LRU(最近最少使用淘汰算法)基本实现
LRU(Least Recently Used)
出发点:在页式存储管理中,如果一页很长时间未被访问,则它在最近一段时间内也不会被访问,即时间局部性,那我们就把它调出(置换出)内存,相反的,如果一个数据刚刚被访问过,那么该数据很大概率会在未来一段时间内访问。
可以使用栈、队列、链表来简单实现,在InnoDB中,使用适应性hash,来实现热点页的查找(因为快速)。
1. 用栈(数组模拟)简单实现访页逻辑:
#include <iostream>
using namespace std; void conduct(int Size, int Num, int A[]);//处理函数
void print(int a[], int num);//输出函数 int main()
{
int stack_size, num, i, acess[];
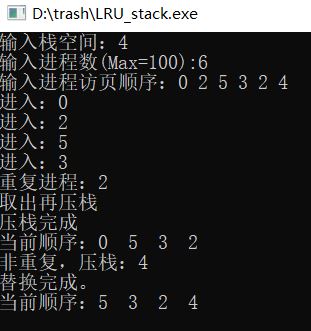
cout << "输入栈空间:" ;
cin >> stack_size;
cout << "输入进程数(Max=100):" ;
cin >> num; cout << "输入进程访页顺序:" ;
for(i=; i<num; i++)
{
cin >> acess[i];
} conduct(stack_size, num, acess); return ;
} void conduct(int Size, int Num, int A[])
{
int j, k, Stack[Size];
for(j=; j<Size; j++)
{
cout << "进入:" << A[j] <<endl;
Stack[j]=A[j];//先处理前几个元素
}
int locate;bool flag;
for(j=Size; j<Num; j++)
{
flag=false;
for(k=; k<Size; k++)
{
if(Stack[k]==A[j])
{
flag=true;
locate=k;
}
}
if(flag==true)//有重复
{
cout << "重复进程:" << A[j] <<endl;
cout << "取出再压栈" <<endl;
int tempp;
for(k=locate; k<Size; k++)
{
Stack[k]=Stack[k+];
}
Stack[Size-]=A[j];
cout << "压栈完成" <<endl;
cout << "当前顺序:"; print(Stack, Size);
}
else
{
cout << "非重复,压栈:" << A[j] <<endl;
for(k=; k<Size-; k++)
{
Stack[k]=Stack[k+];
}
Stack[Size-]=A[j];
cout << "置换完成。" <<endl;
cout << "当前顺序:";
print(Stack, Size);
}
}
} void print(int a[], int num)
{
int k;
for(k=; k<num; k++)
{
cout << a[k] << " ";
}
cout << endl;
}
Code::Blocks 17.12 运行通过!
结果:
2. 使用lis容器实现LRU逻辑
#include <iostream>
#include <list>
#include <vector>
using namespace std; class LRU
{
public:
LRU();
~LRU();
void insret(int x);
void printQ();
private:
list<int> lst;
int count;//当前页数
int max_size = ;//最大容纳页数
}; LRU::LRU()
{
this->count = ;
} LRU::~LRU()
{
} //插入算法,先查找,找到先删除再插入;未找到,直接插入
void LRU::insret(int x)
{
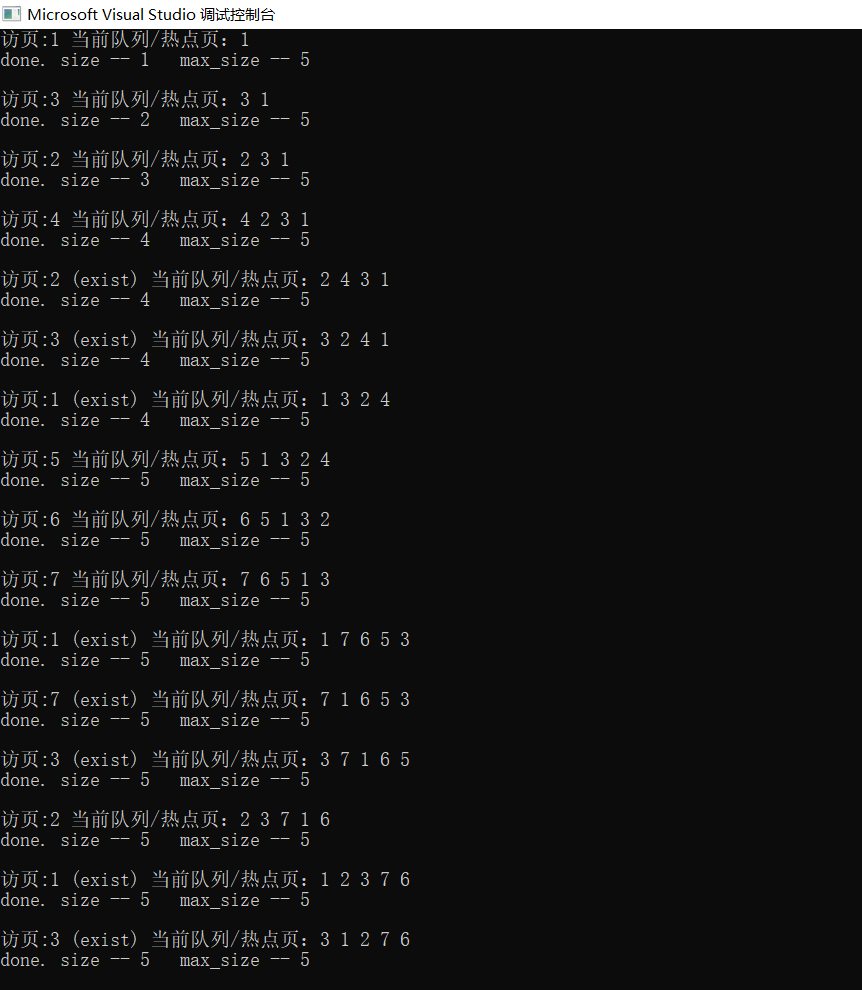
cout << "访页:" << x << " ";
auto res = find(lst.begin(), lst.end(), x);
if (res != lst.end())
{
cout << "(exist)" << " ";
lst.erase(res);
lst.push_front(x);
}
else
{
lst.push_front(x);
this->count++;
}
if (this->count > this->max_size)
{
lst.pop_back();
this->count--;
} printQ();
} //打印list
void LRU::printQ()
{
list<int>::iterator it = this->lst.begin();
cout << "当前队列/热点页:";
for (; it != lst.end(); it++)
{
cout << *it << " ";
}
cout << "\ndone. size -- " << this->count << " " << " max_size -- " << this->max_size << endl << endl;
} int main()
{
LRU lru;
vector<int> test = {, , , , , , , , , , , , , , , };
for (int i : test)
lru.insret(i);
return ;
}
结果:
LRU(最近最少使用淘汰算法)基本实现的更多相关文章
- Golang 随机淘汰算法缓存实现
缓存如果写满, 它必须淘汰旧值以容纳新值, 最近最少使用淘汰算法 (LRU) 是一个不错的选择, 因为你如果最近使用过某些值, 这些值更可能被保留. 你如果构造一个比缓存限制还长的循环, 当循环最后的 ...
- 缓存淘汰算法--LRU算法
1. LRU1.1. 原理 LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是"如果数据最近被访问过,那么将来被访问的几率也 ...
- 缓存淘汰算法---LRU
1. LRU1.1. 原理 LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”. ...
- 【转】缓存淘汰算法系列之1——LRU类
原文地址:http://www.360doc.com/content/13/0805/15/13247663_304901967.shtml 参考地址(一系列关于缓存的,后面几篇也都在这里有):htt ...
- 04 | 链表(上):如何实现LRU缓存淘汰算法?
今天我们来聊聊“链表(Linked list)”这个数据结构.学习链表有什么用呢?为了回答这个问题,我们先来讨论一个经典的链表应用场景,那就是+LRU+缓存淘汰算法. 缓存是一种提高数据读取性能的技术 ...
- 缓存淘汰算法---LRU转
1. LRU1.1. 原理 LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”. ...
- LRU算法---缓存淘汰算法
计算机中的缓存大小是有限的,如果对所有数据都缓存,肯定是不现实的,所以需要有一种淘汰机制,用于将一些暂时没有用的数据给淘汰掉,以换入新鲜的数据进来,这样可以提高缓存的命中率,减少磁盘访问的次数. LR ...
- 淘汰算法 LRU、LFU和FIFO
含义: FIFO:First In First Out,先进先出LRU:Least Recently Used,最近最少使用 LFU:Least Frequently Used,最不经常使用 以上三者 ...
- 数据结构与算法之美 06 | 链表(上)-如何实现LRU缓存淘汰算法
常见的缓存淘汰策略: 先进先出 FIFO 最少使用LFU(Least Frequently Used) 最近最少使用 LRU(Least Recently Used) 链表定义: 链表也是线性表的一种 ...
随机推荐
- Xamarin.Android 制作搜索框
前段时间仿QQ做了一个搜索框样式,个人认为还不错,留在这里给大家做个参考,希望能帮助到有需要的人. 首先上截图(图1:项目中的样式,图2:demo样式): 不多说直接上代码: Main.axml &l ...
- 【zookeeper】4、利用zookeeper,借助观察模式,判断服务器的上下线
首先什么是观察者模式,可以看看我之前的设计模式的文章 https://www.cnblogs.com/cutter-point/p/5249780.html 确定一下,要有观察者,要有被观察者,然后要 ...
- Java多线程之三volatile与等待通知机制示例
原子性,可见性与有序性 在多线程中,线程同步的时候一般需要考虑原子性,可见性与有序性 原子性 原子性定义:一个操作或者多个操作在执行过程中要么全部执行完成,要么全部都不执行,不存在执行一部分的情况. ...
- Java Socket NIO详解(转)
java选择器(Selector)是用来干嘛的? 2009-01-12 22:21jsptdut | 分类:JAVA相关 | 浏览8901次 如题,不要贴api的,上面的写的我看不懂希望大家能给我个通 ...
- WebBrowser使用例子
本文参考了:http://www.cnblogs.com/txw1958/archive/2012/09/24/CSharp-WebBrowser.html 在上文的基础上加入了 一些处理弹出对话框的 ...
- 用主题模型可视化分析911新闻(Python版)
本文由 伯乐在线 - 东狗 翻译,toolate 校稿.未经许可,禁止转载!英文出处:blog.dominodatalab.com.欢迎加入翻译小组. 本文介绍一个将911袭击及后续影响相关新闻文章的 ...
- Hibernate学习(七)———— hibernate中查询方式详解
序言 之前对hibernate中的查询总是搞混淆,不明白里面具体有哪些东西.就是因为缺少总结.在看这篇文章之前,你应该知道的是数据库的一些查询操作,多表查询等 --WH 一.hibernate中的5种 ...
- Java设计模式学习记录-观察者模式
前言 观察者模式也是对象行为模式的一种,又叫做发表-订阅(Publish/Subscribe)模式.模型-视图(Model/View)模式. 咱们目前用的最多的就是各种MQ(Message Queue ...
- vue_drf之视频接口
一.vue-video 1,安装依赖 npm install vue-video-player --save 2,main.js文件中加载组件 require('video.js/dist/video ...
- .NET CORE 实践(2)--对Ubuntu下安装SDK的记录
根据官网Ubuntu安装SDK操作如下: allen@allen-Virtual-Machine:~$ sudo apt-key adv --keyserver apt-mo.trafficmanag ...