数据预处理 | 使用 OneHotEncoder 及 get_dummuies 将分类型数据转变成哑变量矩阵
【分类数据的处理】
问题:
在数据建模过程中,很多算法或算法实现包无法直接处理非数值型的变量,如 KMeans 算法基于距离的相似度计算,而字符串则无法直接计算距离
如:
性别中的男和女 [0,1] [1,0]
用户的价值度分为高、中、低
处理方法:
将字符串表示的 分类特征 转换成 数值 类型(哑变量矩阵)
导入数据:
import pandas as pd
from sklearn.preprocessing import OneHotEncoder # 生成数据
df = pd.DataFrame({'id': [3566841, 6541227, 3512441],
'sex': ['male', 'Female', 'Female'],
'level': ['high', 'low', 'middle'],
'score': [1, 2, 3]})

方法 1 :使用 sklearn 库的 OneHotEncoder
# 获得ID列(还保留二维的形式,等一会儿还要拼回去)
id_data = df[['id']]
# 指定要转换的列
test_data = df.iloc[:,1:] # 建立标志转换模型对象(也称为哑编码对象)
onehot_model = OneHotEncoder()
df1 = onehot_model.fit_transform(test_data).toarray() # 拼接
df_all = pd.concat((id_data, pd.DataFrame(df1)), axis=1)

完成转换~
注:
1> 通过 OneHotEncoder 后,得到一个矩阵对象,
# 得到的 df1 是一个矩阵对象 <3x8 sparse matrix of type '<class 'numpy.float64'>'
df1 = onehot_model.fit_transform(test_data)

2> 矩阵进行 toarray() 后,得到 array 对象, 得到的 array 要进一步转化成 DataFrame,才能使用 pd.concat 完成拼接
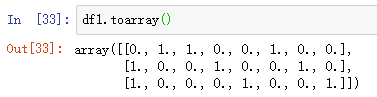
df1 = pd.DataFrame(df1.toarray())
df_all = pd.concat([id_data,df1],axis=1)
方法二:使用 pandas 的 get_dummuies
此方法只会对非数值类型的数据做转换
id_data = df.id
test_data = df.iloc[:,1:] test_data_dum = pd.get_dummies(test_data) # 核心代码
df_dum = pd.concat([id_data, test_data_dum],axis=1)
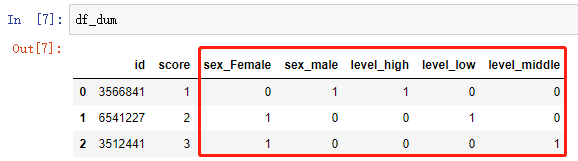
保留数值型特征 score,对非数值型的 sex 和 level 进行了转换
数据预处理 | 使用 OneHotEncoder 及 get_dummuies 将分类型数据转变成哑变量矩阵的更多相关文章
- 机器学习实战基础(十一):sklearn中的数据预处理和特征工程(四) 数据预处理 Preprocessing & Impute 之 处理分类特征:编码与哑变量
处理分类特征:编码与哑变量 在机器学习中,大多数算法,譬如逻辑回归,支持向量机SVM,k近邻算法等都只能够处理数值型数据,不能处理文字,在sklearn当中,除了专用来处理文字的算法,其他算法在fit的 ...
- sklearn preprocessing 数据预处理(OneHotEncoder)
1. one hot encoder sklearn.preprocessing.OneHotEncoder one hot encoder 不仅对 label 可以进行编码,还可对 categori ...
- Python数据预处理:机器学习、人工智能通用技术(1)
Python数据预处理:机器学习.人工智能通用技术 白宁超 2018年12月24日17:28:26 摘要:大数据技术与我们日常生活越来越紧密,要做大数据,首要解决数据问题.原始数据存在大量不完整.不 ...
- 吴裕雄 python 机器学习——数据预处理二元化OneHotEncoder模型
from sklearn.preprocessing import OneHotEncoder #数据预处理二元化OneHotEncoder模型 def test_OneHotEncoder(): X ...
- 机器学习实战基础(十二):sklearn中的数据预处理和特征工程(五) 数据预处理 Preprocessing & Impute 之 处理分类特征:处理连续性特征 二值化与分段
处理连续性特征 二值化与分段 sklearn.preprocessing.Binarizer根据阈值将数据二值化(将特征值设置为0或1),用于处理连续型变量.大于阈值的值映射为1,而小于或等于阈值的值 ...
- 数据准备<3>:数据预处理
数据预处理是指因为算法或者分析需要,对经过数据质量检查后的数据进行转换.衍生.规约等操作的过程.整个数据预处理工作主要包括五个方面内容:简单函数变换.标准化.衍生虚拟变量.离散化.降维.本文将作展开介 ...
- 【sklearn】数据预处理 sklearn.preprocessing
数据预处理 标准化 (Standardization) 规范化(Normalization) 二值化 分类特征编码 推定缺失数据 生成多项式特征 定制转换器 1. 标准化Standardization ...
- 第一章:AI人工智能 の 数据预处理编程实战 Numpy, Pandas, Matplotlib, Scikit-Learn
本课主题 数据中 Independent 变量和 Dependent 变量 Python 数据预处理的三大神器:Numpy.Pandas.Matplotlib Scikit-Learn 的机器学习实战 ...
- sklearn学习笔记(一)——数据预处理 sklearn.preprocessing
https://blog.csdn.net/zhangyang10d/article/details/53418227 数据预处理 sklearn.preprocessing 标准化 (Standar ...
随机推荐
- Linux运维--15.OpenStack vm使用keepalived 实现负载均衡
外接mariadb集群 实现负载均衡 实验环境 10.0.1.27 galera1 10.0.1.6 galera2 10.0.1.23 galera3 10.0.1.17 harpoxy1 hapr ...
- PyCharm专业版激活+破解到期时间2100年
PyCharm专业版激活+破解到期时间2100年 转载文章:https://blog.51cto.com/13696145/2464312?source=dra 到2020年5月激活码: N7UR85 ...
- 链接github
引用https://www.cnblogs.com/u-1596086/p/11588957.html 第一步:登录git创建项目 右上角头像按钮,点击your repositories 接着绿色按钮 ...
- 【转载】sql-builder介绍
原文链接:sql-builder介绍 关于sql-builder sql-builder尝试使用java对象,通过类SQL的拼接方式,动态快速的生成SQL.它可作为稍后的开源项目ibit-mybati ...
- idea websorm 激活码(2020-1-6 实测可用)最新
2019年1月6日用 ZSI6IiIsImFzc2lnbmVlRW1haWwiOiIiLCJsaWNlbnNlUmVzdHJpY3Rpb24iOiIiLCJjaGVja0NvbmN1cnJlbnR ...
- CF547E Mike and Friends [AC自动机,离线树状数组]
#include <cstdio> #include <queue> #include <vector> #define pb emplace_back using ...
- YARN安装和使用
简介 Yet Another Resource Negotiator ,负责整个集群资源的调度,和管理,支持多框架资源统一调度(HIVE spark flink) 开启yarn 安装hadoop,可以 ...
- QuantLib 金融计算——自己动手封装 Python 接口(2)
目录 QuantLib 金融计算--自己动手封装 Python 接口(2) 概述 如何封装一项复杂功能? 寻找最小功能集合的策略 实践 估计期限结构参数 修改官方接口文件 下一步的计划 QuantLi ...
- JavaSE学习笔记(12)---线程
JavaSE学习笔记(12)---线程 多线程 并发与并行 并发:指两个或多个事件在同一个时间段内发生. 并行:指两个或多个事件在同一时刻发生(同时发生). 在操作系统中,安装了多个程序,并发指的是在 ...
- mysql 连接查询 转换group_concat, find_in_set
1.a表 2.b表 3.连接(a_u_id 对应b表的b_id) select a.a_id,a.a_u_id,group_concat(b.b_name) from a_tb a left join ...