#Week5 Regularization
一、The Problem of Overfitting
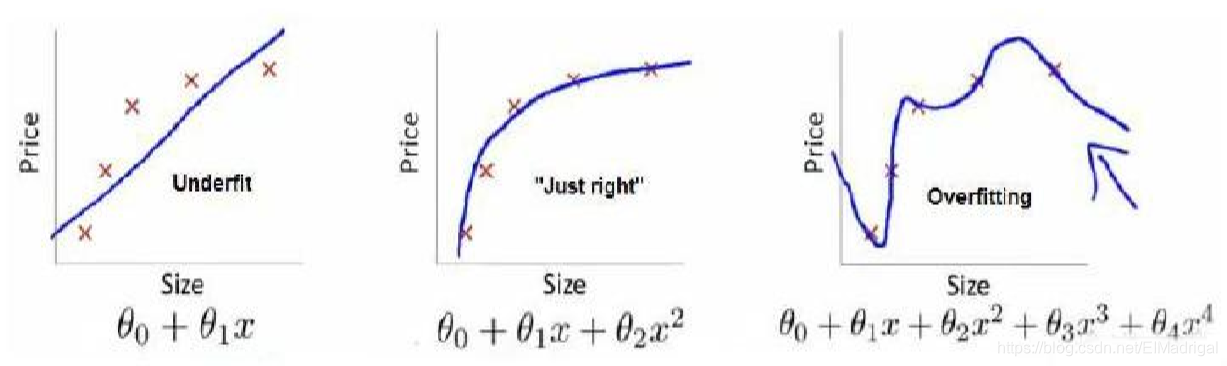
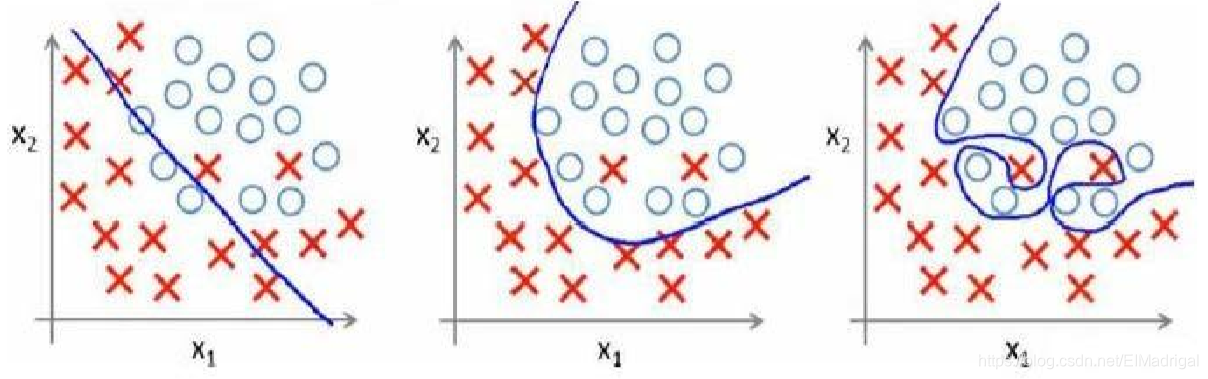
欠拟合(high bias):模型不能很好地适应训练集;
过拟合(high variance):模型过于强调拟合原始数据,测试时效果会比较差。
处理过拟合:
1、丢弃一些特征,包括人工丢弃和算法选择;
2、正则化:保留所有特征,但减小参数的值。
二、Cost Function
过拟合一般是由高次项引起,那么我们可以通过增加某些项的cost,来降低它们的权重。
在梯度下降过程中,要使损失函数变小,那么\(\theta\)就会变得很小,所以假设函数中的\(\theta\)就会变小,该项的权重就会降低。
如果不知道要惩罚哪些特征,可以一起惩罚(除了\(\theta_0\))。
将代价函数改为:
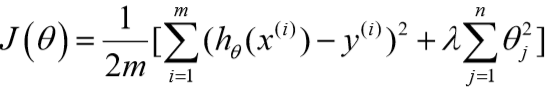
\(\lambda\)是正则化参数。
如果\(\lambda\)过大,那么所有的参数都会最小化,那么假设就会变为\(h_\theta(x)=\theta_0\),造成欠拟合。
三、Regularized Linear Regression
\(\theta_0\)没有正则化处理,所以梯度下降要分情况:
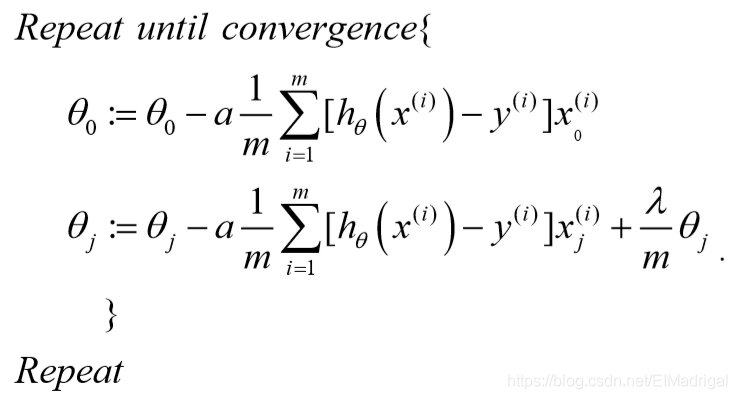
化简下:
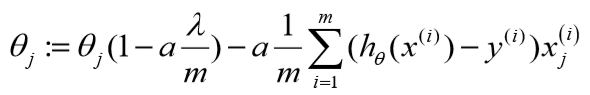
可以看到:
正则化后的参数更新比原来多减小了一个值。
再看线性回归的另外一个工具:常规方程。
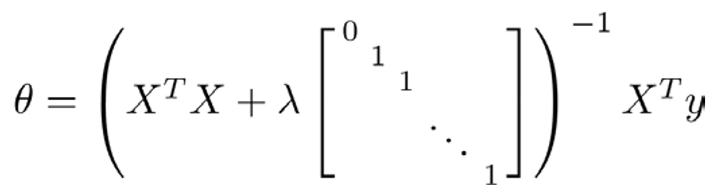
推导过程省略......
四、Regularized Logistic Regression
对于逻辑回归的代价函数,同样增加一个正则化表达式:
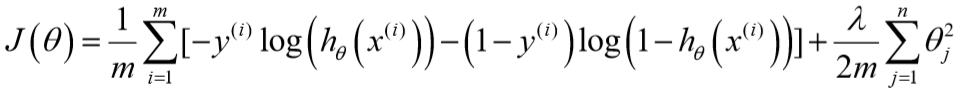
梯度下降算法与线性回归相同,不过\(h_\theta(x)\)不同。
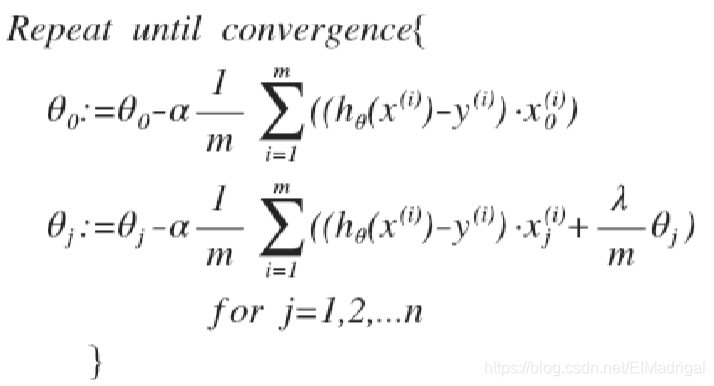
#Week5 Regularization的更多相关文章
- 数据预处理中归一化(Normalization)与损失函数中正则化(Regularization)解惑
背景:数据挖掘/机器学习中的术语较多,而且我的知识有限.之前一直疑惑正则这个概念.所以写了篇博文梳理下 摘要: 1.正则化(Regularization) 1.1 正则化的目的 1.2 正则化的L1范 ...
- 正则化方法:L1和L2 regularization、数据集扩增、dropout
正则化方法:防止过拟合,提高泛化能力 在训练数据不够多时,或者overtraining时,常常会导致overfitting(过拟合).其直观的表现如下图所示,随着训练过程的进行,模型复杂度增加,在tr ...
- Andrew Ng机器学习公开课笔记 -- Regularization and Model Selection
网易公开课,第10,11课 notes,http://cs229.stanford.edu/notes/cs229-notes5.pdf Model Selection 首先需要解决的问题是,模型 ...
- Stanford机器学习笔记-3.Bayesian statistics and Regularization
3. Bayesian statistics and Regularization Content 3. Bayesian statistics and Regularization. 3.1 Und ...
- Regularization on GBDT
之前一篇文章简单地讲了XGBoost的实现与普通GBDT实现的不同之处,本文尝试总结一下GBDT运用的正则化技巧. Early Stopping Early Stopping是机器学习迭代式训练模型中 ...
- 斯坦福第七课:正则化(Regularization)
7.1 过拟合的问题 7.2 代价函数 7.3 正则化线性回归 7.4 正则化的逻辑回归模型 7.1 过拟合的问题 如果我们有非常多的特征,我们通过学习得到的假设可能能够非常好地适应训练集( ...
- Stanford机器学习---第三讲. 逻辑回归和过拟合问题的解决 logistic Regression & Regularization
原文:http://blog.csdn.net/abcjennifer/article/details/7716281 本栏目(Machine learning)包括单参数的线性回归.多参数的线性回归 ...
- Machine Learning - 第3周(Logistic Regression、Regularization)
Logistic regression is a method for classifying data into discrete outcomes. For example, we might u ...
- (五)用正则化(Regularization)来解决过拟合
1 过拟合 过拟合就是训练模型的过程中,模型过度拟合训练数据,而不能很好的泛化到测试数据集上.出现over-fitting的原因是多方面的: 1) 训练数据过少,数据量与数据噪声是成反比的,少量数据导 ...
随机推荐
- 微信小程序常用的方法(留着用)
function zero_fill_hex(num, digits) { let s = num.toString(16); while (s.length < digits) s = &qu ...
- Ceph学习笔记(3)- Monitor
Ceph学习笔记(3)- Monitor 前言: Ceph将cluster map与placement rule合并为一张表称为crush map,作为集群表的一部分.由Monitor对集群表的副 ...
- ubuntu安装fastdfds
ubuntu安装fastdfds 安装fastdfds依赖 cd /user/local wget https://github.com/happyfish100/libfastcom ...
- grub2手动引导linux
仅需要三个命令 1.set root=(hd*,gpt*) hd*为系统所在磁盘,从0开始: gpt为磁盘分区表格式,*为第几分区,mbr分区表为msdos*: 2.linux /boot/vmlin ...
- go 错误处理与测试
Go 没有像 Java 和 .NET 那样的 try/catch 异常机制:不能执行抛异常操作.但是有一套 defer-panic-and-recover 机制(参见 13.2-13.3 节). Go ...
- C++值多态:传统多态与类型擦除之间
引言 我有一个显示屏模块: 模块上有一个128*64的单色显示屏,一个单片机(B)控制它显示的内容.单片机的I²C总线通过四边上的排针排母连接到其他单片机(A)上,A给B发送指令,B绘图. B可以向屏 ...
- 7.1 java 类、(成员)变量、(成员)方法
/* * 面向对象思想: * 面向对象是基于面向过程的编程思想. * * 面向过程:强调的是每一个功能的步骤 * 面向对象:强调的是对象,然后由对象去调用功能 * * 面向对象的思想特点: * A:是 ...
- 【python实现卷积神经网络】卷积层Conv2D反向传播过程
代码来源:https://github.com/eriklindernoren/ML-From-Scratch 卷积神经网络中卷积层Conv2D(带stride.padding)的具体实现:https ...
- 八、路由详细介绍之动态路由OSPF(重点)
一.OSPF介绍 OSPF优点:无环路.收敛快.扩展性好.支持认证 二.工作原理: 图中RTA.RTB.RTC每个路由器都会生成一个LSA, 通过LSA泛洪进行互相发送相互学习,形成LSDB (链路状 ...
- SpringCloud入门(十): Config 统一配置中心
SpringCloud Config 简介 在分布式系统中,由于服务组件过多,为了方便争对不通的环境下的服务配置文件统一管理,实时更新,所以出现了分布式配置中心组件.市面上开源的配置中心有很多,360 ...