离散型特征编码方式:one-hot与哑变量
在机器学习问题中,我们通过训练数据集学习得到的其实就是一组模型的参数,然后通过学习得到的参数确定模型的表示,最后用这个模型再去进行我们后续的预测分类等工作。在模型训练过程中,我们会对训练数据集进行抽象、抽取大量特征,这些特征中有离散型特征也有连续型特征。若此时你使用的模型是简单模型(如LR),那么通常我们会对连续型特征进行离散化操作,然后再对离散的特征,进行one-hot编码或哑变量编码。这样的操作通常会使得我们模型具有较强的非线性能力。那么这两种编码方式是如何进行的呢?它们之间是否有联系?又有什么样的区别?是如何提升模型的非线性能力的呢?下面我们一一介绍:
one-hot encoding
关于one-hot编码的具体介绍,可以参考我之前的一篇博客,博客地址:特征提取方法: one-hot 和 IF-IDF。这里,不再详细介绍。one-hot的基本思想:将离散型特征的每一种取值都看成一种状态,若你的这一特征中有N个不相同的取值,那么我们就可以将该特征抽象成N种不同的状态,one-hot编码保证了每一个取值只会使得一种状态处于“激活态”,也就是说这N种状态中只有一个状态位值为1,其他状态位都是0。举个例子,假设我们以学历为例,我们想要研究的类别为小学、中学、大学、硕士、博士五种类别,我们使用one-hot对其编码就会得到:

dummy encoding
哑变量编码直观的解释就是任意的将一个状态位去除。还是拿上面的例子来说,我们用4个状态位就足够反应上述5个类别的信息,也就是我们仅仅使用前四个状态位 [0,0,0,0] 就可以表达博士了。只是因为对于一个我们研究的样本,他已不是小学生、也不是中学生、也不是大学生、又不是研究生,那么我们就可以默认他是博士,是不是。(额,当然他现实生活也可能上幼儿园,但是我们统计的样本中他并不是,^-^)。所以,我们用哑变量编码可以将上述5类表示成:

one-hot编码和dummy编码:区别与联系
通过上面的例子,我们可以看出它们的“思想路线”是相同的,只是哑变量编码觉得one-hot编码太罗嗦了(一些很明显的事实还说的这么清楚),所以它就很那么很明显的东西省去了。这种简化不能说到底好不好,这要看使用的场景。下面我们以一个例子来说明:
假设我们现在获得了一个模型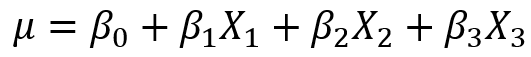 ,这里自变量满足
,这里自变量满足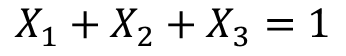 (因为特征是one-hot获得的,所有只有一个状态位为1,其他都为了0,所以它们加和总是等于1),故我们可以用
(因为特征是one-hot获得的,所有只有一个状态位为1,其他都为了0,所以它们加和总是等于1),故我们可以用 表示第三个特征,将其带入模型中,得到:
表示第三个特征,将其带入模型中,得到:
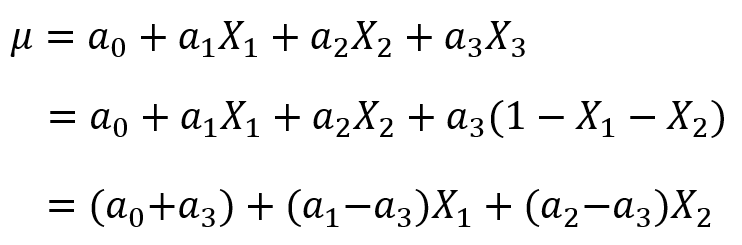
这时,我们就惊奇的发现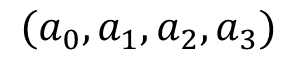 和
和 这两个参数是等价的!那么我们模型的稳定性就成了一个待解决的问题。这个问题这么解决呢?有三种方法:
这两个参数是等价的!那么我们模型的稳定性就成了一个待解决的问题。这个问题这么解决呢?有三种方法:
(1)使用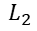 正则化手段,将参数的选择上加一个限制,就是选择参数元素值小的那个作为最终参数,这样我们得到的参数就唯一了,模型也就稳定了。
正则化手段,将参数的选择上加一个限制,就是选择参数元素值小的那个作为最终参数,这样我们得到的参数就唯一了,模型也就稳定了。
(2)把偏置项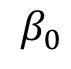 去掉,这时我们发现也可以解决同一个模型参数等价的问题。
去掉,这时我们发现也可以解决同一个模型参数等价的问题。
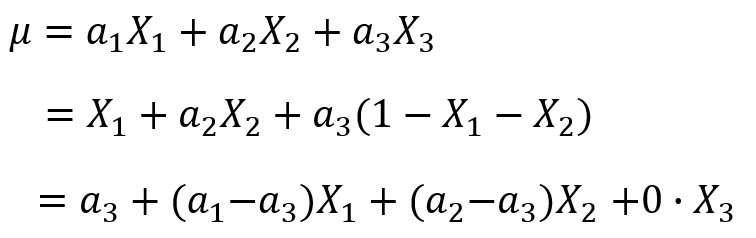
因为有了bias项,所以和我们去掉bias项的模型是完全不同的模型,不存在参数等价的问题。
(3)再加上bias项的前提下,使用哑变量编码代替one-hot编码,这时去除了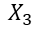 ,也就不存在之前一种特征可以用其他特征表示的问题了。
,也就不存在之前一种特征可以用其他特征表示的问题了。
总结:我们使用one-hot编码时,通常我们的模型不加bias项 或者 加上bias项然后使用正则化手段去约束参数;当我们使用哑变量编码时,通常我们的模型都会加bias项,因为不加bias项会导致固有属性的丢失。
选择建议:我感觉最好是选择正则化 + one-hot编码;哑变量编码也可以使用,不过最好选择前者。虽然哑变量可以去除one-hot编码的冗余信息,但是因为每个离散型特征各个取值的地位都是对等的,随意取舍未免来的太随意。
连续值的离散化为什么会提升模型的非线性能力?
简单的说,使用连续变量的LR模型,模型表示为公式(1),而使用了one-hot或哑变量编码后的模型表示为公式(2)
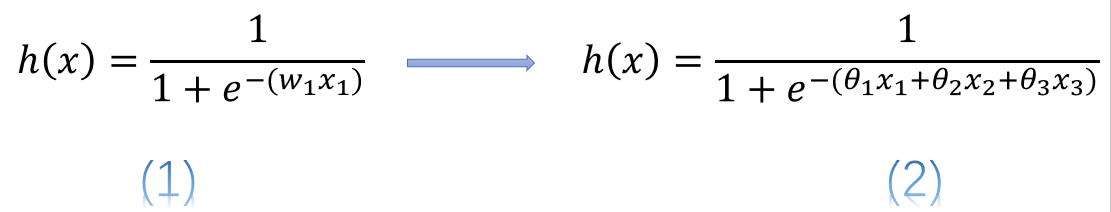
式中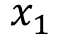 表示连续型特征,
表示连续型特征,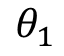 、
、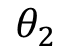 、
、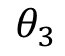 分别是离散化后在使用one-hot或哑变量编码后的若干个特征表示。这时我们发现使用连续值的LR模型用一个权值去管理该特征,而one-hot后有三个权值管理了这个特征,这样使得参数管理的更加精细,所以这样拓展了LR模型的非线性能力。
分别是离散化后在使用one-hot或哑变量编码后的若干个特征表示。这时我们发现使用连续值的LR模型用一个权值去管理该特征,而one-hot后有三个权值管理了这个特征,这样使得参数管理的更加精细,所以这样拓展了LR模型的非线性能力。
这样做除了增强了模型的非线性能力外,还有什么好处呢?这样做了我们至少不用再去对变量进行归一化,也可以加速参数的更新速度;再者使得一个很大权值管理一个特征,拆分成了许多小的权值管理这个特征多个表示,这样做降低了特征值扰动对模型为稳定性影响,也降低了异常数据对模型的影响,进而使得模型具有更好的鲁棒性。
离散型特征编码方式:one-hot与哑变量的更多相关文章
- 【彩票】彩票预测算法(一):离散型马尔可夫链模型C#实现
前言:彩票是一个坑,千万不要往里面跳.任何预测彩票的方法都不可能100%,都只能说比你盲目去买要多那么一些机会而已. 已经3个月没写博客了,因为业余时间一直在研究彩票,发现还是有很多乐趣,偶尔买买,娱 ...
- HotSpot关联规则算法(2)-- 挖掘连续型和离散型数据
本篇代码可在 http://download.csdn.net/detail/fansy1990/8502323下载. 前篇<HotSpot关联规则算法(1)-- 挖掘离散型数据>分析了离 ...
- 【年终分享】彩票数据预测算法(一):离散型马尔可夫链模型实现【附C#代码】
原文:[年终分享]彩票数据预测算法(一):离散型马尔可夫链模型实现[附C#代码] 前言:彩票是一个坑,千万不要往里面跳.任何预测彩票的方法都不可能100%,都只能说比你盲目去买要多那么一些机会而已. ...
- ROM型启动方式概述
ROM 型启动方式概述 所有的VxWorks 内核映像类型中,只有VxWorks 类型使用的bootrom 引导程序进行启动,此时VxWorks 内核映像放置在主机端,由目标板bootrom 完成Vx ...
- 处理离散型特征和连续型特征共存的情况 归一化 论述了对离散特征进行one-hot编码的意义
转发:https://blog.csdn.net/lujiandong1/article/details/49448051 处理离散型特征和连续型特征并存的情况,如何做归一化.参考博客进行了总结:ht ...
- 机器学习实战基础(十一):sklearn中的数据预处理和特征工程(四) 数据预处理 Preprocessing & Impute 之 处理分类特征:编码与哑变量
处理分类特征:编码与哑变量 在机器学习中,大多数算法,譬如逻辑回归,支持向量机SVM,k近邻算法等都只能够处理数值型数据,不能处理文字,在sklearn当中,除了专用来处理文字的算法,其他算法在fit的 ...
- 含有分类变量(categorical variable)的逻辑回归(logistic regression)中虚拟变量(哑变量,dummy variable)的理解
版权声明:本文为博主原创文章,博客地址:,欢迎大家相互转载交流. 使用R语言做逻辑回归的时候,当自变量中有分类变量(大于两个)的时候,对于回归模型的结果有一点困惑,搜索相关知识发现不少人也有相同的疑问 ...
- one-hot encoding与哑变量的区别
one-hot encoding与哑变量的区别 one-hot比哑变量的特征位多一位,即哑变量是精简版的one-hot,即在线性回归中用截距项来表示最后一维,但由于最初很难分辨特征的主次关系,且机器学 ...
- 数据预处理 | 使用 OneHotEncoder 及 get_dummuies 将分类型数据转变成哑变量矩阵
[分类数据的处理] 问题: 在数据建模过程中,很多算法或算法实现包无法直接处理非数值型的变量,如 KMeans 算法基于距离的相似度计算,而字符串则无法直接计算距离 如: 性别中的男和女 [0,1] ...
随机推荐
- 实战系列之 Node.js 玩转 Java
这些年以来,Node.js的兴起,JavaScript已经从当年的“世界最被误解的语言”变成了“世界最流行的语言”.且其发展之势,从语言本身的进化,库和包的增长,工具支持的完善,star项目和领域解决 ...
- GCD SUM 强大的数论,容斥定理
GCD SUM Time Limit: 8000/4000MS (Java/Others) Memory Limit: 128000/64000KB (Java/Others) SubmitStatu ...
- handlebar JS模板使用笔记
直接上代码: (定义模板) (编译注入) ***知识点*** //数据必须为Json数据(强调:jsonp数据不行,和json是两种数据,jsonp多了callback回调函数来包裹json数据) 遍 ...
- sql server 2000的安装
一.安装sql 二.启动sql 三.查看sql版本 RTM版本,需要打补丁 四.安装SP4
- HDU1411 欧拉四面体
用向量解决: 三角形面积:S=1/2*|x1*y2-x2*y1|; (粗体表示向量) 三棱锥体积:V=1/6*(OA*OB)*OC 不知道哪里去找的代码,毕竟很线性代数矩阵什么的很头疼,晚上 ...
- WebApi实现验证授权Token,WebApi生成文档等
using System; using System.Linq; using System.Web; using System.Web.Http; using System.Web.Security; ...
- c# Socket通讯中关于粘包,半包的处理,加分割符
using System; using System.Collections.Generic; using System.Text; using System.Net.Sockets; using S ...
- SQL SERVER 根据地图经纬度计算距离函数
前些天客户提出一个这样的要求:一个手机订餐网,查询当前所在位置的5公里范围的酒店,然后客户好去吃饭. 拿到这个请求后,不知道如何下手,静静地想了一下,在酒店的表中增加两个字段,用来存储酒店所在的经度和 ...
- django celery的分布式异步之路(二) 高并发
当你跑通了前面一个demo,博客地址:http://www.cnblogs.com/kangoroo/p/7299920.html,那么你的分布式异步之旅已经起步了. 性能和稳定性是web服务的核心评 ...
- Linux基础命令讲解(二)
Linux命令基本格式: 命令 [参数] [路径文件] 方括号内容可省略 查看命令帮助手段: 1 man 命令名 (man 还可以获取配置文件,函数的帮助) 2 命令 --help 3 help 命令 ...