大数据学习之HDFS基本API操作(下)06
hdfs文件流操作方法一:
package it.dawn.HDFSPra; import java.io.BufferedReader;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URI;
import java.net.URISyntaxException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.zookeeper.common.IOUtils;
import org.junit.Before;
import org.junit.Test; /**
* @version 1.0
* @author Dawn
* @date 2019年4月28日22:28:53
* @return hdfs的读写操作。顺便练习一下java的IO操作
*/
public class HdfsReadData02 { public static FileSystem fs=null;
public static String hdfs="hdfs://bigdata11:9000"; @Before
public void init() throws IOException, InterruptedException, URISyntaxException {
//其实这一句我也不是很清楚。不加这个有个异常,我看起来感觉很恶心。不过没有影响。大家加不加都没问题
System.setProperty("hadoop.home.dir", "E:\\hadoop2.7.3\\hadoop-2.7.3");
//1 加载配置
Configuration conf=new Configuration();
//2 构造客服端
fs=FileSystem.get(new URI(hdfs), conf, "root");
} //读数据方式1
@Test
public void testReadData1() throws IllegalArgumentException, IOException {
//1 拿到流
//其实和这个没啥差别fs.copyToLocalFile(new Path("/xxx.txt"), new Path("f:/"));
FSDataInputStream in=fs.open(new Path("/xxx.txt")); byte[] buf=new byte[1024]; in.read(buf); //打印出来
System.out.println(new String(buf)); //记得关闭流
in.close();
fs.close();
} //读数据方式2 (加了一个缓冲流而已)
@Test
public void testReadData2() throws IllegalArgumentException, IOException {
//1 拿到流
FSDataInputStream in=fs.open(new Path("/xxx.txt")); //2.缓冲流
BufferedReader br=new BufferedReader(new InputStreamReader(in, "UTF-8")); //3.按行读取
String line=null; //4:一行一行的读数据
while((line=br.readLine()) != null) {
//打印出来
System.out.println(line);
} //5.关闭资源
br.close();
in.close();
fs.close();
} /*
* 读取hdfs中指定偏移量
*/
@Test
public void testRandomRead() throws IllegalArgumentException, IOException {
//1:拿到流
FSDataInputStream in= fs.open(new Path("/xxx.txt")); in.seek(3); byte[] b=new byte[5]; in.read(b); System.out.println(new String(b)); in.close();
fs.close();
} /**
* 在hdfs中写数据 直接对存在的文件进行写操作
* fs.creat(hdfsFilename,false)
* @param Path f
* @param boolean overwrite
*/
@Test
public void testWriteData() throws IllegalArgumentException, IOException {
//拿到输出流
FSDataOutputStream out=fs.create(new Path("/dawn.txt"),false);//第二个参数。是否覆盖 //2.输入流
FileInputStream in=new FileInputStream("f:/temp/a.txt");//其实我觉得new一个File好一点 byte[] buf=new byte[1024]; int read=0; while((read=in.read(buf)) != -1) { //the total number of bytes read into the buffer, or -1 if there is no more data because the end of the file has been reached. out.write(buf,0,read);
} in.close();
out.close();
fs.close();
} /*
* 在hdfs中写数据 写一个新的数据
*/ @Test
public void testWriteData1() throws IllegalArgumentException, IOException {
//1.创建输出流
FSDataOutputStream out=fs.create(new Path("/haha")); //2.创建输入流
// FileInputStream in=new FileInputStream(new File("f:/temp/data.txt"));//没啥用 //3.写数据
out.write("dawn will success".getBytes()); //4.关闭资源
IOUtils.closeStream(out);
fs.close();
} } hdfs文件流操作方法二:
package it.dawn.HDFSPra; import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException; import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.junit.Before;
import org.junit.Test; /**
* @version 1.0
* @author Dawn
* @date 2019年4月28日23:21:03
* @return 使用IOUtills更为方便
*/
public class HdfsIOUtilsTest { public static String hdfs="hdfs://bigdata11:9000"; public static FileSystem fs=null; public static Configuration conf=null; @Before
public void init() throws IOException, InterruptedException, URISyntaxException { conf =new Configuration();
fs=FileSystem.get(new URI(hdfs), conf, "root");
} /*
* 文件上传HDFS
*
*/
@Test
public void putFileToHDFS() throws IllegalArgumentException, IOException {
//1.获取输入流
FileInputStream fis=new FileInputStream(new File("f:/temp/lol.txt")); //2获取输出流
FSDataOutputStream fos=fs.create(new Path("/dawn/n.txt")); //3 流的拷贝
IOUtils.copyBytes(fis, fos, conf); //4.关闭资源
IOUtils.closeStream(fis);
IOUtils.closeStream(fos);
} /*
* 文件下载HDFS
*/
@Test
public void getFileFromHDFS() throws IllegalArgumentException, IOException {
//1.获取输入流
FSDataInputStream fis=fs.open(new Path("/xxx.txt")); //2.获取输出流
FileOutputStream fos=new FileOutputStream("f:/temp/lala.txt"); //3.流的对拷
IOUtils.copyBytes(fis, fos, conf); //4.关闭资源
IOUtils.closeStream(fos);
IOUtils.closeStream(fis);
} }
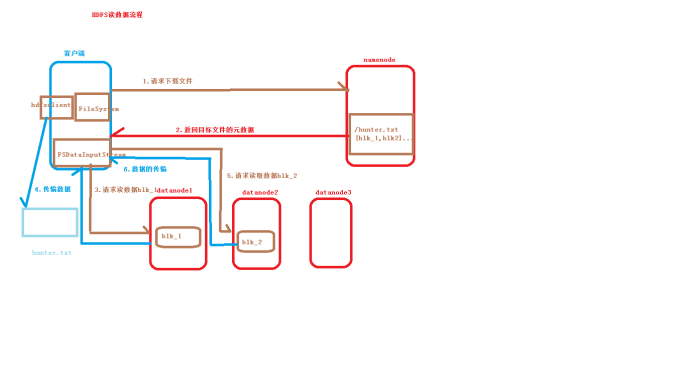
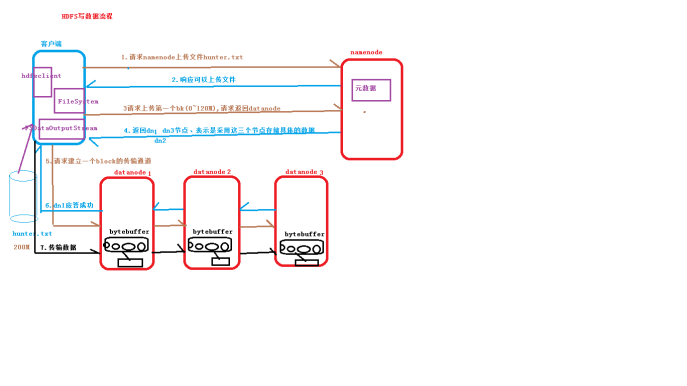
附上读写流程图
大数据学习之HDFS基本API操作(下)06的更多相关文章
- 大数据学习之HDFS基本API操作(上)06
package it.dawn.HDFSPra; import java.io.FileNotFoundException; import java.io.IOException; import ja ...
- 大数据学习之HDFS基本命令操作05
1)hdfs的客户端 1.网页形式->测试用 http://192.168.40.11:50070/dfshealth.html#tab-overview 2.命令行形式->测试用 3.企 ...
- 大数据学习之hdfs集群安装部署04
1-> 集群的准备工作 1)关闭防火墙(进行远程连接) systemctl stop firewalld systemctl -disable firewalld 2)永久修改设置主机名 vi ...
- 大数据学习笔记——HDFS写入过程源码分析(1)
HDFS写入过程方法调用逻辑 & 源码注释解读 前一篇介绍HDFS模块的博客中,我们重点从实践角度介绍了各种API如何使用以及IDEA的基本安装和配置步骤,而从这一篇开始,将会正式整理HDFS ...
- 大数据学习笔记——HDFS写入过程源码分析(2)
HDFS写入过程注释解读 & 源码分析 此篇博客承接上一篇未讲完的内容,将会着重分析一下在Namenode获取到元数据后,具体是如何向datanode节点写入真实的数据的 1. 框架图展示 在 ...
- 大数据学习笔记——HDFS理论知识之编辑日志与镜像文件
HDFS文件系统——编辑日志和镜像文件详细介绍 我们知道,启动Hadoop之后,在主节点下会产生Namenode,即名称节点进程,该节点的目录下会保存一份元数据,用来记录文件的索引,而在从节点上即Da ...
- 大数据学习之HDFS的工作机制07
1:namenode+secondaryNameNode工作机制 2:datanode工作机制 3:HDFS中的通信(代理对象RPC) 下面用代码来实现基本的原理 1:服务端代码 package it ...
- 大数据学习笔记——Hadoop编程实战之HDFS
HDFS基本API的应用(包含IDEA的基本设置) 在上一篇博客中,本人详细地整理了如何从0搭建一个HA模式下的分布式Hadoop平台,那么,在上一篇的基础上,我们终于可以进行编程实操了,同样,在编程 ...
- 大数据学习路线,来qun里分享干货,
一.Linux lucene: 全文检索引擎的架构 solr: 基于lucene的全文搜索服务器,实现了可配置.可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面. 推荐一个大数据学习群 ...
随机推荐
- PHP 消息队列 详解
前言:之前做过的一些项目中有时候会接触到消息队列,但是对消息队列并没有一个很清楚的认知,本篇文章将会详细分析和归纳一些笔记,以供后续学习. 一.消息对列概念 从本质上说消息对列就是一个队列结构的中间件 ...
- MFC:位图和图标的设置
一. 图标的设置 加载图标 API函数:AfxGetApp()->LoadIconW(); 2. 显示图标 API函数:SetClassLong(); 函数原型:DWORD WINAPI S ...
- vue路由信息对象
一个路由信息对象表示当前激活的路由的状态信息,每次成功的导航后都会产生一个新的对象. path字符串,对应当前路由的路径 params对象,包含动态路由参数 query对象,URL查询参数 hash字 ...
- 使用scrapy选择器selector解析获取百度结果
0x00 概述 需要成功安装scrapy,安装方法与本文无关,不在这多说. 0x01 配置settings 由于百度对于user-agent进行验证,所以需要添加. settings.py中找到DEF ...
- 扩展欧几里得(exgcd)与同余详解
exgcd入门以及同余基础 gcd,欧几里得的智慧结晶,信息竞赛的重要算法,数论的...(编不下去了 讲exgcd之前,我们先普及一下同余的性质: 若,那么 若,,且p1,p2互质, 有了这三个式子, ...
- (七)File 文件的操作
一.文件读写模式 1.文件的几种模式: 格式:f=open("文件名","模式",encode="utf-8") #文件的只读模式 f1=o ...
- UE4命令行使用,解释
命令行在外部 从命令行运行编辑项目 1 导航到您的[LauncherInstall][VersionNumber]\Engine\Binaries\Win64 目录中. 2 右键单击上 UE4Edit ...
- pyenv安装及常用命令
1.pyenv安装 #下载安装脚本curl https://pyenv.run | bash #添加环境变量 echo 'export PATH="/root/.pyenv/bin:$PAT ...
- chrome浏览器开发常用快捷键之基础篇-遁地龙卷风
1.标签页和窗口快捷键 打开新的标签页,并跳转到该标签页 Ctrl + t 重新打开最后关闭的标签页,并跳转到该标签页 Ctrl + Shift + t 跳转到下一个打开的标签页 Ctrl + PgD ...
- 开源litemall学习
1参数拼装 https://blog.yeskery.com/articles/345298282 WxWebMvcConfiguration HandlerMethodArgumentResolve ...