大数据系列之数据仓库Hive原理
Hive系列博文,持续更新~~~
大数据系列之数据仓库Hive原理
大数据系列之数据仓库Hive安装
大数据系列之数据仓库Hive中分区Partition如何使用
大数据系列之数据仓库Hive命令使用及JDBC连接
Hive的工作原理简单来说就是一个查询引擎
先来一张Hive的架构图:
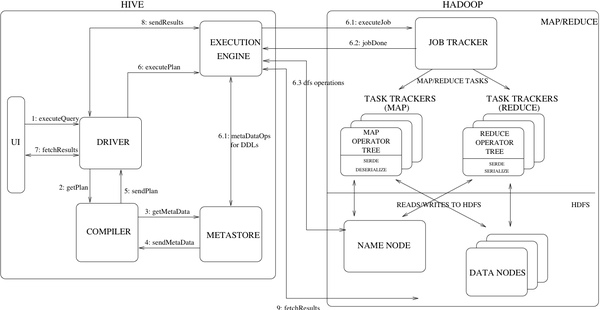
Hive的工作原理如下:
接收到一个sql,后面做的事情包括:
1.词法分析/语法分析
使用antlr将SQL语句解析成抽象语法树-AST
2.语义分析
从Megastore获取模式信息,验证SQL语句中队表名,列名,以及数据类型的检查和隐式转换,以及Hive提供的函数和用户自定义的函数(UDF/UAF)
3.逻辑计划生产
生成逻辑计划-算子树
4.逻辑计划优化
对算子树进行优化,包括列剪枝,分区剪枝,谓词下推等
5.物理计划生成
将逻辑计划生产包含由MapReduce任务组成的DAG的物理计划
6.物理计划执行
将DAG发送到Hadoop集群进行执行
7.将查询结果返回
流程如下图:
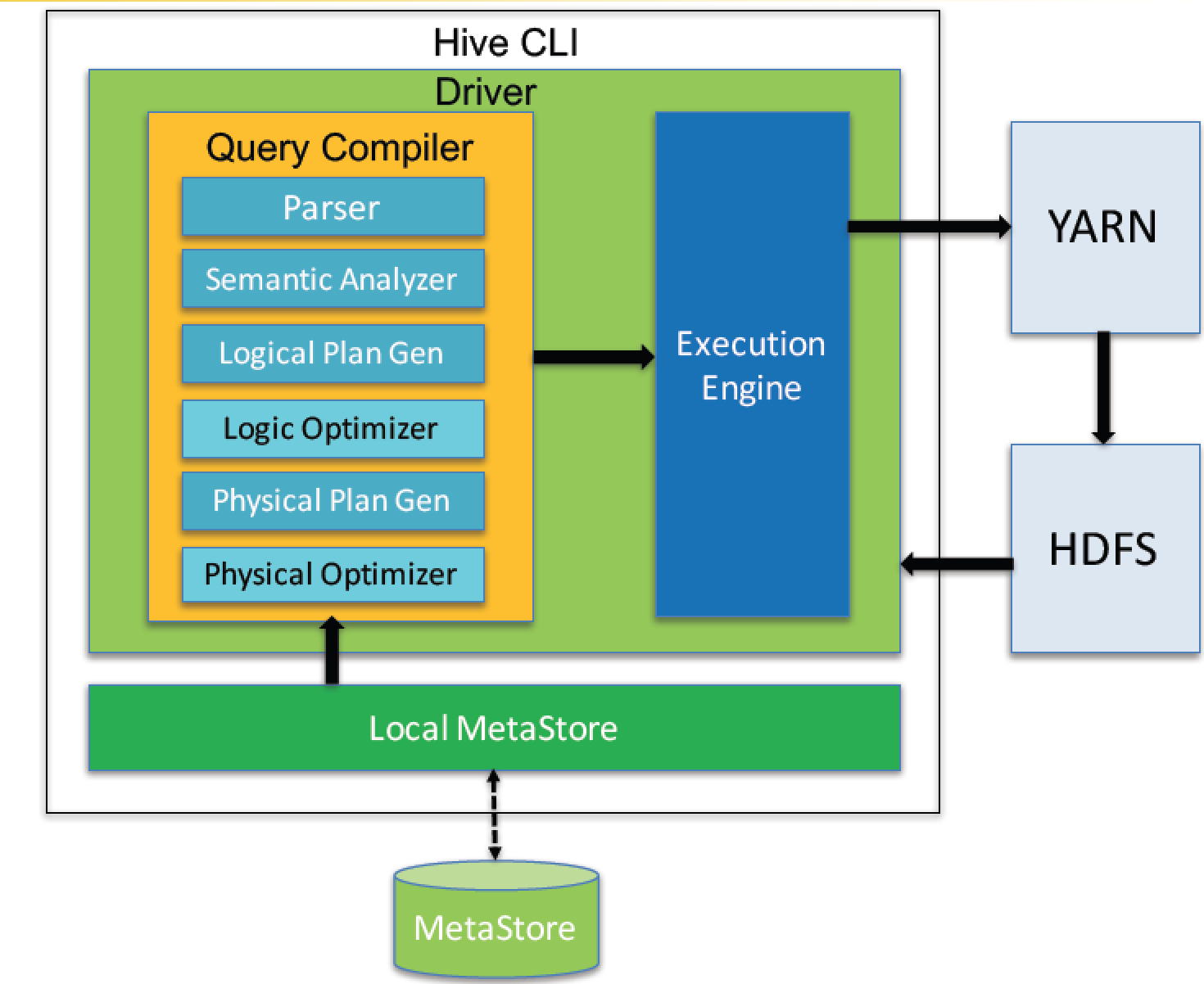
Query Compiler
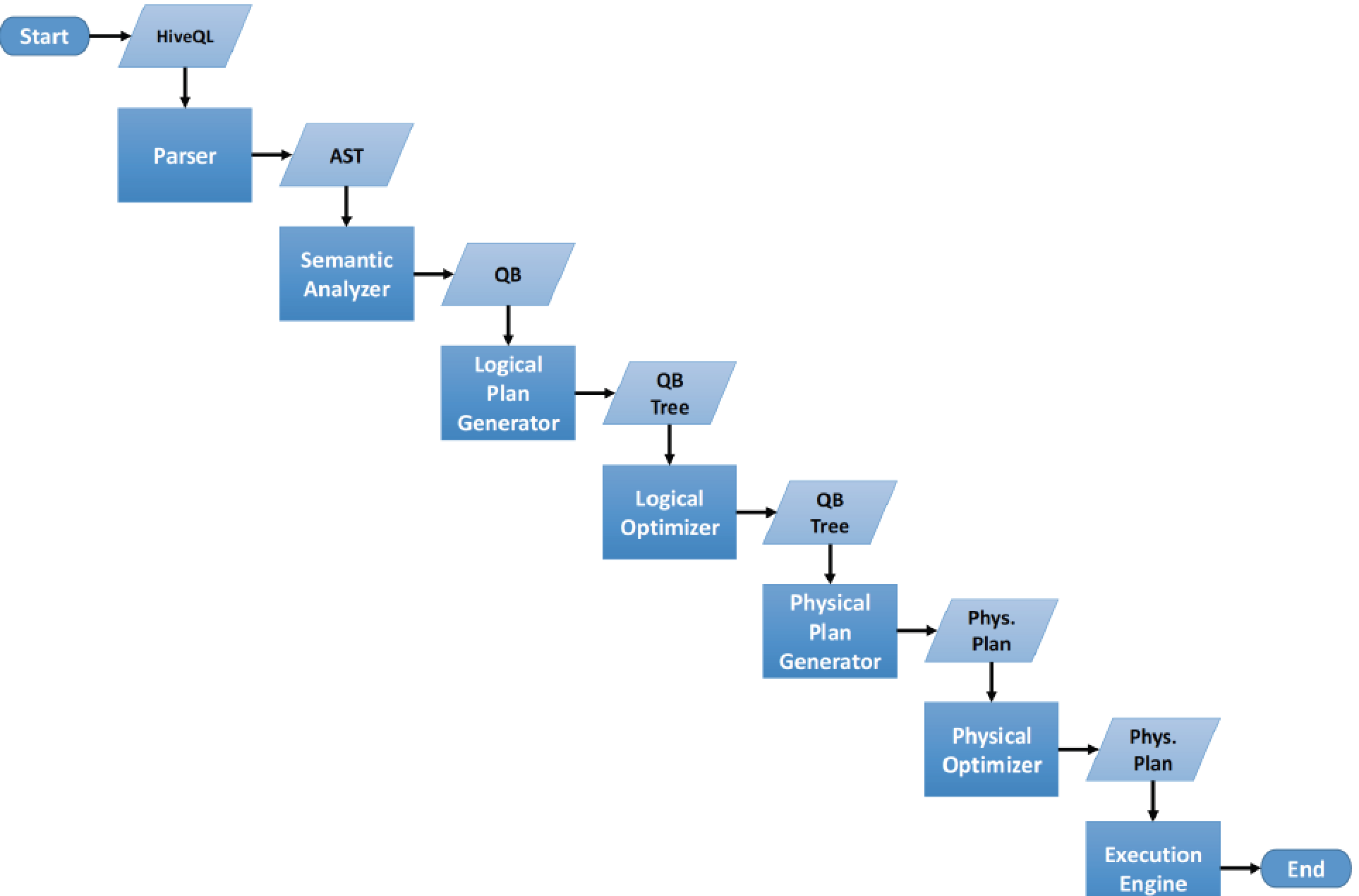
新版本的Hive也支持使用Tez或Spark作为执行引擎。
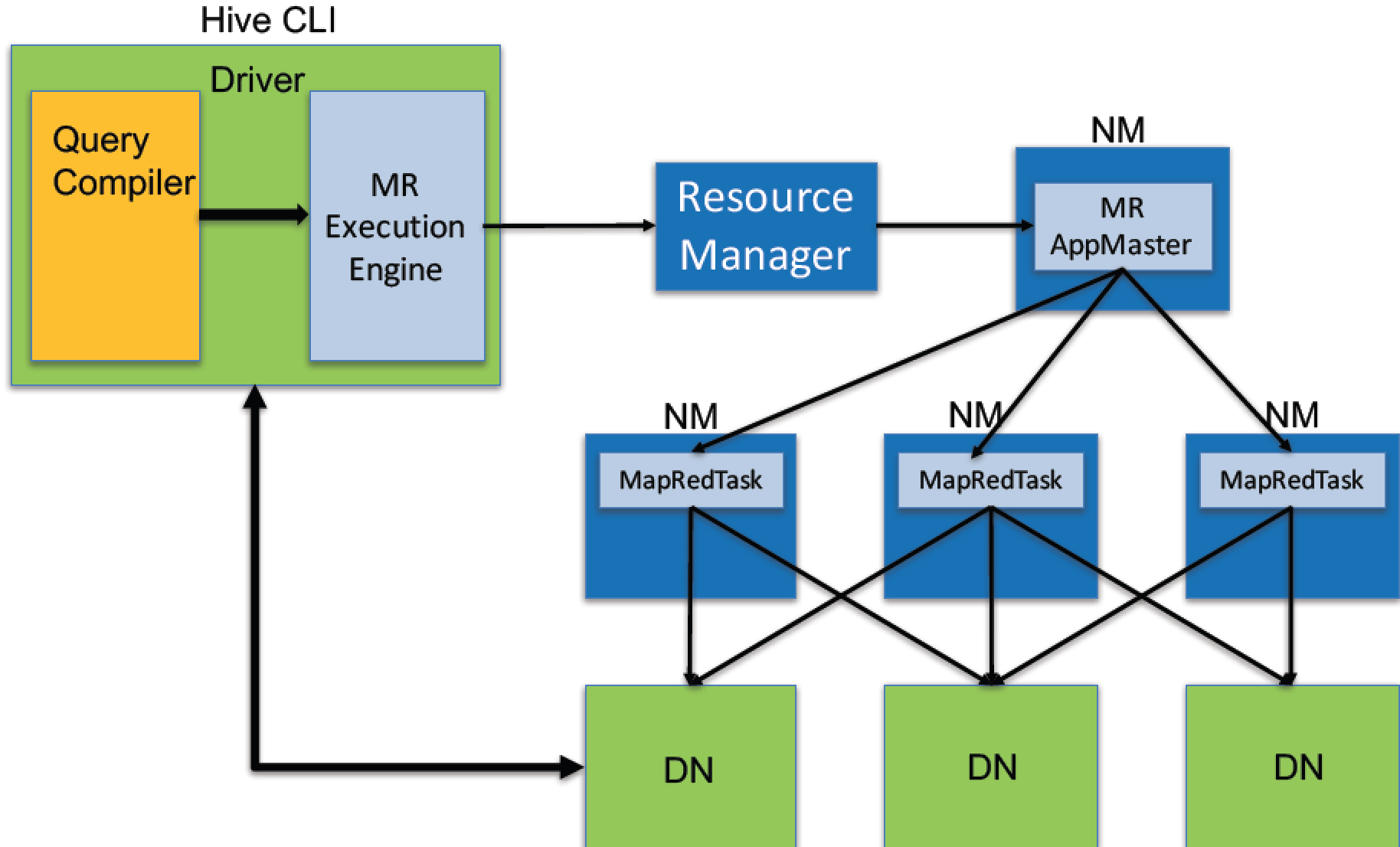

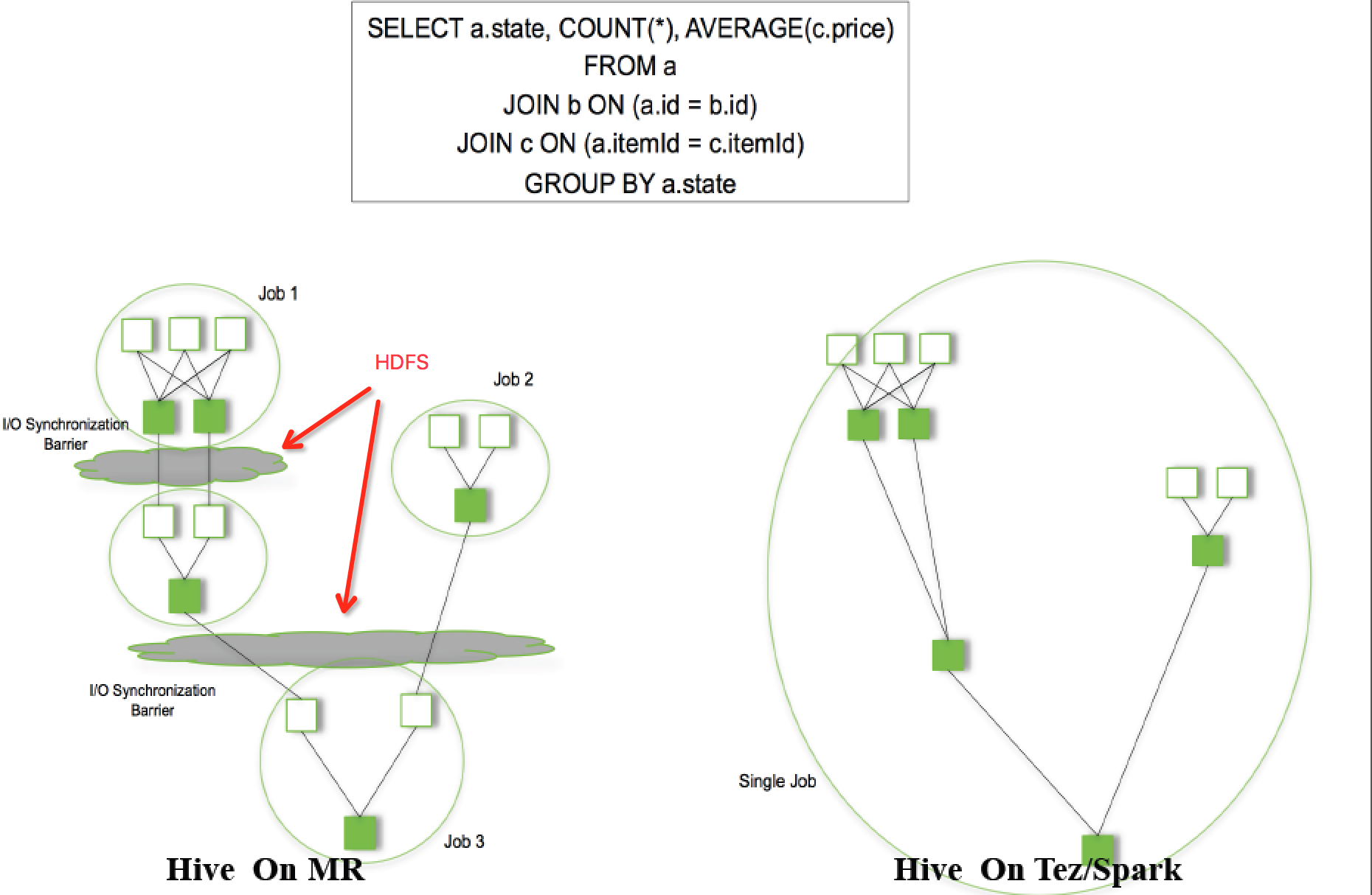
物理计划可以通过hive的Explain命令输出
例如:
: jdbc:hive2://master:10000/dbmfz> explain select count(*) from record_dimension;
+------------------------------------------------------------------------------------------------------+--+
| Explain |
+------------------------------------------------------------------------------------------------------+--+
| STAGE DEPENDENCIES: |
| Stage- is a root stage |
| Stage- depends on stages: Stage- |
| |
| STAGE PLANS: |
| Stage: Stage- |
| Map Reduce |
| Map Operator Tree: |
| TableScan |
| alias: record_dimension |
| Statistics: Num rows: Data size: Basic stats: COMPLETE Column stats: COMPLETE |
| Select Operator |
| Statistics: Num rows: Data size: Basic stats: COMPLETE Column stats: COMPLETE |
| Group By Operator |
| aggregations: count() |
| mode: hash |
| outputColumnNames: _col0 |
| Statistics: Num rows: Data size: Basic stats: COMPLETE Column stats: COMPLETE |
| Reduce Output Operator |
| sort order: |
| Statistics: Num rows: Data size: Basic stats: COMPLETE Column stats: COMPLETE |
| value expressions: _col0 (type: bigint) |
| Reduce Operator Tree: |
| Group By Operator |
| aggregations: count(VALUE._col0) |
| mode: mergepartial |
| outputColumnNames: _col0 |
| Statistics: Num rows: Data size: Basic stats: COMPLETE Column stats: COMPLETE |
| File Output Operator |
| compressed: false |
| Statistics: Num rows: Data size: Basic stats: COMPLETE Column stats: COMPLETE |
| table: |
| input format: org.apache.hadoop.mapred.SequenceFileInputFormat |
| output format: org.apache.hadoop.hive.ql.io.HiveSequenceFileOutputFormat |
| serde: org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe |
| |
| Stage: Stage- |
| Fetch Operator |
| limit: - |
| Processor Tree: |
| ListSink |
| |
+------------------------------------------------------------------------------------------------------+--+
rows selected (0.844 seconds)
除了DML,Hive也提供DDL来创建表的schema。
Hive数据存储支持HDFS的一些文件格式,比如CSV,Sequence File,Avro,RC File,ORC,Parquet。也支持访问HBase。
Hive提供一个CLI工具,类似Oracle的sqlplus,可以交互式执行sql,提供JDBC驱动作为Java的API。
转载请注明出处:
作者:mengfanzhu
原文链接:http://www.cnblogs.com/cnmenglang/p/6684615.html
大数据系列之数据仓库Hive原理的更多相关文章
- 大数据系列之数据仓库Hive安装
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据系列之数据仓库Hive命令使用及JDBC连接
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 大数据系列之数据仓库Hive中分区Partition如何使用
Hive系列博文,持续更新~~~ 大数据系列之数据仓库Hive原理 大数据系列之数据仓库Hive安装 大数据系列之数据仓库Hive中分区Partition如何使用 大数据系列之数据仓库Hive命令使用 ...
- 【大数据系列】apache hive 官方文档翻译
GettingStarted 开始 Created by Confluence Administrator, last modified by Lefty Leverenz on Jun 15, 20 ...
- 大数据系列(3)——Hadoop集群完全分布式坏境搭建
前言 上一篇我们讲解了Hadoop单节点的安装,并且已经通过VMware安装了一台CentOS 6.8的Linux系统,咱们本篇的目标就是要配置一个真正的完全分布式的Hadoop集群,闲言少叙,进入本 ...
- 大数据系列之并行计算引擎Spark介绍
相关博文:大数据系列之并行计算引擎Spark部署及应用 Spark: Apache Spark 是专为大规模数据处理而设计的快速通用的计算引擎. Spark是UC Berkeley AMP lab ( ...
- 大数据系列之分布式计算批处理引擎MapReduce实践
关于MR的工作原理不做过多叙述,本文将对MapReduce的实例WordCount(单词计数程序)做实践,从而理解MapReduce的工作机制. WordCount: 1.应用场景,在大量文件中存储了 ...
- 大数据系列(5)——Hadoop集群MYSQL的安装
前言 有一段时间没写文章了,最近事情挺多的,现在咱们回归正题,经过前面四篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,相关的两款软件VSFTP和SecureCRT也已经正常安装了. ...
- 大数据系列(4)——Hadoop集群VSFTP和SecureCRT安装配置
前言 经过前三篇文章的介绍,已经通过VMware安装了Hadoop的集群环境,当然,我相信安装的过程肯定遇到或多或少的问题,这些都需要自己解决,解决的过程就是学习的过程,本篇的来介绍几个Hadoop环 ...
随机推荐
- MT【130】Heilbronn问题
(清华THUSSAT,多选题) 平面上 4 个不同点 \(P_1,P_2,P_3,P_4\),在每两个点之间连接线段得到 6 条线段. 记 \[L=\max_{1\leq i<j\leq 4}| ...
- linux中awk工具的使用
awk是一个非常好用的数据处理工具.相较于sed常常一整行处理,awk则比较倾向于一行当中分成数个“字段”处理,awk处理方式如下: $ awk '条件类型1{动作1} 条件类型2{动作2} ...' ...
- 公钥与私钥对HTTPS的理解(数字证书的需要)
本文转自某大牛链接 文中首先解释了加密解密的一些基础知识和概念,然后通过一个加密通信过程的例子说明了加密算法的作用,以及数字证书的出现所起的作用.接着对数字证书做一个详细的解释,并讨论一下window ...
- c++ 顶层const与底层const
底层const是代表对象本身是一个常量(不可改变): 顶层const是代表指针的值是一个常量,而指针的值(即对象的地址)的内容可以改变(指向的不可改变): #include <iost ...
- .Net并行编程系列之三:创建带时间限制(Timeout)的异步任务并取得异步任务的结果
尝试创建基于MVVM三层架构的异步任务: 场景:View层触发ViewModel层的动作请求,ViewModel层异步的从Model层查询数据,当数据返回或者请求超时时正确更新ViewModel层数据 ...
- go语言从零学起(三) -- chat实现的思考
要通过go实现一个应用场景: 1 建立一个websocket服务 2 维护在线用户的链接 3 推送消息和接受用户的操作 列出需求,很显然的想到了chat模型.于是研究了revel框架提供的sample ...
- T48566 【zzy】yyy点餐
T48566 [zzy]yyy点餐 题目描述 yyy去麦肯士吃垃圾食品. 麦肯士有n种单点餐品(汉堡薯条鸡翅之类的).每次选择一种或者以上的餐点,且每种餐点不多于一个的话,可以认为是购买套餐.购买一个 ...
- 给Java新手的一些建议——Java知识点归纳(Java基础部分)
原文出处:CSDN邓帅 写这篇文章的目的是想总结一下自己这么多年来使用java的一些心得体会,主要是和一些Java基础知识点相关的,所以也希望能分享给刚刚入门的Java程序员和打算入Java开发这个行 ...
- python中的文件操作(2)
a+,w+,r+的特点: r+:r+模式允许读和写,当对文件句柄只进行写操作时,tell(),seek()为写操作的‘指针’(也就是写到seek()处). 当只进行读操作时,tell(),seek() ...
- RabbitMQ基础篇
介绍 RabbitMQ 是一个消息中间件:它接收并转发消息.您可以把它想象为一个邮局:当您把需要寄出的邮件投递到邮箱,邮差最终会把邮件送给您的收件人.在这个比喻中,RabbitMQ 就是一个邮箱,也可 ...