【机器学习】--模型评估指标之混淆矩阵,ROC曲线和AUC面积
一、前述
怎么样对训练出来的模型进行评估是有一定指标的,本文就相关指标做一个总结。
二、具体
1、混淆矩阵
混淆矩阵如图:
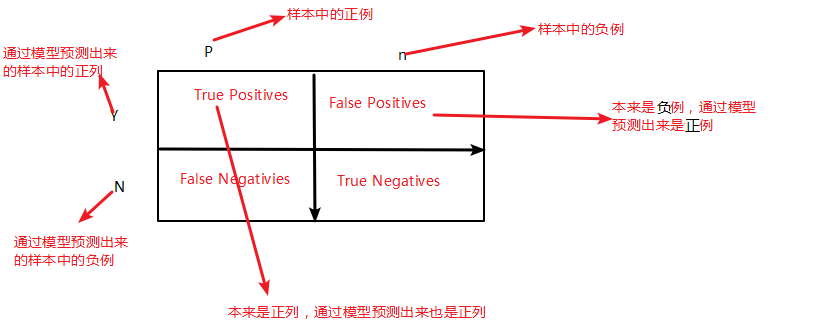
第一个参数true,false是指预测的正确性。
第二个参数true,postitives是指预测的结果。
相关公式:

检测正列的效果:

检测负列的效果:

公式解释:
fp_rate:

tp_rate:

recall:(召回率)

值越大越好
presssion:(准确率)
TP:本来是正例,通过模型预测出来是正列
TP+FP:通过模型预测出来的所有正列数(其中包括本来是负例,但预测出来是正列)
值越大越好
F1_Score:

准确率和召回率是负相关的。如图所示:

通俗解释:
实际上非常简单,精确率是针对我们预测结果而言的,它表示的是预测为正的样本中有多少是真正的正样本。那么预测为正就有两种可能了,一种就是把正类预测为正类(TP),另一种就是把负类预测为正类(FP),也就是

而召回率是针对我们原来的样本而言的,它表示的是样本中的正例有多少被预测正确了。那也有两种可能,一种是把原来的正类预测成正类(TP),另一种就是把原来的正类预测为负类(FN)。

其实就是分母不同,一个分母是预测为正的样本数,另一个是原来样本中所有的正样本数。
2、ROC曲线
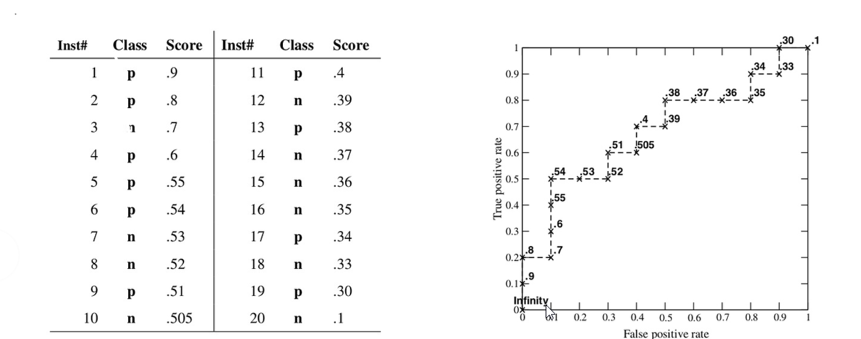
过程:对第一个样例,预测对,阈值是0.9,所以曲线向上走,以此类推。
对第三个样例,预测错,阈值是0.7 ,所以曲线向右走,以此类推。
几种情况:

所以得出结论,曲线在对角线以上,则准确率好。
3、AUC面积

M是样本中正例数
N是样本中负例数
其中累加解释是把预测出来的所有概率结果按照分值升序排序,然后取正例所对应的索引号进行累加
通过AUC面积预测出来的可以知道好到底有多好,坏到底有多坏。因为正例的索引比较大,则AUC面积越大。
总结:

4、交叉验证
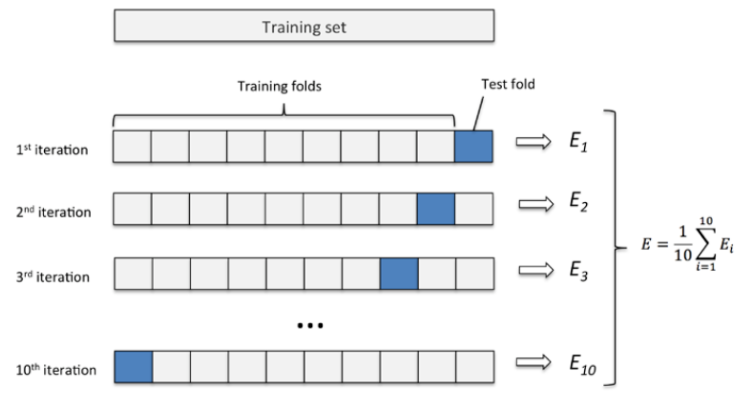
为在实际的训练中,训练的结果对于训练集的拟合程度通常还是挺好的(初试条件敏感),但是对于训练集之外的数据的拟合程度通常就不那么令人满意了。因此我们通常并不会把所有的数据集都拿来训练,而是分出一部分来(这一部分不参加训练)对训练集生成的参数进行测试,相对客观的判断这些参数对训练集之外的数据的符合程度。这种思想就称为交叉验证。
一般3折或者5折交叉验证就足够了。
三、代码
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 文件名: mnist_k_cross_validate.py from sklearn.datasets import fetch_mldata
import matplotlib
import matplotlib.pyplot as plt
import numpy as np
from sklearn.linear_model import SGDClassifier
from sklearn.model_selection import StratifiedKFold
from sklearn.base import clone
from sklearn.model_selection import cross_val_score
from sklearn.base import BaseEstimator #评估指标
from sklearn.model_selection import cross_val_predict
from sklearn.metrics import confusion_matrix
from sklearn.metrics import precision_score
from sklearn.metrics import recall_score
from sklearn.metrics import f1_score
from sklearn.metrics import precision_recall_curve
from sklearn.metrics import roc_curve
from sklearn.metrics import roc_auc_score
from sklearn.ensemble import RandomForestClassifier # Alternative method to load MNIST, if mldata.org is down
from scipy.io import loadmat #利用Matlib加载本地数据
mnist_raw = loadmat("mnist-original.mat")
mnist = {
"data": mnist_raw["data"].T,
"target": mnist_raw["label"][0],
"COL_NAMES": ["label", "data"],
"DESCR": "mldata.org dataset: mnist_k_cross_validate-original",
}
print("Success!")
# mnist_k_cross_validate = fetch_mldata('MNIST_original', data_home='test_data_home')
print(mnist) X, y = mnist['data'], mnist['target'] # X 是70000行 784个特征 y是70000行 784个像素点
print(X.shape, y.shape)
#
some_digit = X[36000]
print(some_digit)
some_digit_image = some_digit.reshape(28, 28)#调整矩阵 28*28=784 784个像素点调整成28*28的矩阵 图片是一个28*28像素的图片 每一个像素点是一个rgb的值
print(some_digit_image)
#
plt.imshow(some_digit_image, cmap=matplotlib.cm.binary,
interpolation='nearest')
plt.axis('off')
plt.show()
#
X_train, X_test, y_train, y_test = X[:60000], X[60000:], y[:60000], y[:60000]#6/7作为训练,1/7作为测试
shuffle_index = np.random.permutation(60000)#返回一组随机的数据 shuffle 打乱60000中每行的值 即每个编号的值不是原先的对应的值
X_train, y_train = X_train[shuffle_index], y_train[shuffle_index] # Shuffle之后的取值
# #
y_train_5 = (y_train == 5)# 是5就标记为True,不是5就标记为false
y_test_5 = (y_test == 5)
print(y_test_5)
#这里可以直接写成LogGression
sgd_clf = SGDClassifier(loss='log', random_state=42)# log 代表逻辑回归 random_state或者random_seed 随机种子 写死以后生成的随机数就是一样的
sgd_clf.fit(X_train, y_train_5)#构建模型
print(sgd_clf.predict([some_digit]))# 测试模型 最终为5
# #
### K折交叉验证
##总共会运行3次
skfolds = StratifiedKFold(n_splits=3, random_state=42)# 交叉验证 3折 跑三次 在训练集中的开始1/3 中测试,中间1/3 ,最后1/3做验证
for train_index, test_index in skfolds.split(X_train, y_train_5):
#可以把sgd_clf = SGDClassifier(loss='log', random_state=42)这一行放入进来,传不同的超参数 这里就不用克隆了
clone_clf = clone(sgd_clf)# clone一个上一个一样的模型 让它不变了 每次初始随机参数w0,w1,w2都一样,所以设定随机种子是一样
X_train_folds = X_train[train_index]#对应的是训练集中训练的X 没有阴影的
y_train_folds = y_train_5[train_index]# 对应的是训练集中的训练y 没有阴影的
X_test_folds = X_train[test_index]#对应的是训练集中的测试的X 阴影部分的
y_test_folds = y_train_5[test_index]#对应的是训练集中的测试的Y 阴影部分的 clone_clf.fit(X_train_folds, y_train_folds)#构建模型
y_pred = clone_clf.predict(X_test_folds)#验证
print(y_pred)
n_correct = sum(y_pred == y_test_folds)# 如若预测对了加和 因为true=1 false=0
print(n_correct / len(y_pred))#得到预测对的精度 #用判断正确的数/总共预测的 得到一个精度
# #PS:这里可以把上面的模型生成直接放在交叉验证里面传一些超参数比如阿尔法,看最后的准确率则知道什么超参数最好。 #这是Sk_learn里面的实现的函数cv是几折,score评估什么指标这里是准确率,结果类似上面一大推代码
print(cross_val_score(sgd_clf, X_train, y_train_5, cv=3, scoring='accuracy')) #这是Sk_learn里面的实现的函数cv是几折,score评估什么指标这里是准确率 class Never5Classifier(BaseEstimator):#给定一个分类器,永远不会分成5这个类别 因为正负列样本不均匀,所以得出的结果是90%,所以只拿精度是不准确的。
def fit(self, X, y=None):
pass def predict(self, X):
return np.zeros((len(X), 1), dtype=bool) never_5_clf = Never5Classifier()
print(cross_val_score(never_5_clf, X_train, y_train_5, cv=3, scoring='accuracy'))#给每一个结果一个结果
# #
# #
##混淆矩阵 可以准确地知道哪一个类别判断的不准
y_train_pred = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3)#给每一个结果预测一个概率
print(confusion_matrix(y_train_5, y_train_pred))
# #
y_train_perfect_prediction = y_train_5
print(confusion_matrix(y_train_5, y_train_5))
#准确率,召回率,F1Score
print(precision_score(y_train_5, y_train_pred))
print(recall_score(y_train_5, y_train_pred))
print(sum(y_train_pred))
print(f1_score(y_train_5, y_train_pred)) sgd_clf.fit(X_train, y_train_5)
y_scores = sgd_clf.decision_function([some_digit])
print(y_scores) threshold = 0 # Z的大小 wT*x的结果
y_some_digit_pred = (y_scores > threshold)
print(y_some_digit_pred) threshold = 200000
y_some_digit_pred = (y_scores > threshold)
print(y_some_digit_pred) y_scores = cross_val_predict(sgd_clf, X_train, y_train_5, cv=3, method='decision_function')
print(y_scores)#直接得出Score precisions, recalls, thresholds = precision_recall_curve(y_train_5, y_scores)
print(precisions, recalls, thresholds) def plot_precision_recall_vs_threshold(precisions, recalls, thresholds):
plt.plot(thresholds, precisions[:-1], 'b--', label='Precision')
plt.plot(thresholds, recalls[:-1], 'r--', label='Recall')
plt.xlabel("Threshold")
plt.legend(loc='upper left')
plt.ylim([0, 1]) # plot_precision_recall_vs_threshold(precisions, recalls, thresholds)
# plt.savefig('./temp_precision_recall') y_train_pred_90 = (y_scores > 70000)
print(precision_score(y_train_5, y_train_pred_90))
print(recall_score(y_train_5, y_train_pred_90)) fpr, tpr, thresholds = roc_curve(y_train_5, y_scores) def plot_roc_curve(fpr, tpr, label=None):
plt.plot(fpr, tpr, linewidth=2, label=label)
plt.plot([0, 1], [0, 1], 'k--')
plt.axis([0, 1, 0, 1])
plt.xlabel('False Positive Rate')
plt.ylabel('True positive Rate') plot_roc_curve(fpr, tpr)
plt.show()
# plt.savefig('img_roc_sgd') print(roc_auc_score(y_train_5, y_scores)) forest_clf = RandomForestClassifier(random_state=42)
y_probas_forest = cross_val_predict(forest_clf, X_train, y_train_5, cv=3, method='predict_proba')
y_scores_forest = y_probas_forest[:, 1] fpr_forest, tpr_forest, thresholds_forest = roc_curve(y_train_5, y_scores_forest)
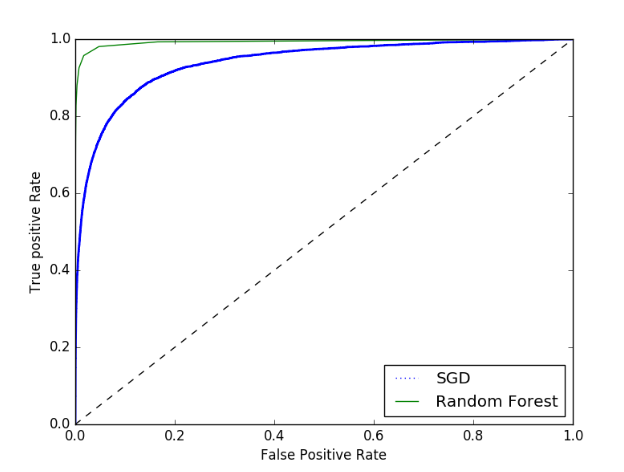
plt.plot(fpr, tpr, 'b:', label='SGD')
plt.plot(fpr_forest, tpr_forest, label='Random Forest')
plt.legend(loc='lower right')
plt.show()
# plt.savefig('./img_roc_forest') print(roc_auc_score(y_train_5, y_scores_forest)) #
#


【机器学习】--模型评估指标之混淆矩阵,ROC曲线和AUC面积的更多相关文章
- 【分类模型评判指标 二】ROC曲线与AUC面积
转自:https://blog.csdn.net/Orange_Spotty_Cat/article/details/80499031 略有改动,仅供个人学习使用 简介 ROC曲线与AUC面积均是用来 ...
- ROC曲线,AUC面积
AUC(Area under Curve):Roc曲线下的面积,介于0.1和1之间.Auc作为数值可以直观的评价分类器的好坏,值越大越好. 首先AUC值是一个概率值,当你随机挑选一个正样本以及负样本, ...
- 评估指标【交叉验证&ROC曲线】
# -*- coding: utf-8 -*- """ Created on Mon Sep 10 11:21:27 2018 @author: zhen "& ...
- 模型监控指标- 混淆矩阵、ROC曲线,AUC值,KS曲线以及KS值、PSI值,Lift图,Gain图,KT值,迁移矩阵
1. 混淆矩阵 确定截断点后,评价学习器性能 假设训练之初以及预测后,一个样本是正例还是反例是已经确定的,这个时候,样本应该有两个类别值,一个是真实的0/1,一个是预测的0/1 TP(实际为正预测为正 ...
- [机器学习] 性能评估指标(精确率、召回率、ROC、AUC)
混淆矩阵 介绍这些概念之前先来介绍一个概念:混淆矩阵(confusion matrix).对于 k 元分类,其实它就是一个k x k的表格,用来记录分类器的预测结果.对于常见的二元分类,它的混淆矩阵是 ...
- 召回率、AUC、ROC模型评估指标精要
混淆矩阵 精准率/查准率,presicion 预测为正的样本中实际为正的概率 召回率/查全率,recall 实际为正的样本中被预测为正的概率 TPR F1分数,同时考虑查准率和查全率,二者达到平衡,= ...
- 混淆矩阵、准确率、精确率/查准率、召回率/查全率、F1值、ROC曲线的AUC值
准确率.精确率(查准率).召回率(查全率).F1值.ROC曲线的AUC值,都可以作为评价一个机器学习模型好坏的指标(evaluation metrics),而这些评价指标直接或间接都与混淆矩阵有关,前 ...
- 【Udacity】机器学习性能评估指标
评估指标 Evaluation metrics 机器学习性能评估指标 选择合适的指标 分类与回归的不同性能指标 分类的指标(准确率.精确率.召回率和 F 分数) 回归的指标(平均绝对误差和均方误差) ...
- 基于sklearn的metrics库的常用有监督模型评估指标学习
一.分类评估指标 准确率(最直白的指标)缺点:受采样影响极大,比如100个样本中有99个为正例,所以即使模型很无脑地预测全部样本为正例,依然有99%的正确率适用范围:二分类(准确率):二分类.多分类( ...
随机推荐
- Tornado框架实现图形验证码功能
图形验证码是项目开发过程中经常遇到的一个功能,在很多语言中都有对应的不同形式的图形验证码功能的封装,python 中同样也有类似的封装操作,通过绘制生成一个指定的图形数据,让前端HTML页面通过链接获 ...
- vagrant命令
$ vagrant init # 初始化 $ vagrant up # 启动虚拟机$ vagrant halt # 关闭虚拟机$ vagrant reload ...
- 深入js隐式类型转换
前言 相信刚开始了解js的时候,都会遇到 2 =='2',但是 1+'2' == '1'+'2'为false的情况,这时候应该会是一脸懵逼的状态,不得不感慨js弱类型的灵活让人发指,隐式类型转换就是这 ...
- 学习Javascript数据结构与算法(第2版)笔记(1)
第 1 章 JavaScript简介 使用 Node.js 搭建 Web 服务器 npm install http-server -g http-server JavaScript 的类型有数字.字符 ...
- 用beego开发服务端应用
用beego开发服务端应用 说明 Quick Start 安装 创建应用 编译运行 打包发布 代码生成 开发文档 目录结构说明 使用配置文件 beego默认参数 路由设置 路由的表述方式 直接设置路由 ...
- [NOIP2014]飞扬的小鸟 D1 T3 loj2500 洛谷P1941
分析: 这是一个DP,没什么好说的,细节很烦人. DP[i][j]表示到第i个位置,高度为j点最少的次数. 转移: 当j=m时 k属于[m-h,m]都可以向DP[i][j]转移,即dp[i][j]=m ...
- zipkin+kafka+elasticsearch
1.安装zookeeper(3.4.6) 安装过程(略) 启动zookeeper ./bin/zkServer.sh start 或者bin/zookeeper-server-start.sh con ...
- ie兼容问题记录
工作中遇到的ie网站兼容性问题 头疼.......... 以下为从网上搜索学习的整理兼容性方法 用于自己记录 #兼容问题 ##css hack: https://blog.csdn.net/fres ...
- 如何看MySql执行计划explain(或desc)
简介 MySQL 提供了一个 EXPLAIN 命令, 它可以对 SELECT 语句进行分析, 并输出 SELECT 执行的详细信息, 以供开发人员针对性优化.EXPLAIN 命令用法十分简单, 在 S ...
- Qt之加减乘除四则运算-支持负数
一.效果展示 如图1所示,是简单的四则运算测试效果,第一列为原始表达式,第二列为转换后的后缀表达式,冒号后为结果.表达式支持负数和空格,图中是使用了5组测试数据,测试结果可能不全,如大家发现算法有问题 ...