windows下在idea用maven导入spark2.3.1源码并编译并运行示例
一、前提
1.配置好maven:intellij idea maven配置及maven项目创建
2.下载好spark源码:
二、导入源码:
1.将下载的源码包spark-2.3.1.tgz解压(E:\spark-2.3.1.tgz\spark-2.3.1.tar)至E:\spark-2.3.1-src
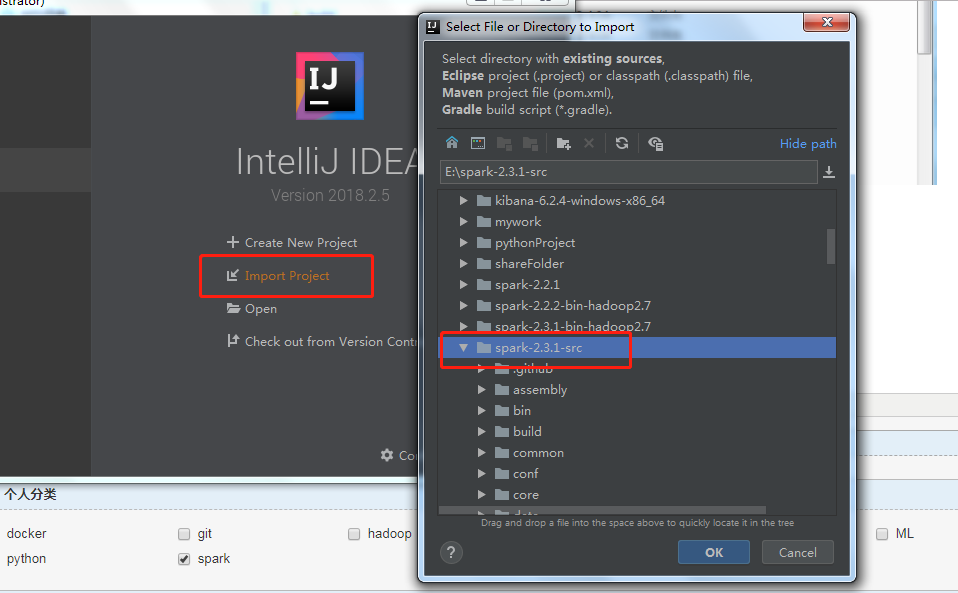
2.在ideal导入源码:
a.选择解压的源代码文件夹
b.使用maven导入工程
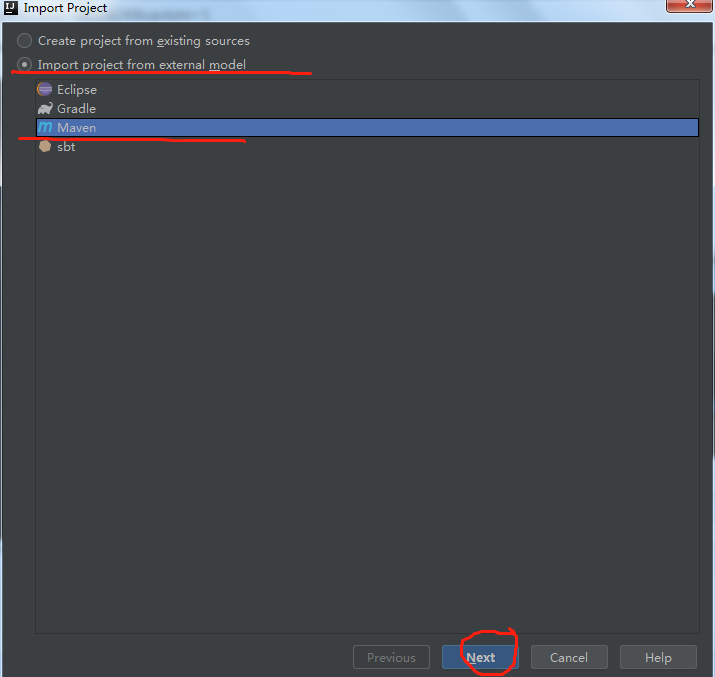
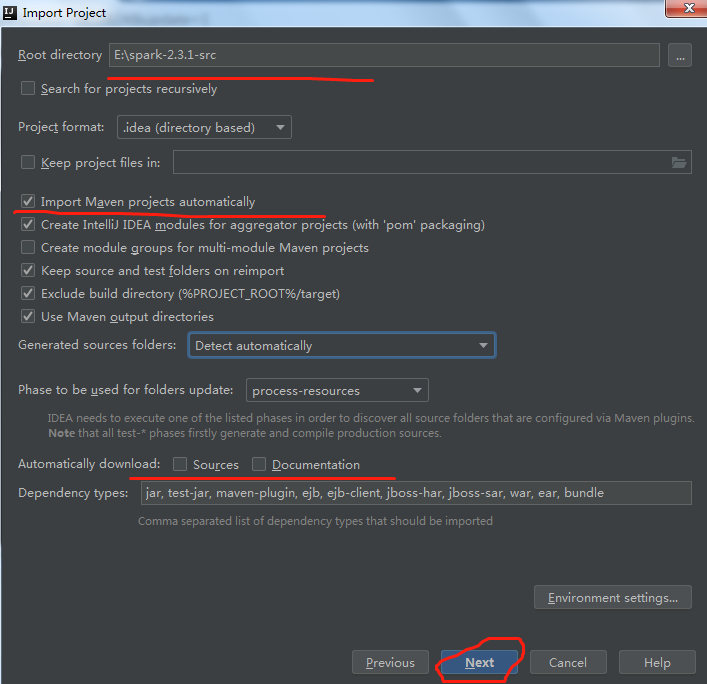
c.选择对应组件的版本
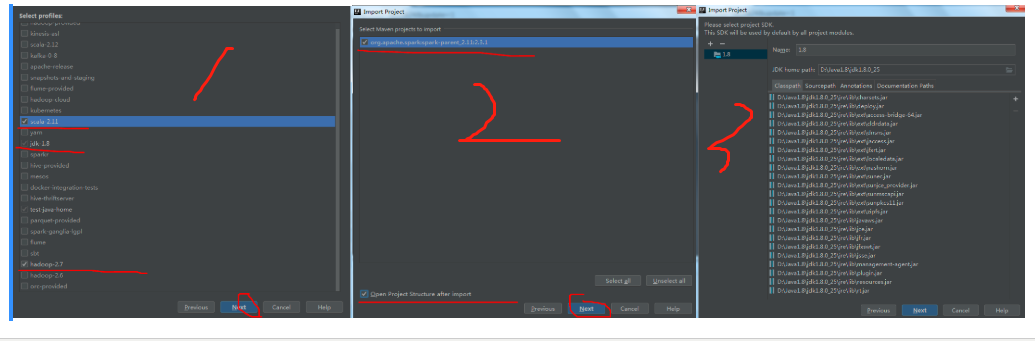
然后点击下一步:
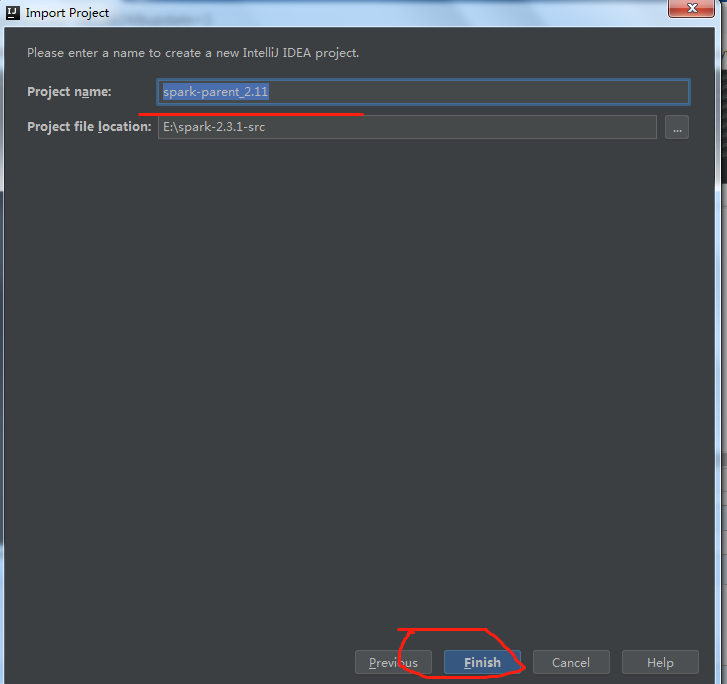 点击finish后,等待maven下载相关的依赖包,之后工程界面如下:
点击finish后,等待maven下载相关的依赖包,之后工程界面如下:
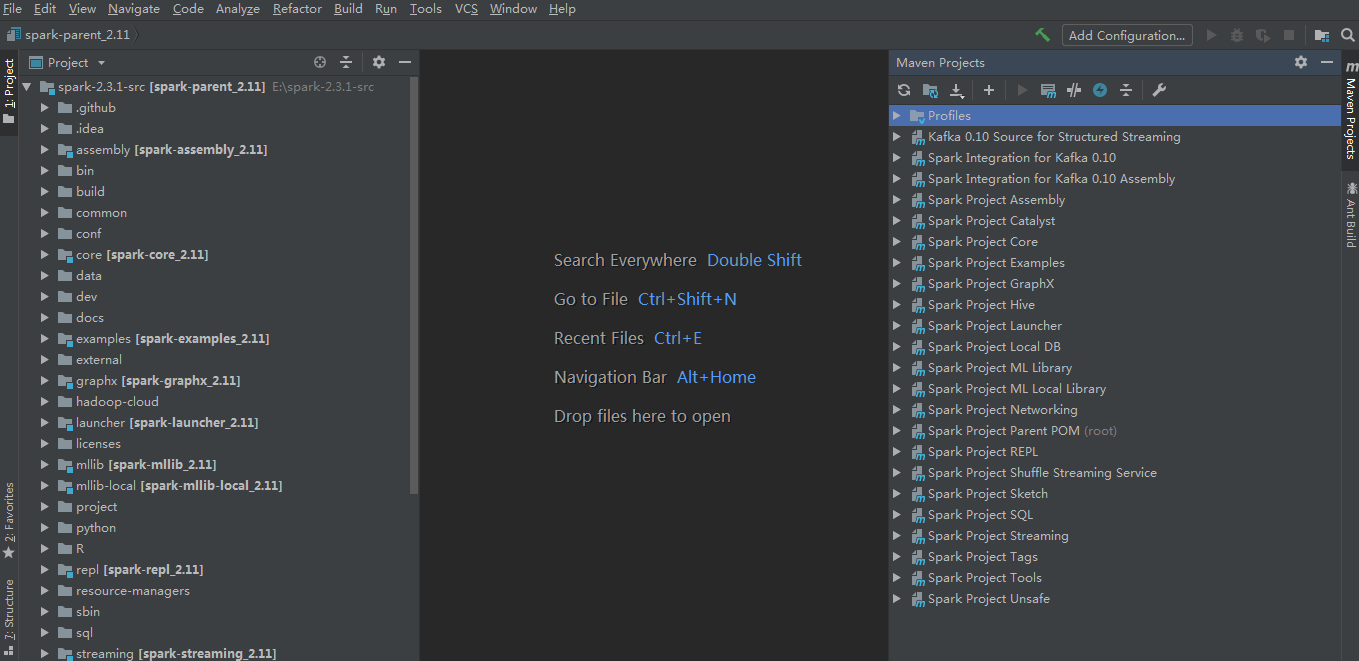
修改E:\spark-2.3.1-src\pom.xml文件,以避免这俩变量未定义,导致最终在E:\spark-2.3.1-src\assembly\target\scala-2.11\没有jar包

开始使用maven对spark源码进行编译打包成jar:
编译结果如下:
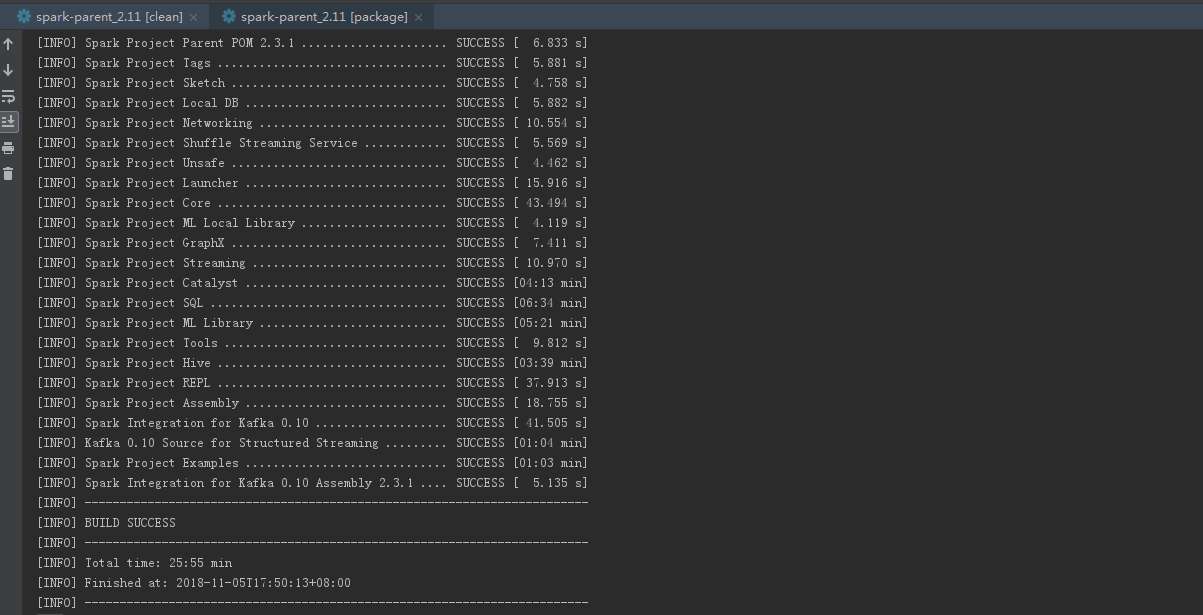
会在每个模块的target目录生成对应的jar,并在assembly\target\scala-2.11\jar下生成spark需要的全部jar包

解决办法如下,在E:\spark-2.3.1-src\sql\catalyst\target目录下会出现antlr4相关的类:


三.运行spark自带示例(前提:需要配置spark在windows下的运行环境,参见win7下配置spark)
1.SparkPi
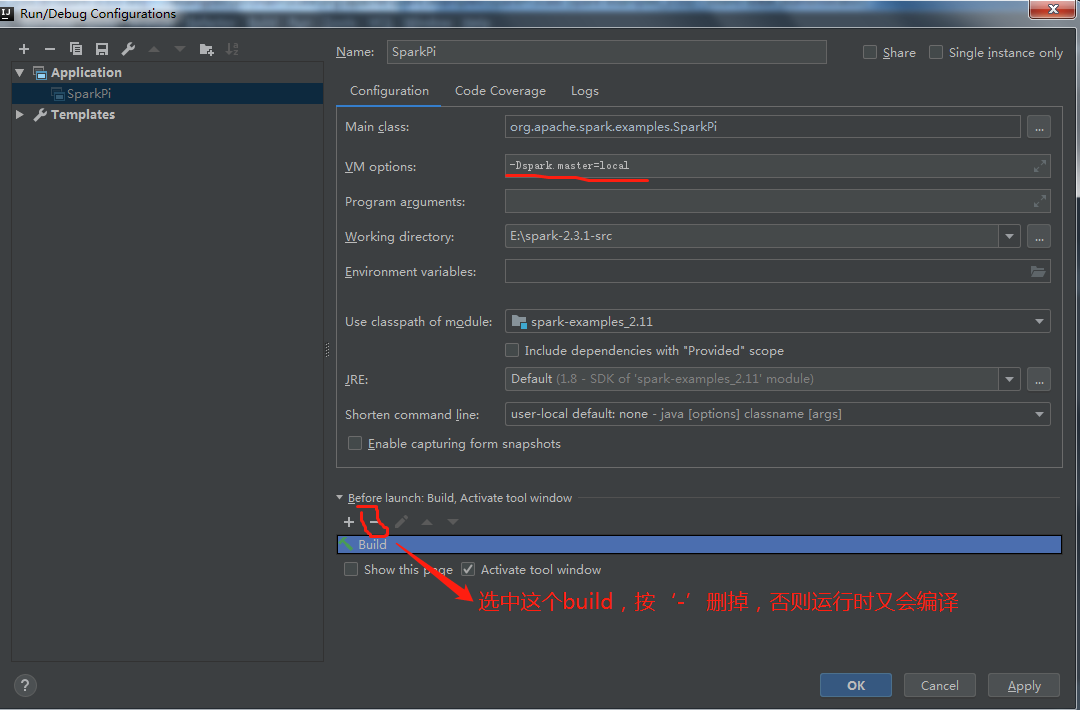
报错如下:
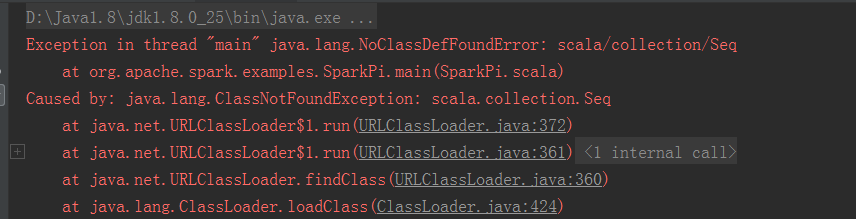
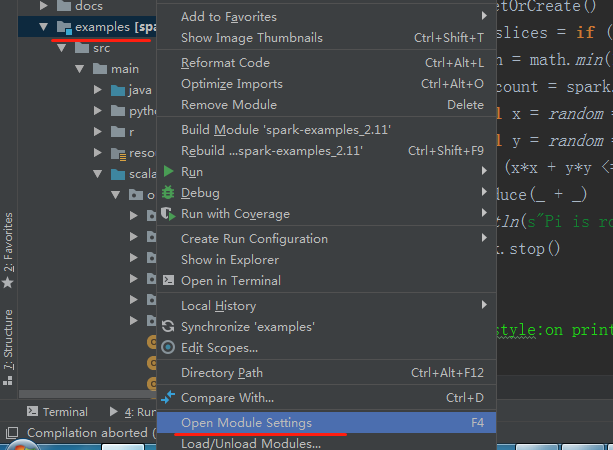
刚才生成的spark相关的依赖包没找到,解决办法如下:


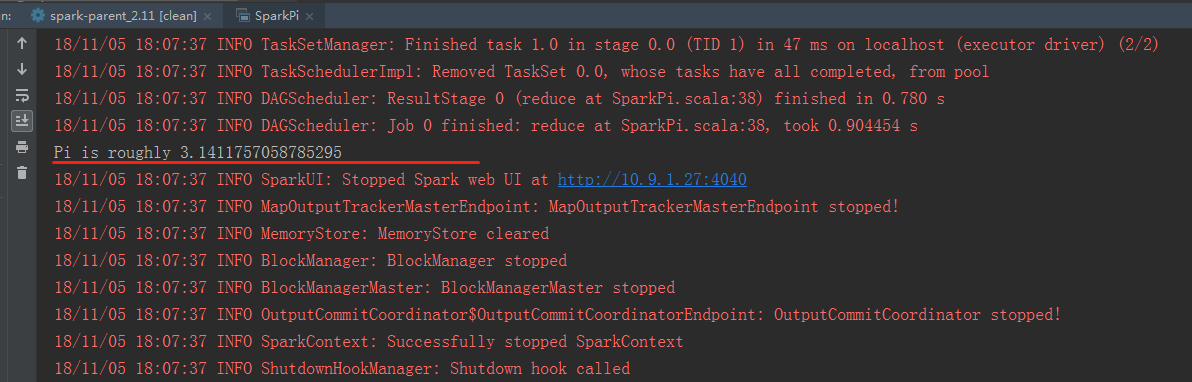
再次运行,结果如下:
2.通过org.apache.spark.deploy.SparkSubmit提交任务并运行(前提是像运行SparkPi一样,把assembly\target\jars的依赖加进该模块,方法同上):
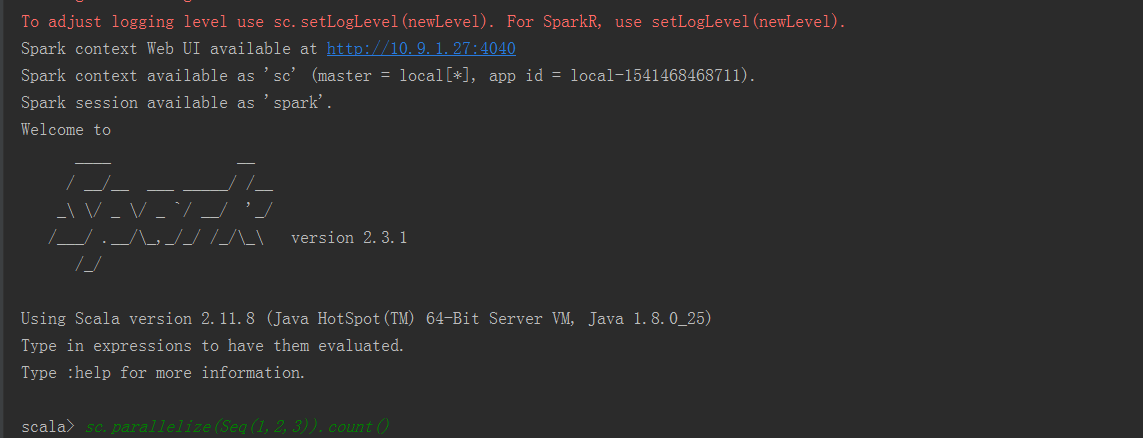
2.1 org.apache.spark.repl.Main
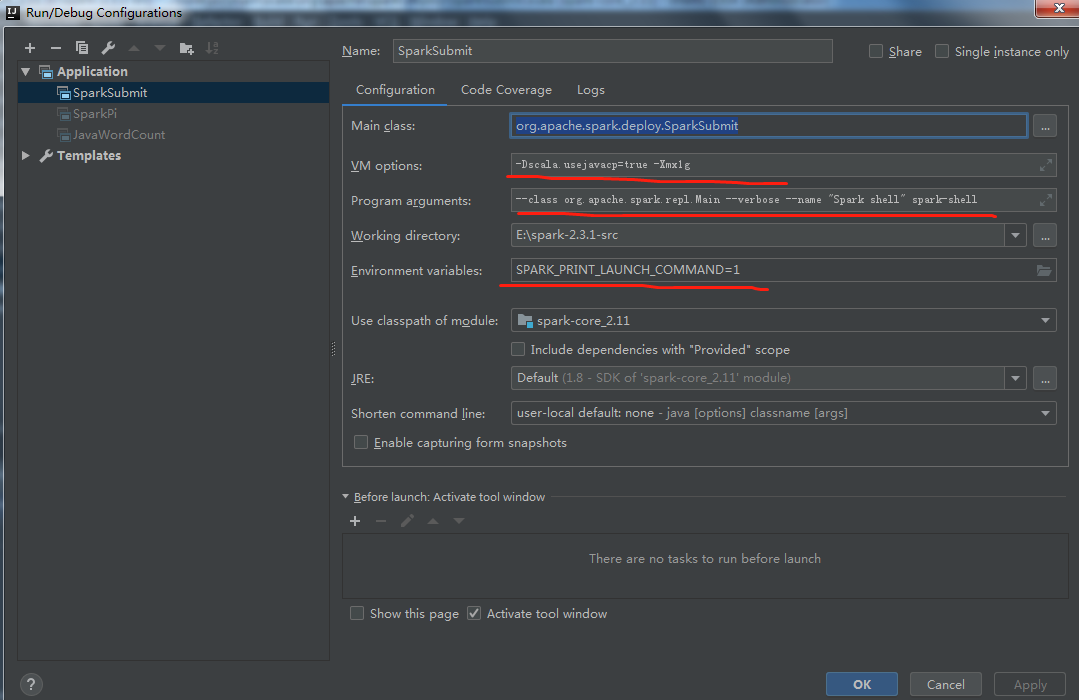
结果:
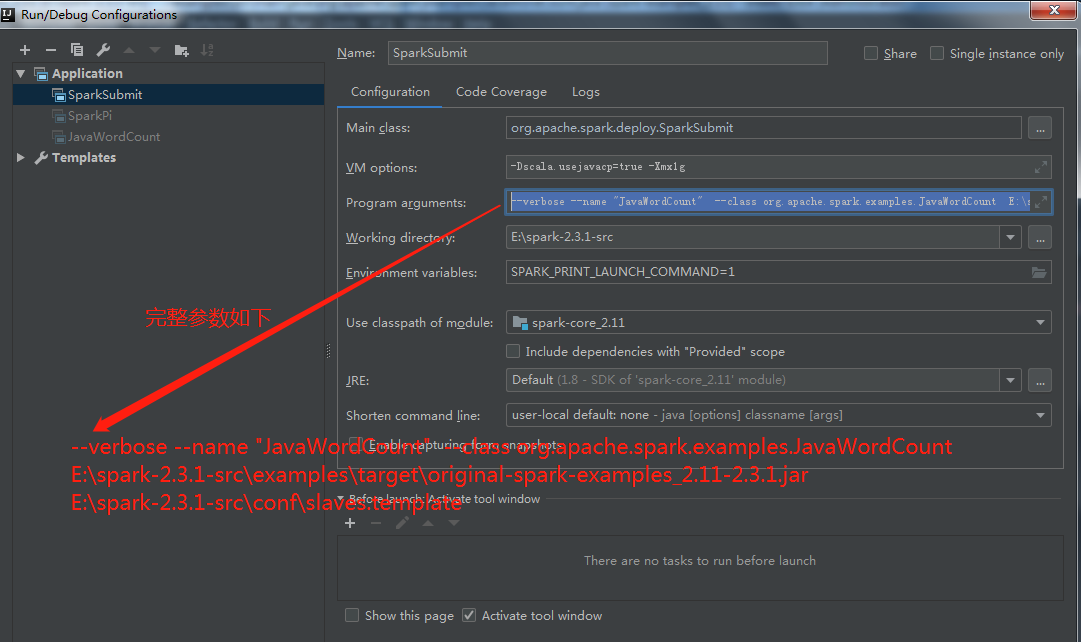
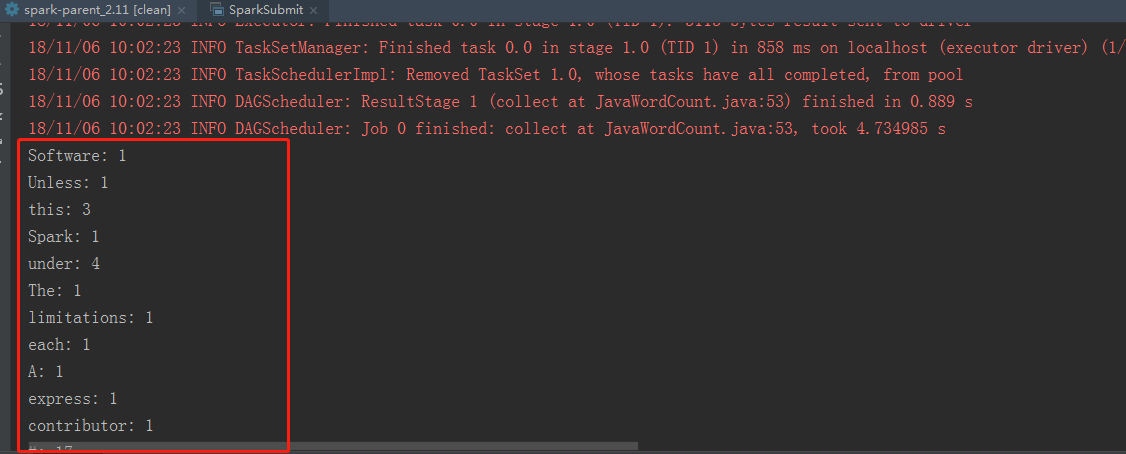
2.2 自定义spark代码类运行(以自带的org.apache.spark.examples.JavaWordCount为例)

windows下在idea用maven导入spark2.3.1源码并编译并运行示例的更多相关文章
- 导入spark2.3.3源码至intellij idea
检查环境配置 maven环境 2.检查scala插件 没有的话可以到https://plugins.jetbrains.com/plugin/1347-scala/versions 下载与idea对应 ...
- spark最新源码下载并导入到开发环境下助推高质量代码(Scala IDEA for Eclipse和IntelliJ IDEA皆适用)(以spark2.2.0源码包为例)(图文详解)
不多说,直接上干货! 前言 其实啊,无论你是初学者还是具备了有一定spark编程经验,都需要对spark源码足够重视起来. 本人,肺腑之己见,想要成为大数据的大牛和顶尖专家,多结合源码和操练编程. ...
- Windows上IDEA搭建最新Spark2.4.3源码调试的开发环境
相信很多同学都想通过阅读一些框架的源码,来提高自己的代码能力,但往往在第一步,搭建环境的时候就碰了壁. 本篇就来介绍下如何在Windows下,将最新版的Spark2.4.3编译,并导入到IDEA编译器 ...
- 如何在IDEA里给大数据项目导入该项目的相关源码(博主推荐)(类似eclipse里同一个workspace下单个子项目存在)(图文详解)
不多说,直接上干货! 如果在一个界面里,可以是单个项目 注意:本文是以gradle项目的方式来做的! 如何在IDEA里正确导入从Github上下载的Gradle项目(含相关源码)(博主推荐)(图文详解 ...
- 使用 IntelliJ IDEA 导入 Spark 最新源码及编译 Spark 源代码(博主强烈推荐)
前言 其实啊,无论你是初学者还是具备了有一定spark编程经验,都需要对spark源码足够重视起来. 本人,肺腑之己见,想要成为大数据的大牛和顶尖专家,多结合源码和操练编程. 准备工作 1.sca ...
- 使用 IntelliJ IDEA 导入 Spark 最新源码及编译 Spark 源代码
前言 其实啊,无论你是初学者还是具备了有一定spark编程经验,都需要对spark源码足够重视起来. 本人,肺腑之己见,想要成为大数据的大牛和顶尖专家,多结合源码和操练编程. 准备工作 1.sca ...
- Spark2.0.0源码编译
Hive默认使用MapReduce作为执行引擎,即Hive on mr,Hive还可以使用Tez和Spark作为其执行引擎,分别为Hive on Tez和Hive on Spark.由于MapRedu ...
- 一步步实现windows版ijkplayer系列文章之七——终结篇(附源码)
一步步实现windows版ijkplayer系列文章之一--Windows10平台编译ffmpeg 4.0.2,生成ffplay 一步步实现windows版ijkplayer系列文章之二--Ijkpl ...
- 一步步实现windows版ijkplayer系列文章之二——Ijkplayer播放器源码分析之音视频输出——视频篇
一步步实现windows版ijkplayer系列文章之一--Windows10平台编译ffmpeg 4.0.2,生成ffplay 一步步实现windows版ijkplayer系列文章之二--Ijkpl ...
随机推荐
- web应用安全发展与介绍
安全与安全圈的认识 中国黑客的发展过程:1990年代初,部分人开始研究黑客技术 1997-1999年,黑客团队涌现,进入黄金时代, 21世纪初,黑客工具傻瓜化,门槛降低,黑客精神不在… 圈内熟知的安全 ...
- javascript中对数组对象的深度拷贝
在前端开发的某些逻辑中,经常需要对现有的js对象创建副本,避免污染原始数据的情况. 如果是简单的一维数组对象,可以使用两个原生方法: 1.splice var arr1 = ['a', 'b', 'c ...
- leetcode 141. Linked List Cycle 、 142. Linked List Cycle II
判断链表有环,环的入口结点,环的长度 1.判断有环: 快慢指针,一个移动一次,一个移动两次 2.环的入口结点: 相遇的结点不一定是入口节点,所以y表示入口节点到相遇节点的距离 n是环的个数 w + n ...
- 集合之Map总结
在前面LZ详细介绍了HashMap.HashTable.TreeMap的实现方法,从数据结构.实现原理.源码分析三个方面进行阐述,对这个三个类应该有了比较清晰的了解,下面LZ就Map做一个简单的总结. ...
- Spring源码分析(二十四)初始化非延迟加载单例
摘要: 本文结合<Spring源码深度解析>来分析Spring 5.0.6版本的源代码.若有描述错误之处,欢迎指正. 完成BeanFactory的初始化工作,其中包括ConversionS ...
- [Nagios] Error: Template 'timman' specified in contact definition could not be not found (c
Check nagios配置文件报错例如以下: [nagios@2 etc]$ /usr/local/nagios/bin/nagios -v /usr/local/nagios/etc/nagios ...
- C++中关于配置文件的问题
眼下本人考虑到部门配置文件较多,所以想写个配置文件检測程序. 眼下大致的思路例如以下三部分; 1, 读取配置文件的内容(*.ini). 查找配置文件,代码例如以下 void CDataBaseDlg: ...
- C++反汇编代码分析–函数调用
转载:http://shitouer.cn/2010/06/method-called/ 代码如下:#include “stdlib.h” int sum(int a,int b,int m,int ...
- block本质探寻一之内存结构
一.代码——命令行模式 //main.m #import <Foundation/Foundation.h> struct __block_impl { void *isa; int Fl ...
- hadoop体系架构
1.1 Hadoop 概念:hadoop是一个由Apache基金会所开发的分布式系统基础架构.是根据google发表的GFS(Google File System)论文产生过来的. ...