Paper Reading - Show, Attend and Tell: Neural Image Caption Generation with Visual Attention ( ICML 2015 )
Link of the Paper: https://arxiv.org/pdf/1502.03044.pdf
Main Points:
- Encoder-Decoder Framework: Encoder uses a convolutional neural network to extract a set of feature vectors which the authors refer to as annotation vectors. The extractor produces L vectors, each of which is a D-dimensional representation corresponding to a part of the image. a = { a1, ..., aL }, ai ∈ RD. In order to obtain a correspondence between the feature vectors and portions of the 2-D image, they extract features from a lower convolutional layer unlike previous work which instead used a fully connected layer. This allows the decoder to selectively focus on certain parts of an image by weighting a subset of all the feature vectors. Decoder uses a LSTM network to produce a caption by generating one word at every time step conditioned on a context vector, the previous hidden state and the previously generated words.
- Two attention-based image caption generators under a common framework: a "soft" deterministic attention mechanism trainable by standard back-propagation methods; and a "hard" stochastic attention mechanism trainable by maximizing an approximate variational lower bound or equivalently by Reinforce.
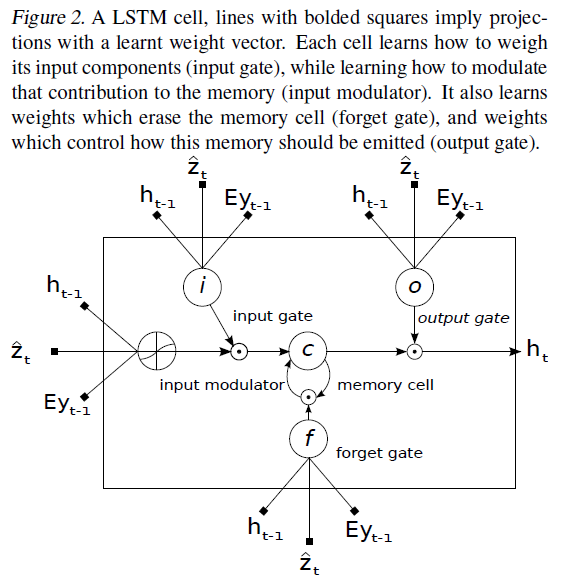
Other Key Points:
- Rather than compress an entire image into a static representation, attention allows for salient features to dynamically come to the forefront as needed. This is especially important when there is a lot of clutter in an image. Using representations ( such as those from the very top layer of a conv net ) that distill information in image down to the most salient objects is one effective solution that has been widely adopted in previous work. Unfortunately, this has one potential drawback of losing information which could be useful for richer, more descriptive captions. Using lower-level representation can help preserve this information.
Paper Reading - Show, Attend and Tell: Neural Image Caption Generation with Visual Attention ( ICML 2015 )的更多相关文章
- [Paper Reading] Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
论文链接:https://arxiv.org/pdf/1502.03044.pdf 代码链接:https://github.com/kelvinxu/arctic-captions & htt ...
- 论文笔记:Show, Attend and Tell: Neural Image Caption Generation with Visual Attention
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention 2018-08-10 10:15:06 Pap ...
- 论文:Show, Attend and Tell: Neural Image Caption Generation with Visual Attention-阅读总结
Show, Attend and Tell: Neural Image Caption Generation with Visual Attention-阅读总结 笔记不能简单的抄写文中的内容,得有自 ...
- Paper Reading - Show and Tell: A Neural Image Caption Generator ( CVPR 2015 )
Link of the Paper: https://arxiv.org/abs/1411.4555 Main Points: A generative model ( NIC, GoogLeNet ...
- [Paper Reading] Show and Tell: A Neural Image Caption Generator
论文链接:https://arxiv.org/pdf/1411.4555.pdf 代码链接:https://github.com/karpathy/neuraltalk & https://g ...
- [Paper Reading] Image Captioning using Deep Neural Architectures (arXiv: 1801.05568v1)
Main Contributions: A brief introduction about two different methods (retrieval based method and gen ...
- Paper Reading - CNN+CNN: Convolutional Decoders for Image Captioning
Link of the Paper: https://arxiv.org/abs/1805.09019 Innovations: The authors propose a CNN + CNN fra ...
- Paper Reading: Stereo DSO
开篇第一篇就写一个paper reading吧,用markdown+vim写东西切换中英文挺麻烦的,有些就偷懒都用英文写了. Stereo DSO: Large-Scale Direct Sparse ...
- Paper Reading - Mind’s Eye: A Recurrent Visual Representation for Image Caption Generation ( CVPR 2015 )
Link of the Paper: https://ieeexplore.ieee.org/document/7298856/ A Correlative Paper: Learning a Rec ...
随机推荐
- javascript入门教程 (2)
这篇我就不铺垫和废话了,我们开始正式进入JS核心语法的学习… 首先我们从基础入手... 一. 基础语法 1.1 区分大小写 JS语法规定变量名是区分大小写的 比如: 变量名 learninpro 和变 ...
- one or more listeners failed to start问题解决思路
今日搭建一个web应用的时候总是遇到tomcat报错:one or more listeners failed to start. Full detail balabale....而且还没有其他提示, ...
- 轻量ORM-SqlRepoEx (七)AspNetCore应用
ORM-SqlRepoEx 是 .Net平台下兼容.NET Standard 2.0,一个实现以Lambda表达式转转换标准SQL语句,使用强类型操作数据的轻量级ORM工具,在减少魔法字串同时,通过灵 ...
- TCP/IP协议族之链路层(二)
TCP/IP学习记录,如有错误请指正,谢谢!!! TCP/IP协议族之链路层(二) 链路层是最底层协议,主要有三个目的: 1. 为IP模块发送和接收IP数据报 2. 为ARP模块发送ARP请求和接收A ...
- python 创建虚拟环境
创建一个文件夹:mkdir tf_env 进入到文件夹内:cd tf_env 创建虚拟环境:python3 -m venv tensorflow-dev 激活虚拟环境:source tensorflo ...
- LightOJ 1203--Guarding Bananas(二维凸包+内角计算)
1203 - Guarding Bananas PDF (English) Statistics Forum Time Limit: 3 second(s) Memory Limit: 32 M ...
- Mac 字典扩充包 包括 app
https://pan.baidu.com/s/1htKUaiWZFZJGO6w9azsbsg
- java读取xml文件的四种方法
Xml代码 <?xml version="1.0" encoding="GB2312"?> <RESULT> <VALUE> ...
- vue调用豆瓣API加载图片403问题
"豆瓣API是有请求次数限制的”,这会引发图片在加载的时候出现403问题,视图表现为“图片加载不出来”,控制台表现为报错403. 其实是豆瓣限制了图片的加载,我自己用了一个办法把图片缓存下来 ...
- MySQL:数据存在则更新,不存在则插入
前提:表结构存在主键或唯一索引,插入数据包含主键或唯一索引而导致记录重复插入失败. 单条记录更新插入: ,,) ,b,c; 多条记录批量更新插入: ,,),(,,) ON DUPLICATE KEY ...