Spark 宽窄依赖和stage的划分
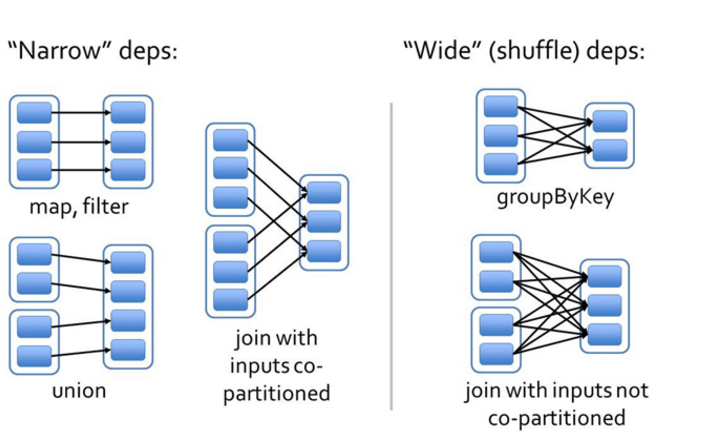
窄依赖
父RDD和子RDD partition之间的关系是一对一的,或者父RDD一个partition只对应一个子RDD的partition情况下的父RDD和子RDD partition关系是多对一的。
不会有shuffle的产生,父RDD的一个分区去到子RDD的一个分区。
多对一或者一对一
可以理解为独生子女
宽依赖
父RDD与子RDD partition之间的关系是一对多。
会有shuffle的产生,父RDD的一个分区的数据去到子RDD的不同分区里面。
一对多
可以理解为超生
常见的宽窄依赖
窄依赖:filter map flatmap mapPartitions
宽依赖:reduceByKey grupByKey combineByKey,sortByKey, join(no copartition)
Stage
Spark任务会根据RDD之间的依赖关系,形成一个DAG有向无环图,DAG会提交给DAGScheduler,DAGScheduler会把DAG划分相互依赖的多个stage
划分stage的整体思路
从后往前推,遇到宽依赖就断开,划分为一个stage;遇到窄依赖就将这个RDD加入该stage中。
Spark 宽窄依赖和stage的划分的更多相关文章
- 【Spark篇】--Spark中的宽窄依赖和Stage的划分
一.前述 RDD之间有一系列的依赖关系,依赖关系又分为窄依赖和宽依赖. Spark中的Stage其实就是一组并行的任务,任务是一个个的task . 二.具体细节 窄依赖 父RDD和子RDD parti ...
- Spark技术内幕:Stage划分及提交源码分析
http://blog.csdn.net/anzhsoft/article/details/39859463 当触发一个RDD的action后,以count为例,调用关系如下: org.apache. ...
- spark 源码分析之十九 -- DAG的生成和Stage的划分
上篇文章 spark 源码分析之十八 -- Spark存储体系剖析 重点剖析了 Spark的存储体系.从本篇文章开始,剖析Spark作业的调度和计算体系. 在说DAG之前,先简单说一下RDD. 对RD ...
- Spark Stage 的划分
Spark作业调度 对RDD的操作分为transformation和action两类,真正的作业提交运行发生在action之后,调用action之后会将对原始输入数据的所有transformation ...
- 021 RDD的依赖关系,以及造成的stage的划分
一:RDD的依赖关系 1.在代码中观察 val data = Array(1, 2, 3, 4, 5) val distData = sc.parallelize(data) val resultRD ...
- stage的划分
stage的划分是以shuffle操作作为边界的,遇到一个宽依赖就分一个stage 一个Job会被拆分为多组Task,每组任务被称为一个Stage就像Map Stage, Reduce Stage.S ...
- 窄依赖与宽依赖&stage的划分依据
RDD根据对父RDD的依赖关系,可分为窄依赖与宽依赖2种. 主要的区分之处在于父RDD的分区被多少个子RDD分区所依赖,如果一个就为窄依赖,多个则为宽依赖.更好的定义应该是: 窄依赖的定义是子RDD的 ...
- Spark技术内幕:Stage划分及提交源代码分析
当触发一个RDD的action后.以count为例,调用关系例如以下: org.apache.spark.rdd.RDD#count org.apache.spark.SparkContext#run ...
- 【Spark工作原理】stage划分原理理解
Job->Stage->Task开发完一个应用以后,把这个应用提交到Spark集群,这个应用叫Application.这个应用里面开发了很多代码,这些代码里面凡是遇到一个action操作, ...
随机推荐
- LeetCode_405. Convert a Number to Hexadecimal
405. Convert a Number to Hexadecimal Easy Given an integer, write an algorithm to convert it to hexa ...
- 【414 error】nginx GET请求过长导致414错误
server{ ... } 在上面一段配置中添加如下两行 client_header_buffer_size 5120k; large_client_header_buffers 5120k; 并重启 ...
- IEDA中使用阿里插件Alibaba Cloud Toolkit和Arthas(阿尔萨斯)
在 IntelliJ IDEA 中安装和配置 Cloud Toolkit 在 IntelliJ IDEA 中安装和配置 Cloud Toolkit 后,您可以将本地应用快速部署到阿里云 ECS.EDA ...
- consul集群搭建以及ACL配置
由于时间匆忙,要是有什么地方没有写对的,请大佬指正,谢谢.文章有点水,大佬勿喷这篇博客不回去深度的讲解consul中的一些知识,主要分享的我在使用的时候的一些操作和遇见的问题以及解决办法.当然有些东西 ...
- 一文读懂ZooKeeper (转)
什么是ZooKeeper ZooKeeper 是一个分布式的,开放源码的分布式应用程序协同服务.ZooKeeper 的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集 ...
- java面试 (八)- 关于减少if else
if else一般不建议嵌套超过三层,如果一段代码存在过多的if else嵌套,就会严重降低可读性.那么如何降低if else的嵌套数呢? 1:把接口分为外部和内部接口,所有空值判断放在外部接口完成: ...
- (转)在高分辨率下eclipse,STS,等软件工具栏图标过小的问题方法总结
背景:在高分辨率情况下,sts工具栏图标超小,肉眼看不清.按照方法二能够满足需求,开心 https://blog.csdn.net/u012687923/article/details/8032437 ...
- C++中的虚函数以及虚函数表
一.虚函数的定义 被virtual关键字修饰的成员函数,目的是为了实现多态 ps: 关于多态[接口和实现分离,父类指针指向子类的实例,然后通过父类指针调用子类的成员函数,这样可以让父类指针拥有多种形态 ...
- IDEA 自定义代码模板
IDEA 自定义代码模板操作步骤:
- Java开发笔记(一百三十六)JavaFX的窗格
虽然Java自诞生之初就推出了AWT,紧接着第二版又推出升级后的Swing,打算在桌面开发这块大展拳脚:可是后来Java在服务器开发上大放异彩,在桌面开发上反而停滞不前,可谓失之J2SE收之J2EE. ...