Flume+Kafka整合
脚本生产数据---->flume采集数据----->kafka消费数据------->storm集群处理数据
日志文件使用log4j生成,滚动生成!
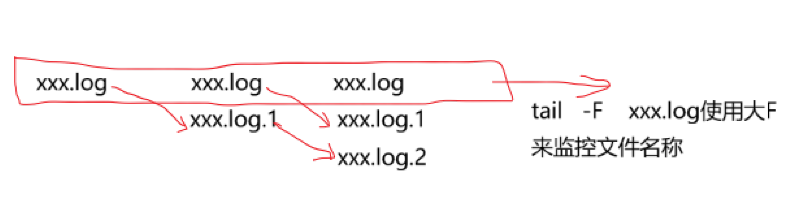
当前正在写入的文件在满足一定的数量阈值之后,需要重命名!!!
flume+Kafka整合步骤及相关配置:(先安装好zookeeper集群和Kafka集群)
配置flume:
1、下载flume
2、解压flume安装包
cd /export/servers/
tar -zxvf apache-flume-1.6.0-bin.tar.gz
ln -s apache-flume-1.6.0-bin flume
3、创建flume配置文件
cd /export/servers/flume/conf/
mkdir myconf
vi exec.conf
输入一下内容:
a1.sources=r1
a1.channels=c1
a1.sinks=k1
a1.sources.r1.type=exec
a1.sources.r1.command=tail -F /export/data/flume_sources/click_log/1.log
a1.sources.r1.channels=c1
a1.channels.c1.type=memory
a1.channels.c1.capacity=10000
a1.channels.c1.transactionCapacity=100
a1.sinks.k1.type=org.apache.flume.sink.kafka.KafkaSink
a1.sinks.k1.topic=test
a1.sinks.k1.brokerList=kafka01:9092
a1.sinks.k1.requiredAcks=1
a1.sinks.k1.batchSize=20
a1.sinks.k1.channel=c1
4、准备目标数据的目录
mkdir -p /export/data/flume_sources/click_log
5、通过脚本创建目标文件并生产数据
for((i=0;i<=50000;i++));
do echo "message-" + $i >> /export/data/flume_sources/click_log/1.log;
done
注:脚本名称为click_log_out.sh,需要使用root用户赋权,chmod +x click_log_out.sh
6、开始打通所有流程
一:启动Kafka集群
kafka-server-start.sh /export/servers/kafka/config/server.properties
二:创建一个topic并开启consumer
kafka-console-consumer.sh --topic=test --zookeeper zk01:2181
三:执行数据生产的脚本
sh click_log_out.sh
四:启动flume客户端
./bin/flume_ng agent -n a1 -c conf -f conf/myconf/exec.conf -Dflume.root.logger=INFO,console
五:在第三步启动的kafka consumer窗口查看效果
Flume+Kafka整合的更多相关文章
- hadoop 之 kafka 安装与 flume -> kafka 整合
62-kafka 安装 : flume 整合 kafka 一.kafka 安装 1.下载 http://kafka.apache.org/downloads.html 2. 解压 tar -zxvf ...
- 大数据系列之Flume+kafka 整合
相关文章: 大数据系列之Kafka安装 大数据系列之Flume--几种不同的Sources 大数据系列之Flume+HDFS 关于Flume 的 一些核心概念: 组件名称 功能介绍 Agent ...
- Flume+Kafka+Storm+Redis 大数据在线实时分析
1.实时处理框架 即从上面的架构中我们可以看出,其由下面的几部分构成: Flume集群 Kafka集群 Storm集群 从构建实时处理系统的角度出发,我们需要做的是,如何让数据在各个不同的集群系统之间 ...
- flume与kafka整合
flume与kafka整合 前提: flume安装和测试通过,可参考:http://www.cnblogs.com/rwxwsblog/p/5800300.html kafka安装和测试通过,可参考: ...
- Flume+Kafka+Storm+Hbase+HDSF+Poi整合
Flume+Kafka+Storm+Hbase+HDSF+Poi整合 需求: 针对一个网站,我们需要根据用户的行为记录日志信息,分析对我们有用的数据. 举例:这个网站www.hongten.com(当 ...
- Flume+Kafka+Storm整合
Flume+Kafka+Storm整合 1. 需求: 有一个客户端Client可以产生日志信息,我们需要通过Flume获取日志信息,再把该日志信息放入到Kafka的一个Topic:flume-to-k ...
- ambari下的flume和kafka整合
1.配置flume #扫描指定文件配置 agent.sources = s1 agent.channels = c1 agent.sinks = k1 agent.sources.s1.type=ex ...
- Flume和Kafka整合安装
版本号: RedHat6.5 JDK1.8 flume-1.6.0 kafka_2.11-0.8.2.1 1.flume安装 RedHat6.5安装单机flume1.6:http://b ...
- flume和kafka整合(转)
原文链接:Kafka flume 整合 前提 前提是要先把flume和kafka独立的部分先搭建好. 下载插件包 下载flume-kafka-plus:https://github.com/beyon ...
随机推荐
- Bugly实现app全量更新
转 http://blog.csdn.net/qq_33689414/article/details/54911895Bugly实现app全量更新 Bugly官网文档 一.参数配置 在app下的gra ...
- JavaScript之获取表格目标数据(TableDom.getTableData())
[声明: 1.博文原创 未经同意转载必究,欢迎相互交流] [声明: 2.博主未知情况下转载,需显著处注明博文来源] [声明: 3.谢谢尊重劳动成果,谢谢理解与配合~] 一.背景 在生产过程和生活 ...
- day1 查看当前目录命令:pwd
用到查看当前目录的完整路径使用:pwd 物理路径和连接路径什么鬼?没明白暂时借鉴别人的记录下 显示当前目录的物理路径 pwd –P 1: [root@DB-Server init.d]# cd /et ...
- 8、判断三角形ABC中是否有点D
思路: 首先连接AD,BD,CD,SABC为三角形的面积,SABD为三角形ABD的面积,SACD....,SBCD....... 因此,若D在三角形则SABC = SABD + SACD + SBCD ...
- mysql原理~undo管理
一 简介:undo管理 二 各版本说明 1 5.5 undo位置:默认ibdata1中,不支持独立表空间 缺点:大事务可能造成ibdata1暴涨,只能dump导出导入或者从新搭建 参数: ...
- VMware xp系统联网
1.
- CentOS 6.5下快速搭建ftp服务器[转]
CentOS 6.5下快速搭建ftp服务器 1.用root 进入系统 2.使用命令 rpm -qa|grep vsftpd 查看系统是否安装了ftp,若安装了vsftp,使用这个命令会在屏幕上显示vs ...
- Eclipse中项目不会自动编译问题的坑和注意点
最近接受了几个又小有老的项目,用eclipse反而比idea方便,但是好长时间不用eclipse了,还有有些问题的! 主要是碰到了classnotfound这个难缠的问题:这里记录一下几个坑,避免以后 ...
- malloc 函数详解【转】
转自:https://www.cnblogs.com/Commence/p/5785912.html 很多学过C的人对malloc都不是很了解,知道使用malloc要加头文件,知道malloc是分配一 ...
- php- post表单 input name属性的问题
<input type='text' style='width: 99px' name='deptNo'></td> name为字符串的时候传递的是单个字符串 <inp ...