Filebeat轻量级日志采集工具
Beats 平台集合了多种单一用途数据采集器。这些采集器安装后可用作轻量型代理,从成百上千或成千上万台机器向 Logstash 或 Elasticsearch 发送数据。
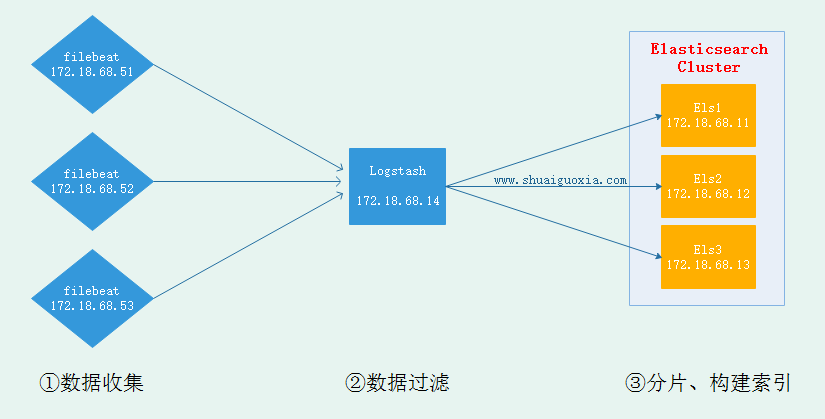
一、架构图
此次试验基于前几篇文章,需要先基于前几篇文章搭建基础环境。
二、安装Filebeat
- 下载并安装Filebeat
wget https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-6.0.1-x86_64.rpm
yum install ./filebeat-6.0.1-x86_64.rpm
- 修改Filebeat配置文件
vim /etc/filebeat/filebeat.yml # 主配置文件
\- type: log # 文档类型
paths:
\- /var/log/httpd/access.log* # 从哪里读入数据
# 输出在elasticsearch与logstash二选一即可
output.elasticsearch: #将数据输出到Elasticsearch。与下面的logstash二者选一
hosts: ["localhost:9200"]
output.logstash: # 将数据传送到logstash,要配置logstash使用beats接收
hosts: ["172.18.68.14:5044"]
- 启动Filebeat
systemctl start filebeat
三、配置Filebeat
- 配置Logstash接收来自Filebeat采集的数据
vim /etc/logstash/conf.d/test.conf
input {
beats {
port => 5044 # 监听5044用于接收Filebeat传来数据
}
}
filter {
grok {
match => {
"message" => "%{COMBINEDAPACHELOG}" # 匹配HTTP的日志
}
remove_field => "message" # 不显示原信息,仅显示匹配后
}
}
output {
elasticsearch {
hosts => ["http://172.18.68.11:9200","http://172.18.68.12:9200","http://172.18.68.13:9200"] # 集群IP
index => "logstash-%{+YYYY.MM.dd}"
action => "index"
document_type => "apache_logs"
}
}
- 启动Logstash
/usr/share/logstash/bin/logstash -f /etc/logstash/conf.d/test.conf
四、模拟日志访问
通过curl命令来模拟客户访问,生成访问日志
curl 127.0.0.1
curl 172.18.68.51
curl 172.18.68.52
curl 172.18.68.53
五、验证信息
清除之前实验的旧数据(删除时要在对话框中输入删除),然后可以看到filebeat采集数据经过Logtash过滤再送给Elasticsearch的数据。
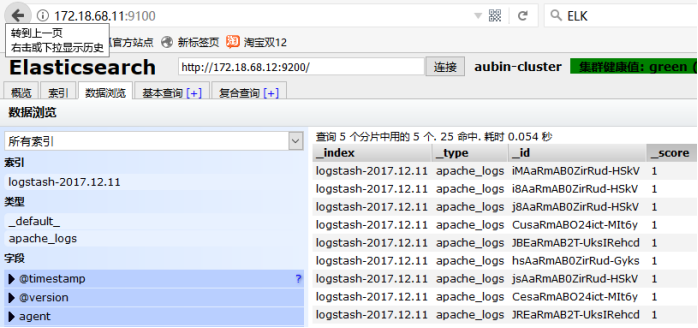
扩展
随着ELK日志系统逐渐升级,现在已经能基于Filebeat采集各节点日志,Logstash过滤、修剪数据,最后到ELasticsearch中进行索引构建、分词、构建搜索引擎。现在可以基于Elasticsearch的Head查看在浏览器中查看,但是Head仅仅能简单查看并不能有效进行数据分析、有好展示。要想进行数据分析、有好展示那就需要用到Kibana,Kibana依然放在下一篇文章中讲解,这里先放上架构图。

Filebeat轻量级日志采集工具的更多相关文章
- filebeat + logstash 日志采集链路配置
1. 概述 一个完整的采集链路的流程如下: 所以要进行采集链路的部署需要以下几个步聚: nginx的配置 filebeat部署 logstash部署 kafka部署 kudu部署 下面将详细说明各个部 ...
- flume 日志采集工具
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并 ...
- logstash日志采集工具的安装部署
1.从官网下载安装包,并通过Xftp5上传到机器集群上 下载logstash-6.2.3.tar.gz版本,并通过Xftp5上传到hadoop机器集群的第一个节点node1上的/opt/uploads ...
- (七)日志采集工具sleuth--分布式链路跟踪(zipkin)
微服务架构上通过业务来划分服务的,通过REST调用,对外暴露的一个接口,可能需要很多个服务协同才能完成这个接口功能,如果链路上任何一个服务出现问题或者网络超时,都会形成导致接口调用失败.随着业务的不断 ...
- 日志采集工具Flume的安装与使用方法
安装Flume,参考厦门大学林子雨教程:http://dblab.xmu.edu.cn/blog/1102/ 并完成案例1 1.案例1:Avro source Avro可以发送一个给定的文件给Flum ...
- ELK太重?试试KFC日志采集
写在前面 ELK三剑客(ElasticSearch,Logstash,Kibana)基本上可以满足日志采集.信息处理.统计分析.可视化报表等一些日志分析的工作,但是对我们来说--太重了,并且技术栈不是 ...
- 一篇文章教你搞懂日志采集利器 Filebeat
关注「开源Linux」,选择"设为星标" 回复「学习」,有我为您特别筛选的学习资料~ 本文使用的Filebeat是7.7.0的版本,文章将从如下几个方面说明: Filebeat是什 ...
- kubernetes常见日志采集问题和解决方案分析
传统日志与kubernetes日志对比 传统服务 目录固定 重启不会丢失 不用关注标准与错误日志输出 容器服务 节点不固定 重启服务会漂移 需要关注标准与错误日志输出 日志文件重启会丢失 日志目录不固 ...
- 基于Flume+LOG4J+Kafka的日志采集架构方案
本文将会介绍如何使用 Flume.log4j.Kafka进行规范的日志采集. Flume 基本概念 Flume是一个完善.强大的日志采集工具,关于它的配置,在网上有很多现成的例子和资料,这里仅做简单说 ...
随机推荐
- Docker 如何支持多种日志方案?- 每天5分钟玩转 Docker 容器技术(88)
将容器日志发送到 STDOUT 和 STDERR 是 Docker 的默认日志行为.实际上,Docker 提供了多种日志机制帮助用户从运行的容器中提取日志信息.这些机制被称作 logging driv ...
- Java基础笔记9
super关键字 表示父类对象. 1.可以调用父类中被重写的方法. 2.还有调用父类中的构造方法.放在子类构造方法的第一行. 不能和this关键字同时出现. final关键字 1.修饰属性.表示常量. ...
- _.contains is not a function
在使用lodash的时候报_.contains is not a function,这是因为从lodash V3.10.1开始,将去掉contains函数,改用includes. 可以换为:_.con ...
- Andrew 机器学习课程笔记
Andrew 机器学习课程笔记 完成 Andrew 的课程结束至今已有一段时间,课程介绍深入浅出,很好的解释了模型的基本原理以及应用.在我看来这是个很好的入门视频,他老人家现在又出了一门 deep l ...
- Linux系列教程(十三)——Linux软件包管理之源码包、脚本安装包
上篇博客我们讲解了网络yum源和光盘yum源的搭建步骤,然后详细介绍了相关的yum命令,yum 最重要是解决了软件包依赖性问题.在安装软件时,我们使用yum命令将会简单方便很多.我们知道yum命令只能 ...
- [原创]Faster R-CNN论文翻译
Faster R-CNN论文翻译 Faster R-CNN是互怼完了的好基友一起合作出来的巅峰之作,本文翻译的比例比较小,主要因为本paper是前述paper的一个简单改进,方法清晰,想法自然.什 ...
- ⑥bootstrap表单使用基础案例
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Python文件夹备份
Python文件夹备份 import os,shutil def file_copy(path1,path2): f2 = [filename1 for filename1 in os.listdir ...
- Python 解LeetCode:671. Second Minimum Node In a Binary Tree
题目在这里,要求一个二叉树的倒数第二个小的值.二叉树的特点是父节点的值会小于子节点的值,父节点要么没有子节点,要不左右孩子节点都有. 分析一下,根据定义,跟节点的值肯定是二叉树中最小的值,剩下的只需要 ...
- OGEngine_2.x中BitmapFont加载后黑屏问题的解决办法
在我使用OGEngine_2.x进行消灭圈圈(星星)游戏的实践的时候,使用BitmapFont对自定义字体进行调用. 原文字体教程如下:http://blog.csdn.net/OrangeGame/ ...