YARN结构分析与工作流程
YARN Architecture
Link: http://hadoop.apache.org/docs/r2.7.2/hadoop-yarn/hadoop-yarn-site/YARN.html
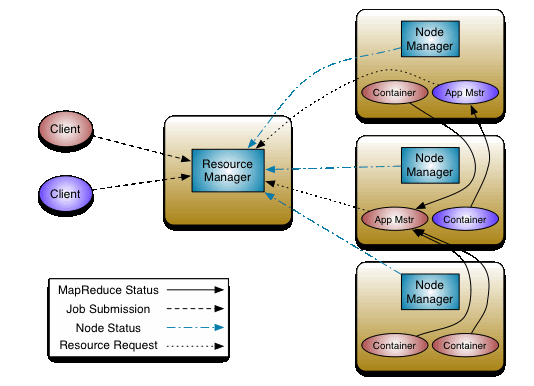
YARN结构图。图中有两个Application,因此有两个ApplicationMaster。4个节点,其中一个节点运行ResourceManager,另外3个节点运行NodeManager。
Yarn的基本思想就是让资源管理器和作业调度/监视器分别成为守护进程。RM和NM构成了数据计算框架。
1、ResourceManager属于集群级别,整个集群只有一个RM,RM负责集群中所有应用的资源管理,当多个作业同时提交时,RM在多个竞争的作业之间权衡优先级并进行资源的仲裁,当资源分配完毕后,RM就不再关心每个应用内部的资源分配,也不关注每个应用的状态。因此RM对于每个应用来说,只进行一次资源分配,大大减轻了RM的负荷,使其扩展性大大增强。
RM主要包含两个部分:
(1)Yarn Scheduler。Scheduler根据不同应用对资源的需求情况(Container, memory, cpu, disk, network etc),为应用分配资源。它并不监控应用的状态,不会重启失败的tasks。它基于应用程序的资源申请来执行资源调度,目前能够调度的资源包括CPU核数和内存。支持的调度器包括:FIFO调度器、Capacity调度器、自适应调度器、自学习调度器、动态优先级调度器等。
The Scheduler has a pluggable policy which is responsible for partitioning the cluster resources among the various queues, applications etc. The current schedulers such as the CapacityScheduler and the FairScheduler would be some examples of plug-ins
(2)ApplicationManager。ApplicationManager负责管理已经提交的应用的集合。在应用提交后,首先检查ApplicationMaster资源请求的合法性,然后确定没有其他已经提交的应用使用了相同的ID。它还负责记录和管理已经结束的应用。
ApplicationManager负责:
①接收提交的作业
②negotiating the first container for executing the application specific ApplicationMaster
③restarting the ApplicationMaster container on failure
2、NodeManager属于节点(机器)级别,每个机器有一个NM,它负责保持与RM的同步,跟踪节点的健康状况,管理各个COntainer的生命周期,监控每个Container的资源使用情况,管理分布式缓存,管理各个Container生成的日志,提供不同Yarn应用可能需要的辅助服务。其中对于Container的管理是NodeManager的核心功能。
每个机器的NM的行为:
(1) 对它的containers负责,启动并监控containers的资源使用情况(cpu, memory, disk, network)。每个container在给定的资源下执行针对于Application的进程(可以是Unix Process或是Linux cgroup)
(2) 向RM发送报告
3、ApplicationMaster属于应用级别,每个应用对应一个AM,不同的计算矿建的AM的实现也是不同的。它负责向RM申请资源,在对应的NodeManager上启动Container来执行任务,并在应用中不断监控这些Container的状态。
每个应用的AM的行为:
(1) 向RM请求资源(与RM的Scheduler协商)
(2) 与containers协作完成任务的执行和监视
YARN结构分析与工作流程的更多相关文章
- Yarn框架和工作流程研究
一.概述 将公司集群升级到Yarn已经有一段时间,自己也对Yarn也研究了一段时间,现在开始记录一下自己在研究Yarn过程中的一些笔记.这篇blog主要主要从大体上说说Yarn的基本架构以及其 ...
- MapReduce与Yarn 的详细工作流程分析
MapReduce详细工作流程之Map阶段 如上图所示 首先有一个200M的待处理文件 切片:在客户端提交之前,根据参数配置,进行任务规划,将文件按128M每块进行切片 提交:提交可以提交到本地工作环 ...
- Scrapy项目结构分析和工作流程
新建的空Scrapy项目: spiders目录: 负责存放继承自scrapy的爬虫类.里面主要是用于分析response并提取返回的item或者是下一个URL信息,每个Spider负责处理特定的网站或 ...
- Spark基本工作流程及YARN cluster模式原理(读书笔记)
Spark基本工作流程及YARN cluster模式原理 转载请注明出处:http://www.cnblogs.com/BYRans/ Spark基本工作流程 相关术语解释 Spark应用程序相关的几 ...
- yarn的基本组成和工作流程
yarn是负责资源管理的,协调各个应用程序的资源使用情况 一.基本组成 yarn主要由以下几个部分组成 1.resourcemanager 主要负责资源的调度和应用程序的管理 (1)调度器 调度器是将 ...
- yarn工作流程
YARN 是 Hadoop 2.0 中的资源管理系统, 它的基本设计思想是将 MRv1 中的 JobTracker拆分成了两个独立的服务 : 一个全局的资源管理器 ResourceManager 和每 ...
- Yarn的工作流程
http://study.163.com/course/courseLearn.htm?courseId=1002887002#/learn/video?lessonId=1003346099& ...
- Android 4.4 Kitkat Phone工作流程浅析(六)__InCallActivity显示更新流程
本文来自http://blog.csdn.net/yihongyuelan 转载请务必注明出处 本文代码以MTK平台Android 4.4为分析对象,与Google原生AOSP有些许差异,请读者知悉. ...
- kafka工作流程| 命令行操作
1. 概述 数据层:结构化数据+非结构化数据+日志信息(大部分为结构化) 传输层:flume(采集日志--->存储性框架(如HDFS.kafka.Hive.Hbase))+sqoop(关系型数 ...
随机推荐
- 封装的一套简单轻量级JS 类库(RapidDevelopmentFramework.JS)
1.最近好久没有更新自己的博客了,一直在考虑自己应该写一些什么.4.2日从苏州回到南京的路上感觉自己的内心些崩溃和失落,我就不多说了? 猛然之间我认为自己需要找一下内心的平衡.决定开发属于自己一套快速 ...
- [PLC]ST语言三:OUT/OUT_T/OUT_C/OUT_C-C32
一:OUT/OUT_T/OUT_C/OUT_C-C32 说明:简单的顺控指令不做其他说明. 控制要求:无 编程梯形图: 结构化编程ST语言: (*OUT(EN,D);*) ...
- Linux学习之常用命令(二)
1.上次介绍了一些常用的系统命令,这次又总结了一些小命令,故分享一下: 网卡地址查询的命令: ifconfig #不同于Windows系统,它的是ifconfig而不是ipconfig ip -a # ...
- 基于Redis实现分布式锁(续)
代码实现: redis实现分布式锁(lock:通过间隔时间段去请求Redis,来实现阻塞占用,一直到获取锁,或者超时. unlock:删除redis中key)
- vue mock(模拟后台数据) 最简单实例(一)——适合小白
开发是前后端分离,不需要等待后台开发.前端自己模拟数据,经本人测试成功. 我们在根目录新建存放数据的json文件,存放我们的数据data.json //data.json{ "status& ...
- spring-framework-reference(5.1.1.RELEASE)中文版——Core部分
前言 最近在学习Spring框架,在学习的同时,借助有道翻译,整理翻译了部分文档,由于尚在学习当中,所以该篇文章将会定时更新,目标在一个月左右时间翻译完全部版本. 虽然大部分内容为翻译,但是其中可能会 ...
- Pod的创建过程
Pod是kubernetes中最小的调度单位,里面包含多个容器,也是真正运行你服务的仓库,同一个pod中容器之间资源共享(IP .网络.cpu.mem.挂载目录等). 1. 准备一个yaml(RC/ ...
- PHP.ini 能不能加载子配置文件 ?
答案是不能,php这个地方用的是另一个方案解决的 编译的时候 用这个参数 --with-config-file-scan-dir指定一个目录 然后在这个目录里面加载ini https://www. ...
- uptime命令详解
基础命令学习目录首页 users个数和窗口数一致 原文链接:https://www.cnblogs.com/ultranms/p/9253217.html uptime 另外还有一个参数 -V(大写) ...
- 手动搭建一个webpack+react笔记
{ "name": "lottery", "version": "1.0.0", "description&q ...