大数据之路week07--day06 (Sqoop 在从HDFS中导出到关系型数据库时的一些问题)
问题一:
在上传过程中遇到这种问题:
ERROR tool.ExportTool: Encountered IOException running export job: java.io.IOException: No columns to generate for ClassWriter
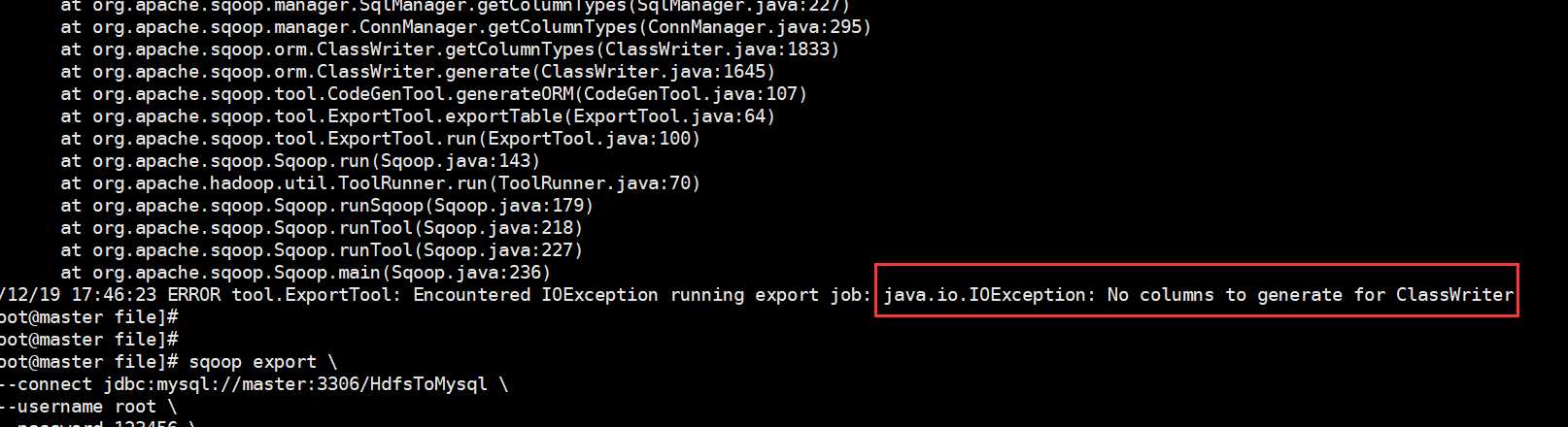
解决方式:
在网上搜索的时候很多博客说时驱动版本的过低导致的,其实在尝试这个方法的时候我们可以先进行这样:加一行命令,--driver com.mysql.jdbc.Driver \ 然后问题解决!!!
如果添加命令之后还没有解决就把jar包换成高点版本的。百度云链接:
链接:https://pan.baidu.com/s/1q-6O0ER-Vtc74ha_9DMbpQ
提取码:174n
问题二:
依旧是导出的时候,会报错,但是我们很神奇的发现,也有部分数据导入了。这也就是下一个问题。
Caused by: java.lang.NumberFormatException: For input string: "null"

解决方式:因为数据有存在null值得导致的
在命令中加入一行(方式一中的修改方式,方式二也就是转换一下格式):--input-null-string '\\N' \ 也有的博主说加两行,但是我加一行也可以,具体原因没有细查。
问腿三:
java.lang.RuntimeException: Can't parse input data: '1998/5/11'
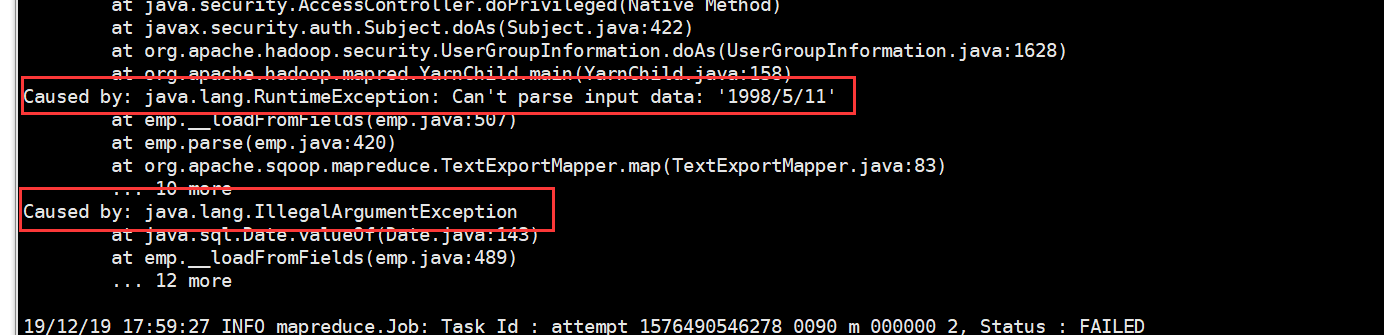
出现像这样的问题,大多是因为HDFS上的数据与关系型数据库创建表的字段类型不匹配导致的。仔细对比修改后,就不会有这个报错啦!!
当然,会发生的问题肯定不会是就这么点,主要靠平时的积累,修改,才能不断地成长。
注意: 千万不要犯像敲错字母,或者命令打错,空格少打这样的低级错误,这样会很耗时,唯一的解决办法,那就是,多加练习,勤敲。!!!
大数据之路week07--day06 (Sqoop 在从HDFS中导出到关系型数据库时的一些问题)的更多相关文章
- 大数据之路week07--day06 (Sqoop 的使用)
Sqoop的使用一(将数据库中的表数据上传到HDFS) 首先我们先准备数据 1.没有主键的数据(下面介绍有主键和没有主键的使用区别) -- MySQL dump 10.13 Distrib 5.1.7 ...
- 大数据之路week07--day06 (Sqoop 将关系数据库(oracle、mysql、postgresql等)数据与hadoop数据进行转换的工具)
为了方便后面的学习,在学习Hive的过程中先学习一个工具,那就是Sqoop,你会往后机会发现sqoop是我们在学习大数据框架的最简单的框架了. Sqoop是一个用来将Hadoop和关系型数据库中的数据 ...
- 大数据之路week07--day07 (Sqoop 从mysql增量导入到HDFS)
我们之前导入的都是全量导入,一次性全部导入,但是实际开发并不是这样,例如web端进行用户注册,mysql就增加了一条数据,但是HDFS中的数据并没有进行更新,但是又再全部导入一次又完全没有必要. 所以 ...
- 大数据之路week07--day06 (Sqoop 的安装及配置)
Sqoop 的安装配置比较简单. 提供安装需要的安装包和连接mysql的驱动的百度云链接: 链接:https://pan.baidu.com/s/1pdFj0u2lZVFasgoSyhz-yQ 提取码 ...
- 大数据框架开发基础之Sqoop(1) 入门
Sqoop是一款开源的工具,主要用于在Hadoop(Hive)与传统的数据库(mysql.postgresql...)间进行数据的传递,可以将一个关系型数据库(例如 : MySQL ,Oracle , ...
- 大数据之路week07--day05 (一个基于Hadoop的数据仓库建模工具之一 HIve)
什么是Hive? 我来一个短而精悍的总结(面试常问) 1:hive是基于hadoop的数据仓库建模工具之一(后面还有TEZ,Spark). 2:hive可以使用类sql方言,对存储在hdfs上的数据进 ...
- 大数据之路week07--day04 (YARN,Hadoop的优化,combline,join思想,)
hadoop 的计算特点:将计算任务向数据靠拢,而不是将数据向计算靠拢. 特点:数据本地化,减少网络io. 首先需要知道,hadoop数据本地化是指的map任务,reduce任务并不具备数据本地化特征 ...
- 大数据之路week06--day07(Hadoop生态圈的介绍)
Hadoop 基本概念 一.Hadoop出现的前提环境 随着数据量的增大带来了以下的问题 (1)如何存储大量的数据? (2)怎么处理这些数据? (3)怎样的高效的分析这些数据? (4)在数据增长的情况 ...
- 大数据之路week04--day06(I/O流阶段一 之异常)
从这节开始,进入对I/O流的系统学习,I/O流在往后大数据的学习道路上尤为重要!!!极为重要,必须要提起重视,它与集合,多线程,网络编程,可以说在往后学习或者是工作上,起到一个基石的作用,没了地基,房 ...
随机推荐
- PHPExcel 中文使用手册参数详解 三
设置excel的属性:创建人$objPHPExcel->getProperties()->setCreator("Maarten Balliauw");最后修改人$ob ...
- POJ1191 棋盘分割
Time Limit: 1000MS Memory Limit: 10000K Total Submissions: Accepted: 题目链接: http://poj.org/problem?id ...
- ubuntu samba 服务器搭建
最近总是在搭建 samba 环境,写在笔记上记录下以备后用,长时间不操作了肯定会忘记. Linux 版本:Ubuntu 18.04 具体的操作命令: 1. 安装: sudo apt-get insta ...
- idea设置内存大小
1.打开idea安装路径下bin,编辑.vmoptions两个文件 然后重启一下idea 2.直接打开idea的.vmoptions文件进行编辑
- Windows网络命令的相关指令(1)
1.Ipconfig 该命令可以检查网络接口配置.如果用户系统不能到达远程主机,而同一系统的其他主机可以到达,那么用该命令对这种故障进行判断是有必要的.当主机能到达远程主机但不能到达本网主机时,则表示 ...
- SpringBoot + Mybatis搭建完整的项目架构
准备工作: Java开发环境 已安装 springboot 插件(STS)的 Eclipse MySQL服务 一. 创建 springboot 项目 1. 打开Eclipse --> 左上角 ...
- Java开发笔记(一百四十一)JavaFX的列表与表格
下拉框只有在单击时才会弹出所有选项的下拉列表,这固然节省了有限的界面空间,但有时候又需要把所有选项都固定展示到窗口上.像这种平铺的列表控件,Swing给出的控件名称是ListBox,而JavaFX提供 ...
- get merge --no-ff和git merge区别、git fetch和git pull的区别
get merge --no-ff和git merge区别 git merge -–no-ff可以保存你之前的分支历史.能够更好的查看 merge历史,以及branch 状态. git merge则不 ...
- native function 'Window_sendPlatformMessage' (4 arguments) cannot be found
https://github.com/pauldemarco/flutter_blue/issues/140 https://github.com/flutter/flutter/issues/168 ...
- CSS ID选择器&通配选择器
ID选择器 ID(IDentity)是编号的意思,一般指定标签在HTML文档中的唯一编号.ID选择器和标签选择器.类选择器的作用范围不同. ID选择器仅仅定义一个对下对象的样式,而标签选择器和类选择器 ...