机器学习之路:python 多项式特征生成PolynomialFeatures 欠拟合与过拟合
分享一下 线性回归中 欠拟合 和 过拟合 是怎么回事~
为了解决欠拟合的情 经常要提高线性的次数建立模型拟合曲线, 次数过高会导致过拟合,次数不够会欠拟合。
再建立高次函数时候,要利用多项式特征生成器 生成训练数据。
下面把整个流程展示一下
模拟了一个预测蛋糕价格的从欠拟合到过拟合的过程 git: https://github.com/linyi0604/MachineLearning 在做线性回归预测时候,为了提高模型的泛化能力,经常采用多次线性函数建立模型 f = k*x + b 一次函数
f = a*x^2 + b*x + w 二次函数
f = a*x^3 + b*x^2 + c*x + w 三次函数
。。。 泛化:
对未训练过的数据样本进行预测。 欠拟合:
由于对训练样本的拟合程度不够,导致模型的泛化能力不足。 过拟合:
训练样本拟合非常好,并且学习到了不希望学习到的特征,导致模型的泛化能力不足。 在建立超过一次函数的线性回归模型之前,要对默认特征生成多项式特征再输入给模型
poly2 = PolynomialFeatures(degree=2) # 2次多项式特征生成器
x_train_poly2 = poly2.fit_transform(x_train)
下面模拟 根据蛋糕的直径大小 预测蛋糕价格
from sklearn.linear_model import LinearRegression
import numpy as np
import matplotlib.pyplot as plt '''
在做线性回归预测时候,
为了提高模型的泛化能力,经常采用多次线性函数建立模型 f = k*x + b 一次函数
f = a*x^2 + b*x + w 二次函数
f = a*x^3 + b*x^2 + c*x + w 三次函数
。。。 泛化:
对未训练过的数据样本进行预测。 欠拟合:
由于对训练样本的拟合程度不够,导致模型的泛化能力不足。 过拟合:
训练样本拟合非常好,并且学习到了不希望学习到的特征,导致模型的泛化能力不足。 在建立超过一次函数的线性回归模型之前,要对默认特征生成多项式特征再输入给模型 下面模拟 根据蛋糕的直径大小 预测蛋糕价格 ''' # 样本的训练数据,特征和目标值
x_train = [[6], [8], [10], [14], [18]]
y_train = [[7], [9], [13], [17.5], [18]] # 一次线性回归的学习与预测
# 线性回归模型 学习
regressor = LinearRegression()
regressor.fit(x_train, y_train)
# 画出一次线性回归的拟合曲线
xx = np.linspace(0, 25, 100) # 0到16均匀采集100个点做x轴
xx = xx.reshape(xx.shape[0], 1)
yy = regressor.predict(xx) # 计算每个点对应的y
plt.scatter(x_train, y_train) # 画出训练数据的点
plt1, = plt.plot(xx, yy, label="degree=1")
plt.axis([0, 25, 0, 25])
plt.xlabel("Diameter")
plt.ylabel("Price")
plt.legend(handles=[plt1])
plt.show()
一次线性函数拟合曲线的结果,是欠拟合的情况:
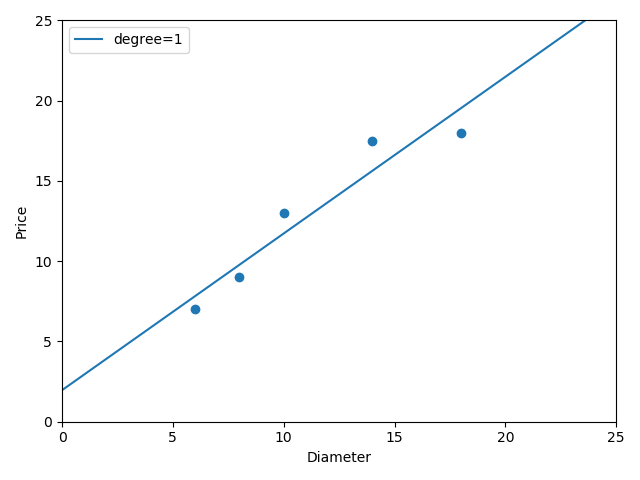
下面进行建立2次线性回归模型进行预测:
# 2次线性回归进行预测
poly2 = PolynomialFeatures(degree=2) # 2次多项式特征生成器
x_train_poly2 = poly2.fit_transform(x_train)
# 建立模型预测
regressor_poly2 = LinearRegression()
regressor_poly2.fit(x_train_poly2, y_train)
# 画出2次线性回归的图
xx_poly2 = poly2.transform(xx)
yy_poly2 = regressor_poly2.predict(xx_poly2)
plt.scatter(x_train, y_train)
plt1, = plt.plot(xx, yy, label="Degree1")
plt2, = plt.plot(xx, yy_poly2, label="Degree2")
plt.axis([0, 25, 0, 25])
plt.xlabel("Diameter")
plt.ylabel("Price")
plt.legend(handles=[plt1, plt2])
plt.show()
# 输出二次回归模型的预测样本评分
print("二次线性模型在训练数据上得分:", regressor_poly2.score(x_train_poly2, y_train)) # 0.9816421639597427
二次线性回归模型拟合的曲线:
拟合程度明显比1次线性拟合的要好
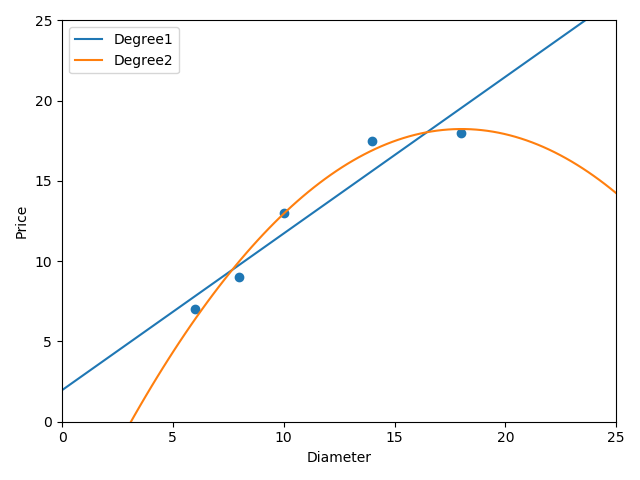
下面进行4次线性回归模型:
# 进行四次线性回归模型拟合
poly4 = PolynomialFeatures(degree=4) # 4次多项式特征生成器
x_train_poly4 = poly4.fit_transform(x_train)
# 建立模型预测
regressor_poly4 = LinearRegression()
regressor_poly4.fit(x_train_poly4, y_train)
# 画出2次线性回归的图
xx_poly4 = poly4.transform(xx)
yy_poly4 = regressor_poly4.predict(xx_poly4)
plt.scatter(x_train, y_train)
plt1, = plt.plot(xx, yy, label="Degree1")
plt2, = plt.plot(xx, yy_poly2, label="Degree2")
plt4, = plt.plot(xx, yy_poly4, label="Degree2")
plt.axis([0, 25, 0, 25])
plt.xlabel("Diameter")
plt.ylabel("Price")
plt.legend(handles=[plt1, plt2, plt4])
plt.show()
# 输出二次回归模型的预测样本评分
print("四次线性训练数据上得分:", regressor_poly4.score(x_train_poly4, y_train)) # 1.0
四次线性模型预测准确率为百分之百, 但是看一下拟合曲线,明显存在不合逻辑的预测曲线,
在样本点之外的情况,可能预测的非常不准确,这种情况为过拟合
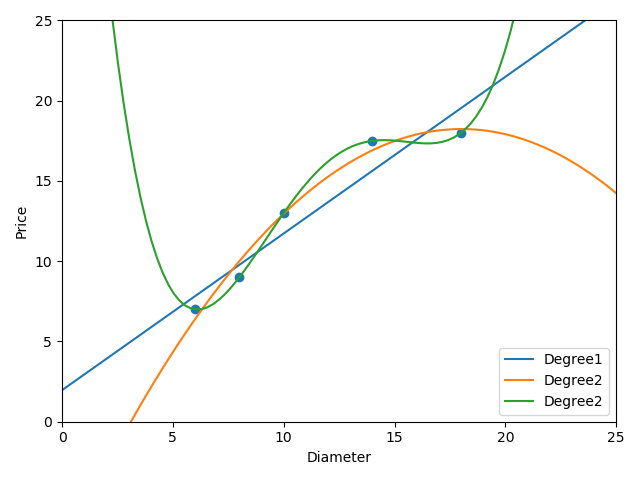
之前我们一直在展示在训练集合上获得的模型评分,次数越高的模型,训练拟合越好。
下面查看一组测试数据进行预测的得分情况:
# 准备测试数据
x_test = [[6], [8], [11], [16]]
y_test = [[8], [12], [15], [18]]
print("一次线性模型在测试集合上得分:", regressor.score(x_test, y_test)) # 0.809726797707665
x_test_poly2 = poly2.transform(x_test)
print("二次线性模型在测试集合上得分:", regressor_poly2.score(x_test_poly2, y_test)) # 0.8675443656345054
x_test_poly4 = poly4.transform(x_test)
print("四次线性模型在测试集合上得分:", regressor_poly4.score(x_test_poly4, y_test)) # 0.8095880795746723
会发现,二次模型在预测集合上表现最好,四次模型表现反而不好!
这就是由于对训练数据学习的太过分,学习到了不重要的东西,反而导致预测不准确。
机器学习之路:python 多项式特征生成PolynomialFeatures 欠拟合与过拟合的更多相关文章
- 机器学习之路: python k近邻分类器 KNeighborsClassifier 鸢尾花分类预测
使用python语言 学习k近邻分类器的api 欢迎来到我的git查看源代码: https://github.com/linyi0604/MachineLearning from sklearn.da ...
- 机器学习之路--Python
常用数据结构 1.list 列表 有序集合 classmates = ['Michael', 'Bob', 'Tracy'] len(classmates) classmates[0] len(cla ...
- 机器学习之路: python 回归树 DecisionTreeRegressor 预测波士顿房价
python3 学习api的使用 git: https://github.com/linyi0604/MachineLearning 代码: from sklearn.datasets import ...
- 机器学习之路: python 线性回归LinearRegression, 随机参数回归SGDRegressor 预测波士顿房价
python3学习使用api 线性回归,和 随机参数回归 git: https://github.com/linyi0604/MachineLearning from sklearn.datasets ...
- 机器学习之路: python 决策树分类DecisionTreeClassifier 预测泰坦尼克号乘客是否幸存
使用python3 学习了决策树分类器的api 涉及到 特征的提取,数据类型保留,分类类型抽取出来新的类型 需要网上下载数据集,我把他们下载到了本地, 可以到我的git下载代码和数据集: https: ...
- 机器学习基础:(Python)训练集测试集分割与交叉验证
在上一篇关于Python中的线性回归的文章之后,我想再写一篇关于训练测试分割和交叉验证的文章.在数据科学和数据分析领域中,这两个概念经常被用作防止或最小化过度拟合的工具.我会解释当使用统计模型时,通常 ...
- 一个完整的机器学习项目在Python中演练(三)
大家往往会选择一本数据科学相关书籍或者完成一门在线课程来学习和掌握机器学习.但是,实际情况往往是,学完之后反而并不清楚这些技术怎样才能被用在实际的项目流程中.就像你的脑海中已经有了一块块"拼 ...
- 机器学习算法与Python实践之(四)支持向量机(SVM)实现
机器学习算法与Python实践之(四)支持向量机(SVM)实现 机器学习算法与Python实践之(四)支持向量机(SVM)实现 zouxy09@qq.com http://blog.csdn.net/ ...
- 机器学习算法与Python实践之(三)支持向量机(SVM)进阶
机器学习算法与Python实践之(三)支持向量机(SVM)进阶 机器学习算法与Python实践之(三)支持向量机(SVM)进阶 zouxy09@qq.com http://blog.csdn.net/ ...
随机推荐
- 谈谈VMware虚拟机中的网络问题
前言:用了好几年的虚拟机,多多少少都会遇到那么一些网络问题,在这里总结一下这么几年在虚拟机中遇到的一些网络问题(主要针对linux)...... 一.VMware相关基础知识 1.bridged(桥接 ...
- InnoDB 引擎独立表空间
InnoDB 引擎独立表空间 使用过MySQL的同学,刚开始接触最多的莫过于MyISAM表引擎了,这种引擎的数据库会分别创建三个文件:表结构.表索引.表数据空间.我们可以将某个数据库目录直接迁移到 ...
- 10 Useeful Tips for Writing Effective Bash Scripts in Linux
1.Always Use Comments in Scripts2.Make a Scripts exit When Fails Sometimes bash may continue to e ...
- MVC中检测到有潜在危险的 Request.Form 值
在做mvc项目时,当使用xhedit or.ueditor编辑器时,点击提交时,编辑器中的内容会带有html标签提交给服务器,这时就是会报错,出现如下内容: “/”应用程序中的服务器错误. 从客户端( ...
- Spiral Matrix I & II
Spiral Matrix I Given an integer n, generate a square matrix filled with elements from 1 to n^2 in s ...
- linux中断申请之request_threaded_irq 【转】
转自:http://blog.chinaunix.net/xmlrpc.php?r=blog/article&uid=21977330&id=3755609 在linux里,中断处理分 ...
- 学习网站总结->
慕课大巴网:这是一个学习各类技术视频的网站 慕课大巴网点我-> 吾爱破解: 这是一个破解各类软件的网站 吾爱破解点我-> 鸠摩搜书:可以搜一些免费的书,我喜欢的都能搜到 鸠摩搜书点我-&g ...
- 十三、springboot集成定时任务(Scheduling Tasks)
定时任务(Scheduling Tasks) 在springboot创建定时任务比较简单,只需2步: 1.在程序的入口加上@EnableScheduling注解. 2.在定时方法上加@Schedule ...
- Python字符串(Str)详解
字符串是 Python 中最常用的数据类型.我们可以使用引号('或")来创建字符串. 创建字符串很简单,只要为变量分配一个值即可 字符串的格式 b = "hello itcast. ...
- Gitflow工作流
什么是Gitflow工作流 Gitflow工作流定义了一个围绕项目发布的严格分支模型.虽然比功能分支工作流复杂几分,但提供了用于一个健壮的用于管理大型项目的框架. Gitflow工作流没有用超出功能分 ...