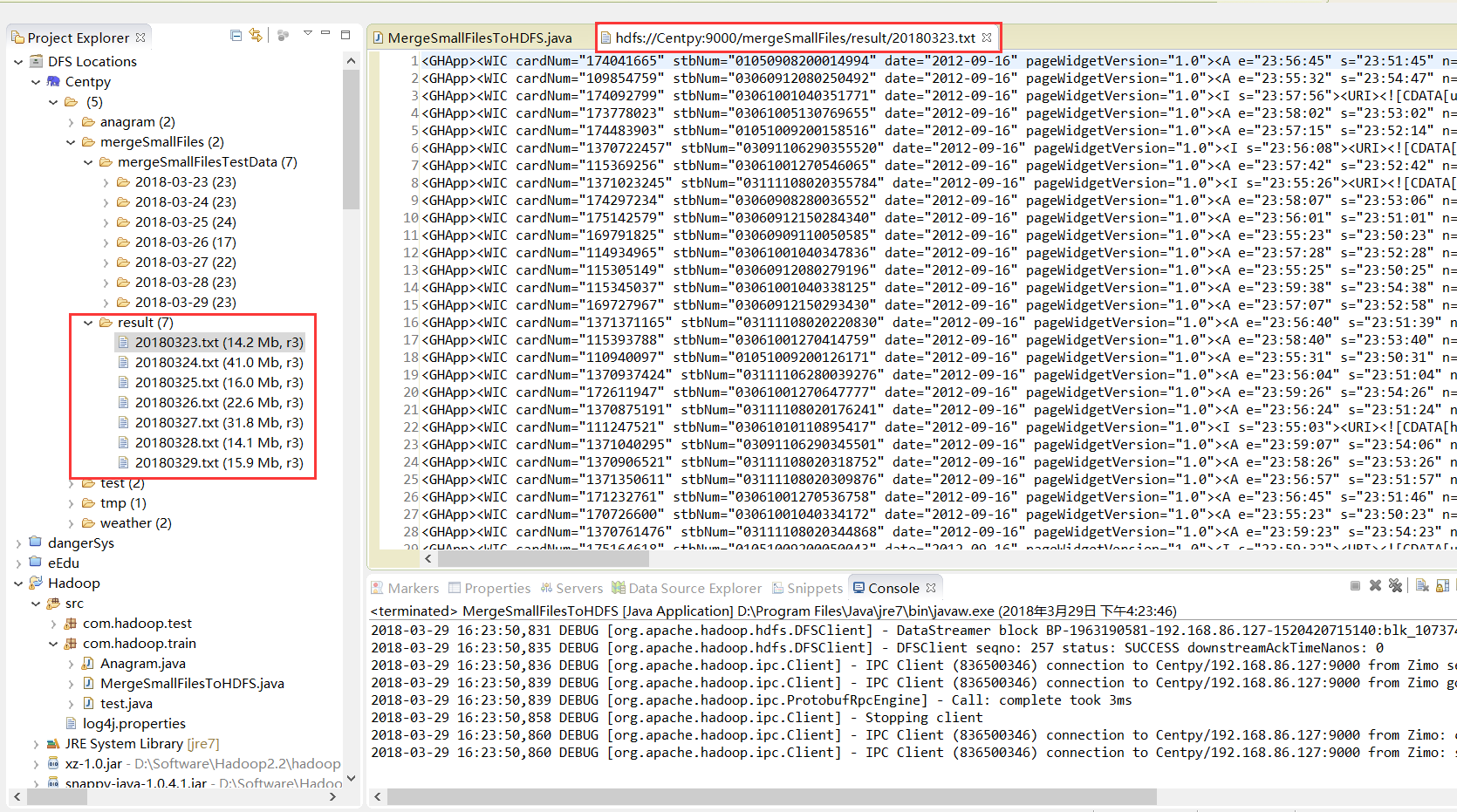
运行程序之后会将本地D://Code/EclipseCode/mergeSmallFilesTestData路径下的每个文件夹下的n个.txt文件内容合并到一个.txt文件中,并存放到指定的HDFS路径("hdfs://Centpy:9000/mergeSmallFiles/result/")下。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
版权声明:本文为博主原创文章,未经博主允许不得转载。
Hadoop实战项目:小文件合并的更多相关文章
- Hadoop MapReduce编程 API入门系列之小文件合并(二十九)
不多说,直接上代码. Hadoop 自身提供了几种机制来解决相关的问题,包括HAR,SequeueFile和CombineFileInputFormat. Hadoop 自身提供的几种小文件合并机制 ...
- Hadoop经典案例(排序&Join&topk&小文件合并)
①自定义按某列排序,二次排序 writablecomparable中的compareto方法 ②topk a利用treemap,缺点:map中的key不允许重复:https://blog.csdn.n ...
- 基于Hadoop Sequencefile的小文件解决方案
一.概述 小文件是指文件size小于HDFS上block大小的文件.这样的文件会给hadoop的扩展性和性能带来严重问题.首先,在HDFS中,任何block,文件或者目录在内存中均以对象的形式存储,每 ...
- hive小文件合并设置参数
Hive的后端存储是HDFS,它对大文件的处理是非常高效的,如果合理配置文件系统的块大小,NameNode可以支持很大的数据量.但是在数据仓库中,越是上层的表其汇总程度就越高,数据量也就越小.而且这些 ...
- HDFS操作及小文件合并
小文件合并是针对文件上传到HDFS之前 这些文件夹里面都是小文件 参考代码 package com.gong.hadoop2; import java.io.IOException; import j ...
- MR案例:小文件合并SequeceFile
SequeceFile是Hadoop API提供的一种二进制文件支持.这种二进制文件直接将<key, value>对序列化到文件中.可以使用这种文件对小文件合并,即将文件名作为key,文件 ...
- 关于hadoop处理大量小文件情况的解决方法
小文件是指那些size比HDFS的block size(默认64m)小的多的文件.任何一个文件,目录和bolck,在HDFS中都会被表示为一个object存储在namenode的内存中,每一个obje ...
- Hive merge(小文件合并)
当Hive的输入由非常多个小文件组成时.假设不涉及文件合并的话.那么每一个小文件都会启动一个map task. 假设文件过小.以至于map任务启动和初始化的时间大于逻辑处理的时间,会造成资源浪费.甚至 ...
- hive优化之小文件合并
文件数目过多,会给HDFS带来压力,并且会影响处理效率,可以通过合并Map和Reduce的结果文件来消除这样的影响: set hive.merge.mapfiles = true ##在 map on ...
- 第3节 mapreduce高级:5、6、通过inputformat实现小文件合并成为sequenceFile格式
1.1 需求 无论hdfs还是mapreduce,对于小文件都有损效率,实践中,又难免面临处理大量小文件的场景,此时,就需要有相应解决方案 1.2 分析 小文件的优化无非以下几种方式: 1. 在数据 ...
随机推荐
- 生成0-42之间的7个不重复的int值
public static void main(String[] args) { //set集合存储不重复无序的值 Set<Integer> set = new HashSet<In ...
- redis设置密码和redis主从复制
redis设置密码和redis主从复制 一.redis设置密码 1.Redis实用特性 安全性 主从复制(侦听器)事务处理 持久化机制 发布订阅消息 2.安全性:设置客户端连接后进行任何其他指定前需 ...
- 洛谷 P4336 黑暗前的幻想乡 —— 容斥+矩阵树定理
题目:https://www.luogu.org/problemnew/show/P4336 当作考试题了,然而没想出来,呵呵. 其实不是二分图完美匹配方案数,而是矩阵树定理+容斥... 就是先放上所 ...
- 洛谷P2024食物链——并查集补集的灵活运用
题目:https://www.luogu.org/problemnew/show/P2024 自己在做本题时最大的障碍就是:不会在一个集合的father改变时把相应的补集也跟着改变. 借鉴题解后,才明 ...
- opencv报错 error: (-215) size.width>0 && size.height>0 in function cv::imshow
使用opencv读取摄像头并且显示事出现此问题: 后来发现是图像为空时的错误,加入: if(!frame.empty()) imshow("video",frame); 完整的代码 ...
- .NETFramework:WebClient
ylbtech-.NETFramework:WebClient 1.程序集 System, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5 ...
- ScrollView cannot scroll in Slidinguppanellayout 解决办法
xml源码如下 <?xml version="1.0" encoding="utf-8"?> <RelativeLayout xmlns:an ...
- jQuery名字冲突 noConflict()方法
今天检查项目的时候发现一个jquery变量$的控制权让渡问题,原因是: 开发这个模块的同事使用了一个日历插件,把$的控制权让出了,就导致了加载完这个页面后再加载其他页面就会报出$不是一个函数的错误. ...
- Linux下搭建tomcat集群全记录
(转) Linux下搭建tomcat集群全记录 2011-10-12 10:23 6133人阅读 评论(1) 收藏 举报 tomcatlinuxapacheinterceptorsession集群 1 ...
- 连接Oracle数据库的Hibernate配置…
连接Oracle数据库的Hibernate配置文件 连接Oracle的Hibernate配置文件有两种格式,一种是xml格式的,另一种是Java属性文件格式的.下面分别给出这两种格式配置文件的代码. ...