recurrent model for visual attention
paper url: https://papers.nips.cc/paper/5542-recurrent-models-of-visual-attention.pdf
year: 2014
abstract
这篇文章出发点是如何减少图像相关任务的计算量, 提出通过使用 attention based RNN 模型建立序列模型(recurrent attention model, RAM), 每次基于上下文和任务来适应性的选择输入的的 image patch, 而不是整张图片, 从而使得计算量独立于图片大小, 从而缓解 CNN 模型中计算量与输入图片的像素数成正比的缺点. 该文通过强化学习的方式来学习任务明确的策略, 从而解决模型是不可微的问题.
RAM 模型在几个图像分类任务上,在处理杂乱图像(cluttered images)时, 它明显优于基于CNN的模型,并且在动态视觉控制问题上,无需明确的训练信号, 它就能学习跟踪一个简单的对象。
introduction
该文将注意力问题视为与视觉环境交互时以目标为导向的序列决策过程。
人类感知的一个重要特性是人们不会倾向于一次完整地处理整个场景。 相反,人们将注意力有选择地集中在视觉空间的某些部分,以便在需要的时间和地点获取信息,并随着时间的推移组合来自不同固定位置(fixation)的信息,以建立场景的内部表示,指导下一步眼睛看下哪里以及决策。 将计算资源聚焦在场景的各部分上节省了“带宽”,因为需要处理的“像素”更少。 但它也大大降低了任务复杂性,因为感兴趣的对象可以置于固定位置(fixation)的中心,并且固定区域外的视觉环境(“混乱”)的不相关特征自然被忽略。
model architecture
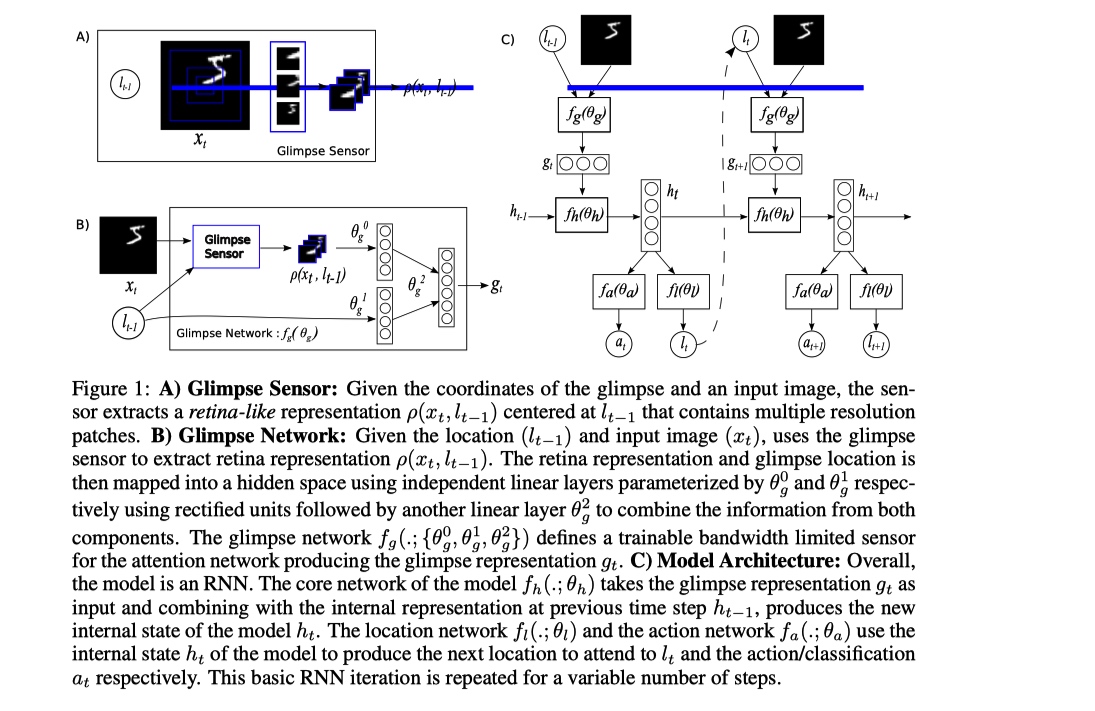 

thought
这篇论文时间比较早, 在当时 CNN backbone 以及目标检测的发展和现在相比相差太多. 在解决 CNN 的计算量问题上, 通过不输出整张图片, 而是利用 RNN 模型建模, 然后使用 attention+强化算法 来决定序列每一个阶段模型看向图片的哪一个 patch, 从而获取与任务相关的关键信息, 过滤掉了无关信息, 从而使得模型计算量独立于图片的输入尺寸, 减小计算量.
利用 RNN 模型来进行视觉任务特征提取, 对于我个人来说是很新颖的思想. 个人觉得, 就视觉 attention 来说, 我感觉不将整张图片作为输入, 而是每次只送入 image patch 的做法是当时妥协的产物. 我觉的视觉 attention 只有在获取全局信息之后, 然后才能基于相关性, 选择的关注一些相关性高的区域来提升处理效率. 如果一开始就是盲人摸象, 我不知道该如何相信系统的决策, ps:个人不了解强化学习相关知识.
总之, 思想很新, 但是实现过于复杂, 而且这种基于局部信息的 attention 感觉并不可靠.
recurrent model for visual attention的更多相关文章
- 论文笔记之: Recurrent Models of Visual Attention
Recurrent Models of Visual Attention Google DeepMind 模拟人类看东西的方式,我们并非将目光放在整张图像上,尽管有时候会从总体上对目标进行把握,但是也 ...
- A Survey of Visual Attention Mechanisms in Deep Learning
A Survey of Visual Attention Mechanisms in Deep Learning 2019-12-11 15:51:59 Source: Deep Learning o ...
- A Model of Saliency-Based Visual Attention for Rapid Scene Analysis
A Model of Saliency-Based Visual Attention for Rapid Scene Analysis 题目:A Model of Saliency-Based Vis ...
- 图像显著性论文(一)—A Model of saliency Based Visual Attention for Rapid Scene Analysis
这篇文章是图像显著性领域最具代表性的文章,是在1998年Itti等人提出来的,到目前为止引用的次数超过了5000,是多么可怕的数字,在它的基础上发展起来的有关图像显著性论文更是数不胜数,论文的提出主要 ...
- 论文笔记之:Multiple Object Recognition With Visual Attention
Multiple Object Recognition With Visual Attention Google DeepMind ICRL 2015 本文提出了一种基于 attention 的用 ...
- paper 27 :图像/视觉显著性检测技术发展情况梳理(Saliency Detection、Visual Attention)
1. 早期C. Koch与S. Ullman的研究工作. 他们提出了非常有影响力的生物启发模型. C. Koch and S. Ullman . Shifts in selective visual ...
- 论文笔记:Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention 2018-08-10 10:15:06 Pap ...
- visual attention
The visual attention mechanism may have at least the following basic components [Tsotsos, et. al. 19 ...
- Paper Reading - Show, Attend and Tell: Neural Image Caption Generation with Visual Attention ( ICML 2015 )
Link of the Paper: https://arxiv.org/pdf/1502.03044.pdf Main Points: Encoder-Decoder Framework: Enco ...
随机推荐
- 启用shopt 选项实现不使用 CD 命令进入目录/文件夹
众所周知,如果没有 cd 命令,我们无法 Linux 中切换目录.这个没错,但我们有一个名为 shopt 的 Linux 内置命令能帮助我们解决这个问题. shopt 是一个 shell 内置命令,用 ...
- PHP判断点是否在多边形区域内外
小谢博客原文地址https://xgs888.top/post/view?id=79 PHP判断点是否在多边形区域内外:根据数学知识的射线法, 射线与几何多边形相交的点的个数为奇数则是在几何内部: 偶 ...
- MRP没生成MRP汇总表
设置:工作日历延长
- 注解 springbootapplication 自动扫描所在包及其子包。会将有注解的加入到spring容器中
注解 springbootapplication 自动扫描所在包及其子包.会将有注解的加入到spring容器中
- [转载] .NET 中可以有类似 JVM 的幻像引用吗?
近日发现一篇不错的文章,文中列举了一些 GC 场景,探讨了 在 .NET 中是需要实现像 JVM 的中的幻像引用.有人质疑其不切实际,也有像 Ayende 大神一言不合就自己做了个 demo. Do ...
- linux 系统工具图
- VMware虚拟机里Centos7的IP地址查看方法
电脑的虚拟机里面安装了一个Cetos 7 ,想用Xshell链接进行操作,发现没有IP显示,需要IP地址,我才能进行连接,用命令ip addr查看下: 发现ens33 没有inet 这个属性,那么就没 ...
- 几道c/c++练习题
1.以下三条输出语句分别输出什么?[C易] char str1[] = "abc"; char str2[] = "abc"; const char str3[ ...
- Linux环境配置错误记录
1. pip install --special_version pip10. 版本. 使用命令: python -m pip install pip== 其中, -m 参数的意思是将库中的pyt ...
- Java设计模式--装饰器模式到Java IO 流
装饰器模式 抽象构件角色:给出一个抽象接口,以规范准备接受附加责任的对象. 具体构件角色:定义准备接受附加责任的对象. 抽象装饰角色:持有一个构件对象的实例,并对应一个与抽象构件接口一致的接口. 具体 ...