Python在多个Excel文件中找出缺失数据行数多的文件
本文介绍基于Python语言,针对一个文件夹下大量的Excel表格文件,基于其中每一个文件内、某一列数据的特征,对其加以筛选,并将符合要求与不符合要求的文件分别复制到另外两个新的文件夹中的方法。
首先,我们来明确一下本文的具体需求。现有一个文件夹,其中有大量的Excel表格文件(在本文中我们就以csv格式的文件为例);如下图所示。
其中,每一个Excel表格文件都有着如下图所示的数据格式。
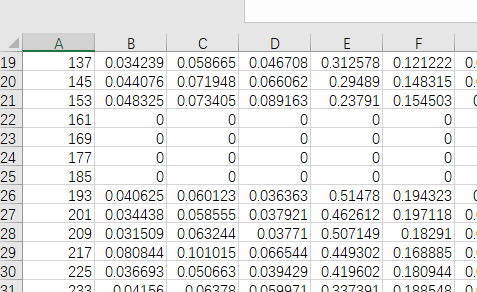
如上图所示,各个文件都有着这样的问题——有些行的数据是无误的,而有些行,除了第一列,其他列都是0值。因此,我们希望就以第2列为标准,找出含有0值数量低于或高于某一阈值的表格文件——其中,0值数量多,肯定不利于我们的分析,我们将其放入一个新的文件夹;而0值数量少的,我们才可以对这一表格文件加以后续的分析,我们就将其放入另一个新的文件夹中。因此,计算出每一个表格文件对应的的0值数量百分比后,我们就进一步将这一Excel表格文件复制到对应的文件夹内。
知道了需求,我们就可以开始代码的撰写。其中,本文用到的代码如下所示。
# -*- coding: utf-8 -*-
"""
Created on Tue May 16 20:19:50 2023
@author: fkxxgis
"""
import os
import shutil
import pandas as pd
def filter_copy_files(original_path, useful_path, useless_path, threshold):
original_all_file = os.listdir(original_path)
for file in original_all_file:
path = os.path.join(original_path, file)
if file.endswith(".csv") and os.path.isfile(path):
df = pd.read_csv(path)
column_value = df.iloc[:, 1]
zero_count = (column_value == 0).sum()
zero_ratio = zero_count / len(column_value)
if zero_ratio < threshold:
new_path = os.path.join(useful_path, file)
shutil.copy(path, new_path)
else:
new_path = os.path.join(useless_path, file)
shutil.copy(path, new_path)
filter_copy_files("E:/01_Reflectivity/99_Model_Training/00_Data/02_Extract_Data/13_AllYearAverage",
"E:/01_Reflectivity/99_Model_Training/00_Data/02_Extract_Data/14_PointSelection/LowMissingRate",
"E:/01_Reflectivity/99_Model_Training/00_Data/02_Extract_Data/14_PointSelection/HighMissingRate",
0.30)
其中,上述代码是一个筛选并复制文件的函数。该函数的目的是根据给定的阈值将具有不同缺失率的文件从一个文件夹复制到另外两个文件夹。
在代码中,filter_copy_files函数接受四个参数:
original_path:原始文件夹的路径,其中包含要筛选的.csv文件。useful_path:有用文件的目标文件夹路径,将满足阈值要求(也就是0值数量低于阈值)的文件复制到此处。useless_path:无用文件的目标文件夹路径,将不满足阈值要求(也就是0值数量高于阈值)的文件复制到此处。threshold:阈值,用于确定文件的缺失率是否满足要求。
函数首先使用os.listdir获取原始文件夹中的所有文件名,然后遍历每个文件名。对于以.csv结尾且为文件的文件,函数使用pd.read_csv读取.csv文件,并通过df.iloc[:, 1]获取第2列的值。
接下来,函数计算第2列中为零的元素数量,并通过将其除以列的总长度来计算缺失率。根据阈值判断缺失率是否满足要求。
如果缺失率小于阈值,函数将文件复制到useful_path目标文件夹中,使用shutil.copy函数实现复制操作。否则,函数将文件复制到useless_path文件夹中。
最后,我们调用了filter_copy_files函数,并传递了相应的参数来执行文件筛选和复制操作。
运行上述代码,我们即可在对应的文件夹中看到文件。如下图所示,0值数量低于阈值的表格文件都复制到了这个LowMissingRate文件夹中,我们即可对其加以后续处理;而那些0值数量高于阈值的表格文件,就放到另一个HighMissingRate文件夹中了。
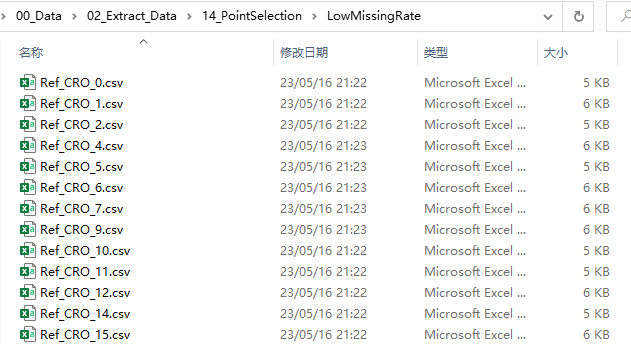
至此,大功告成。
Python在多个Excel文件中找出缺失数据行数多的文件的更多相关文章
- 如何在 Linux 中找出最近或今天被修改的文件
1. 使用 ls 命令,只列出你的 home 文件夹中今天的文件. ls -al --time-style=+%D | grep `date +%D` 其中: -a- 列出所有文件,包括隐藏文件 -l ...
- PHP如何在两个大文件中找出相同的记录?
1.引言 给定a,b两个文件, 分别有x,y行数据, 其中(x, y均大于10亿), 机器内存限制100M,该如何找出其中相同的记录? 2.思路 处理该问题的困难主要是无法将这海量数据一次性读进内存中 ...
- 查看SqlAzure和SQLServer中的每个表数据行数
SqlAzure中的方式: select t.name ,s.row_count from sys.tables t join sys.dm_db_partition_stats s ON t.obj ...
- BD面试题1-两个大文件中找出公共记录[转载]
转自:https://blog.csdn.net/tiankong_/article/details/77234726#commentBox 1.题目 给定a.b两个文件,各存放50亿个url,每个u ...
- 在一张id连续的表中找出缺失的id
有这样一张表: create table tb_lostid( id number(6,0) primary key not null, name nvarchar2(20) not null ) 可 ...
- Linux:从文件中搜索关键字并显示行数(cat,grep函数)
假如有test1.txt的格式如下图所示: 有test2.txt的内容如下: 现需将test2.txt含有的关键字的行搜索出来并显示行数 则可以用到命令: cat test1.txt | grep - ...
- Linux/Unix 怎样找出并删除某一时间点的文件(转)
在Linux/Unix系统中,我们的应用每天会产生日志文件,每天也会备份应用程序和数据库,日志文件和备份文件长时间积累会占用大量的存储空间,而有些日志和备份文件是不需要长时间保留的,一般保留7天内的文 ...
- 海量数据处理 - 10亿个数中找出最大的10000个数(top K问题)
前两天面试3面学长问我的这个问题(想说TEG的3个面试学长都是好和蔼,希望能完成最后一面,各方面原因造成我无比想去鹅场的心已经按捺不住了),这个问题还是建立最小堆比较好一些. 先拿10000个数建堆, ...
- 另类爬虫:从PDF文件中爬取表格数据
简介 本文将展示一个稍微不一样点的爬虫. 以往我们的爬虫都是从网络上爬取数据,因为网页一般用HTML,CSS,JavaScript代码写成,因此,有大量成熟的技术来爬取网页中的各种数据.这次, ...
- 海量数据中找出前k大数(topk问题)
海量数据中找出前k大数(topk问题) 前两天面试3面学长问我的这个问题(想说TEG的3个面试学长都是好和蔼,希望能完成最后一面,各方面原因造成我无比想去鹅场的心已经按捺不住了),这个问题还是建立最小 ...
随机推荐
- 全面解释人工智能LLM模型的真实工作原理(三)
前一篇:<全面解释人工智能LLM模型的真实工作原理(二)> 序言:前面两节中,我们介绍了大语言模型的设计图和实现了一个能够生成自然语言的神经网络.这正是现代先进人工智能语言模型的雏形.不过 ...
- git安装-Tortoise git 安装汉化教程
1.首先下载 去官网下载 如果下载比较慢的,链接自取 https://pan.quark.cn/s/fcb9d0b39c7f 2. 安装git 3. 安装git图形化工具Tortoise git 4. ...
- nginx记录日志时记录服务器响应的内容
目前的 nginx 是不支持输出 response 报文体的 使用body_filter_by_lua来分配请求报文体给一个nginx变量.下面是一个示例 worker_processes 1; er ...
- 基于pikachu靶场的水平越权详解
1. pikachu靶场搭建 如果你在之前已经使用过phpstudy了,参考pikachu 靶场环境搭建 如果在靶场搭建中遇到一些问题,参考皮卡丘靶场搭建遇到的问题大全 2. 水平越权简介 水平越权是 ...
- Codeforces 777 题目研讨
题目连接 A B C D E 题目分析 A 难度:普及− 题面翻译: 给你三张牌:\(0\),\(1\),\(2\). 最初选一张,然后依次进行 \(n\) 次交换,交换规则为:中间一张和左边的一张, ...
- JDBC中数据库的连接与查询
让我们仔细看看是怎么访问数据库的 package sql; import java.sql.Connection; import java.sql.DriverManager; import java ...
- 国产数据库oceanBbase,达梦,金仓与mysql数据库的性能对比 一、比对方法和结果
最近调研了三款国产化数据库与mysql做对比,调研主要性能指标是大数据写入速度.大数据读取速度以及是否支持分表. 一.测试结果 测试结果与预期的差别很大 1.先说oceanBase社区版这款数 ...
- [python] Python异步编程库asyncio使用指北
Python的asyncio模块提供了基于协程(coroutines)的异步编程(asynchronous programming)模型.作为一种高效的编程范式,异步编程允许多个轻量级任务并发执行,且 ...
- python之日志记录loguru
安装: pip install loguru 基础使用: from loguru import logger logger.debug("This is a debug...") ...
- 销讯通CRM客户关系管理系统的功能拆分
随着技术的发展,CRM系统(客户关系管理)成为企业不可或缺的工具,本文从医药行业角度简要谈谈CRM系统的功能. 从业务的理解来说,从医药行业来说,CRM客户管理系统的有以下几部分功能: 01 客户的分 ...