spark (五) RDD的创建 & 分区
1. RDD的创建方式
1.1 从内存创建RDD
主要依赖如下两个方法
- parallelize
- makeRDD
- 底层调用的还是
parallelize
- 底层调用的还是
def main(args: Array[String]): Unit = {
val sparkConfig: SparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("WordCount")
val sparkContext: SparkContext = new SparkContext(sparkConfig)
val rdd1: RDD[Int] = sparkContext.parallelize(
List(1, 2, 3, 4)
)
// makeRDD 底层调用的还是parallelize
val rdd2: RDD[Int] = sparkContext.makeRDD(
List(1, 2, 3, 4)
)
}
1.2 从外部存储(文件)创建RDD
由外部存储系统的数据集创建RDD包括
- 本地文件系统
- 所有Hadoop支持的数据集,比如HDFS、HBase等
def main(args: Array[String]): Unit = {
val sparkConfig: SparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("WordCount")
val sparkContext: SparkContext = new SparkContext(sparkConfig)
val rdd1: RDD[String] = sparkContext.textFile("data") // 或者 hdfs://master:7077/input
rdd1.collect().foreach(println)
sparkContext.stop()
}
1.3 从其他的RDD创建
下述的flatMap map reduceByKey 每个操作都是以上一个RDD为基础创建另一个RDD
def main(args: Array[String]): Unit = {
val sparkConfig: SparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("WordCount")
val sparkContext: SparkContext = new SparkContext(sparkConfig)
val rdd1: RDD[String] = sparkContext.textFile("data") // 或者 hdfs://master:7077/input
rdd1
.flatMap(word => word.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
.collect()
.foreach(println)
sparkContext.stop()
}
1.4 直接 new RDD
spark框架中会这么操作
2. 分区(partition)
2.1 makeRDD的分区
可以通过以下优先级方式指定分区
- 优先使用
makeRDD的第二个参数指定的分区数量 - 使用默认的配置的分区数量
- SparkConf 若指定了
spark.default.parallelism, 则用这个 - 否则使用CPU的核数(这里的CPU的核数在本地模式下,如
local[3]则为3,local[*]等于物理机真实的CPU核数)
- SparkConf 若指定了
// 第二个参数指定numSlices, 即分区的数量
val rdd: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4), 2)
完整的表现分区的例子
package com.lzw.bigdata.spark.core.rdd_basic_usage_1
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Rdd_4_Partition_From_Mem {
def main(args: Array[String]): Unit = {
val sparkConfig: SparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("WordCount")
// .set("spark.default.parallelism", "5")
val sparkContext: SparkContext = new SparkContext(sparkConfig)
val rdd: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4), 2)
// 保存成分区文件,每个分区会生成一个文件,可以借此查看真实生成了几个分区
rdd.saveAsTextFile("output")
sparkContext.stop()
}
}
2.2 读取文件的分区例子
spark读取文件借助的是hadoop的方法, 所以以下的读取规则是hadoop的规则
// 可以指定 minPartitions, 不指定默认是 math.min(defaultParallelism, 2)
sparkContext.textFile("data/word.txt", 2)
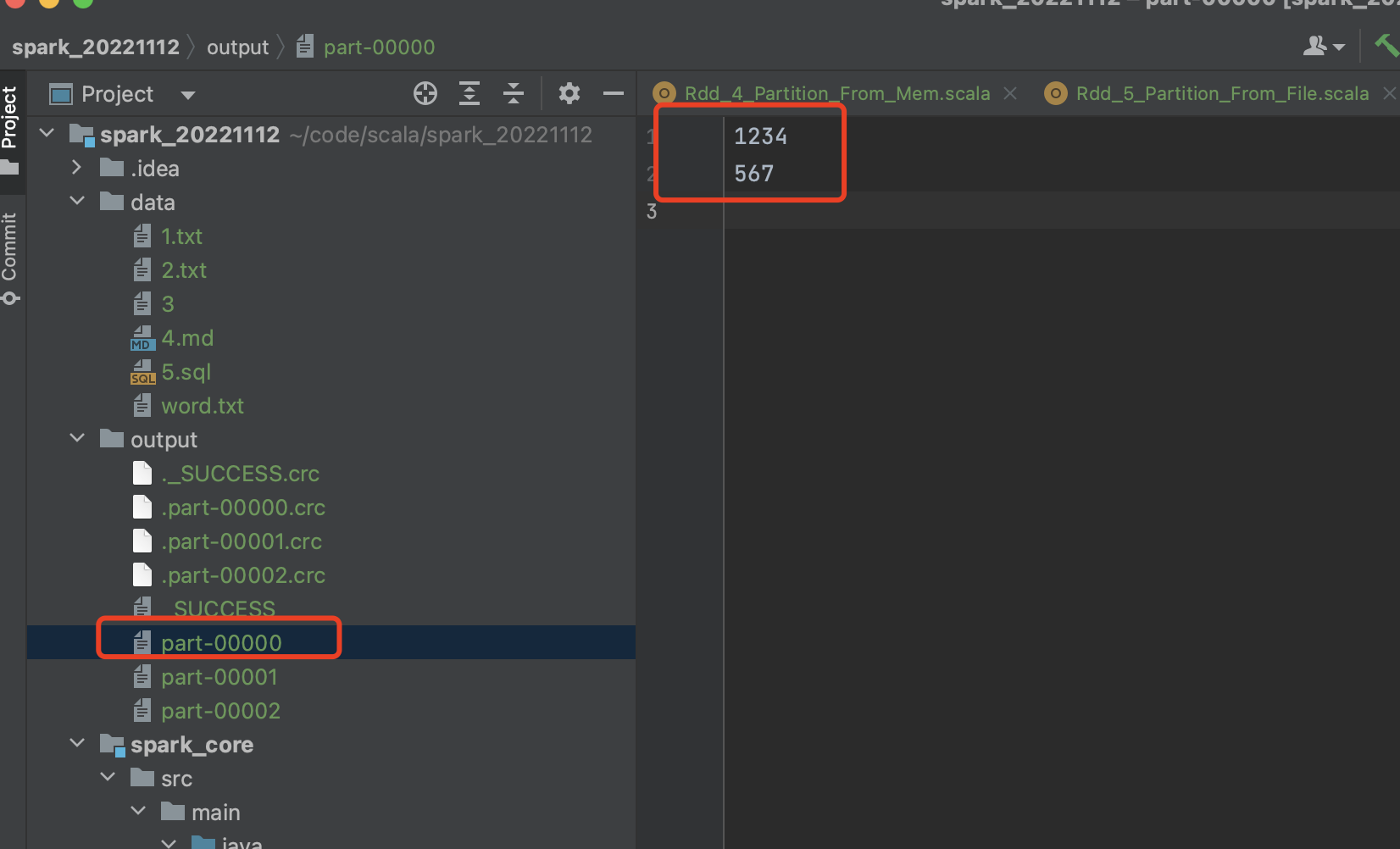
以以下一个文件word.txt为例, 该文件算上换行符\n一共13个字节
1234
567
8900
2.2.1 读取文件分区规则
所以分区数计算方式为
分区数: 13 bytes / 2(这里2是minPartitions) = 6
13 bytes / 6 bytes = 2分区 + 剩余的1byte => 1/6 > 0.1 => 3分区
2.2.2 每个分区的数据
每个分区里面的数据, (hadoop按偏移量之后按行读取):
分区1预期 [0, 6] => 1234\n
567\n
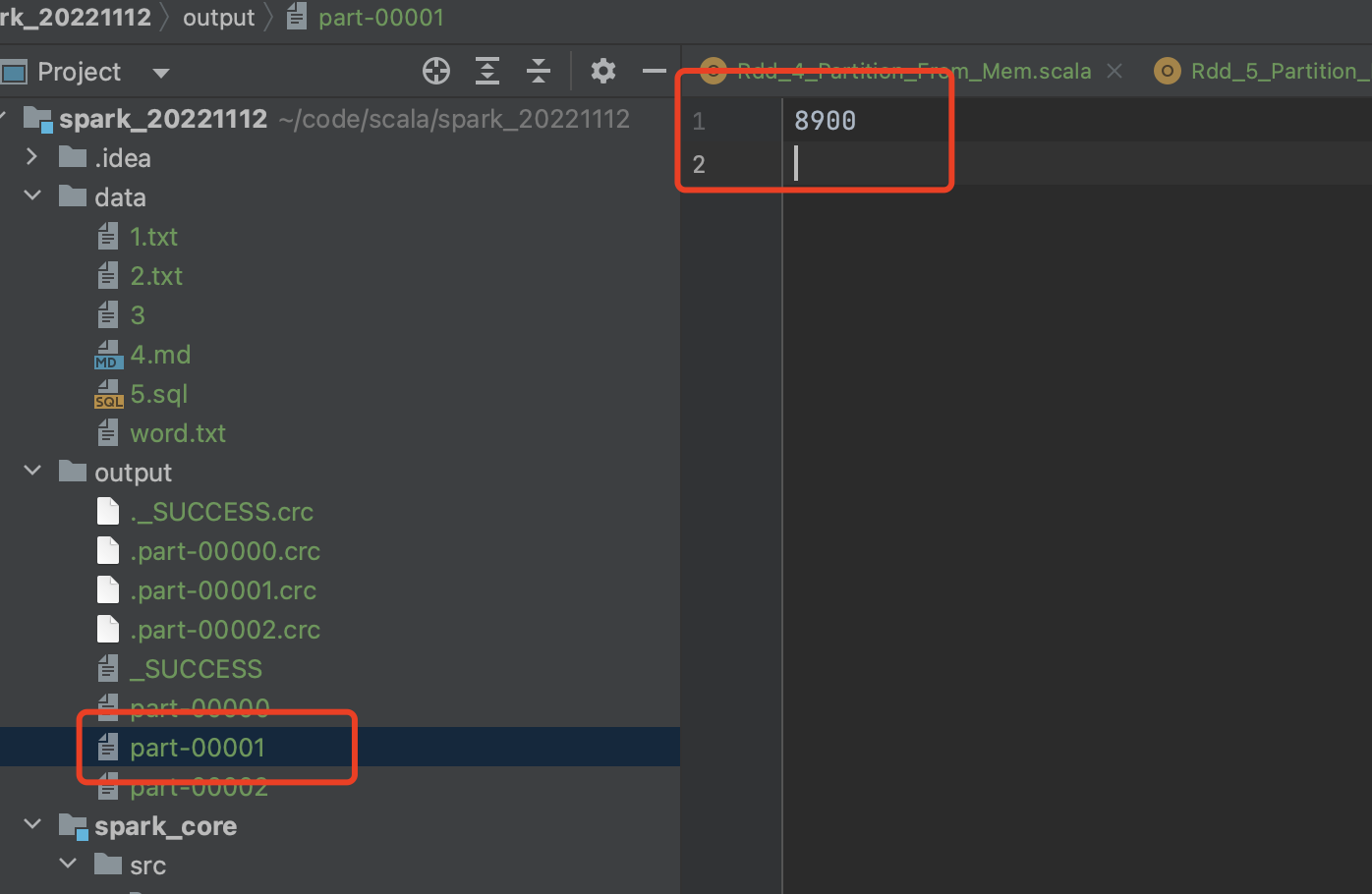
分区2预期[6, 12] => 但是上一个分区因为是偏移量到了某一行,某行就都被读走了,所以真实的
=> 8900
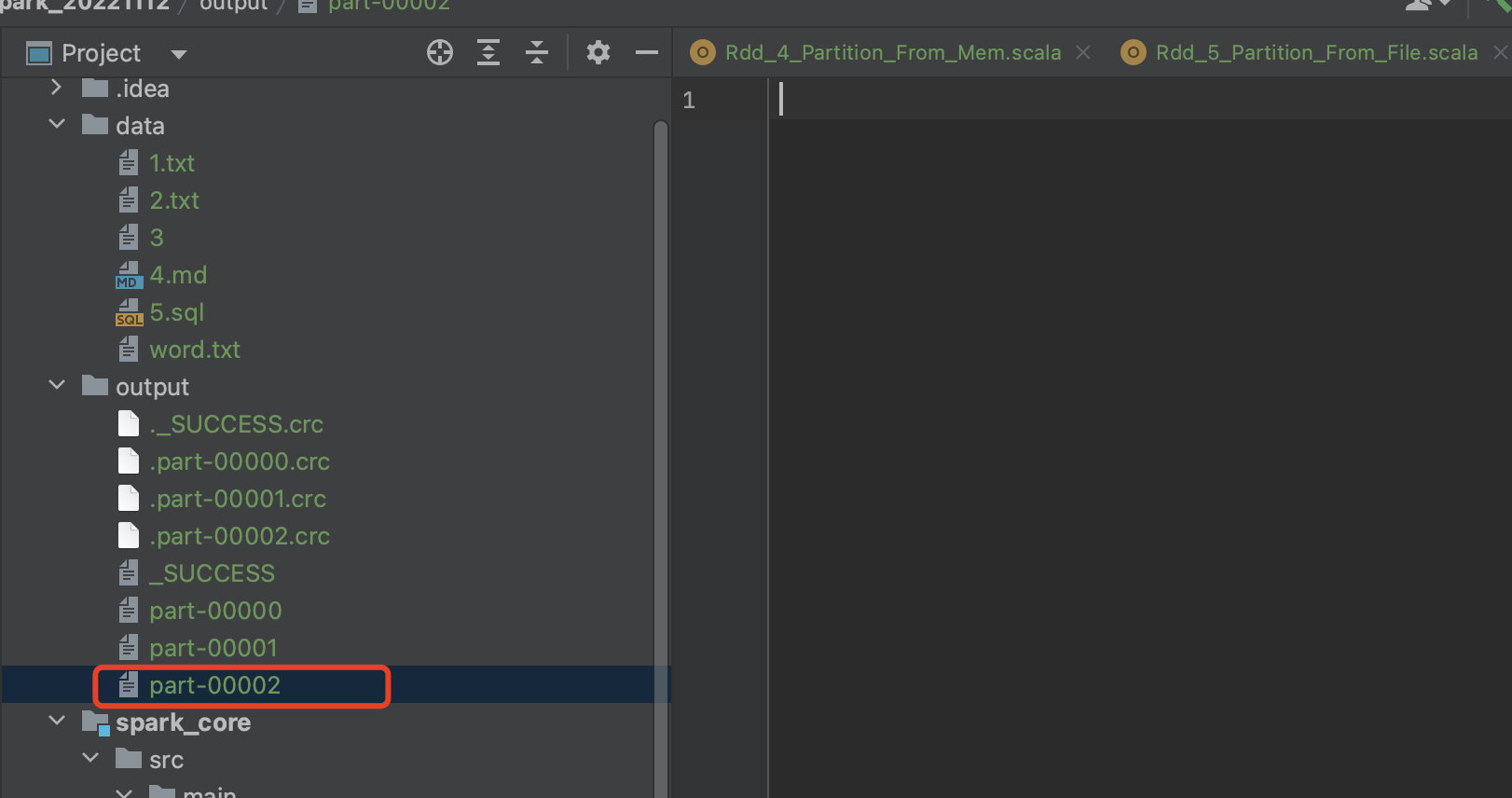
分区3预计[12, 13] => 已无数据可读
2.2.3 完整示例
package com.lzw.bigdata.spark.core.rdd_basic_usage_1
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Rdd_5_Partition_From_File {
def main(args: Array[String]): Unit = {
val sparkConfig: SparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("WordCount")
// .set("spark.default.parallelism", "5")
val sparkContext: SparkContext = new SparkContext(sparkConfig)
/*
1234\n
567\n
8900
分区数: 13 bytes / 2(这里2是minPartitions) = 6
13 bytes / 6 bytes = 2分区 + 剩余的1byte => 1/6 > 0.1 => 3分区
每个分区里面的数据, (hadoop按偏移量之后按行读取):
分区1预期 [0, 6] => 1234\n
567\n
分区2预期[6, 12] => 但是上一个分区因为是偏移量到了某一行,某行就都被读走了,所以真实的
=> 8900
分区3预计[12, 13] => 已无数据可读
*/
val rdd: RDD[String] = sparkContext.textFile("data/word.txt", 2)
rdd.saveAsTextFile("output")
sparkContext.stop()
}
}
spark (五) RDD的创建 & 分区的更多相关文章
- spark 中如何查看单个RDD分区的内容(创建分区,查看分区数)
spark 创建分区 val scores = Array(("Fred", 88), ("Fred", 95), ("Fred", 91) ...
- Spark核心RDD、什么是RDD、RDD的属性、创建RDD、RDD的依赖以及缓存、
1:什么是Spark的RDD??? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行 ...
- 【Spark】快来学习RDD的创建以及操作方式吧!
目录 RDD的创建 三种方式 从一个集合中创建 从文件中创建 从其他的RDD转化而来 RDD编程常用API 算子分类 Transformation 概述 帮助文档 常用Transformation表 ...
- Spark RDD概念学习系列之RDD的创建(六)
RDD的创建 两种方式来创建RDD: 1)由一个已经存在的Scala集合创建 2)由外部存储系统的数据集创建,包括本地文件系统,还有所有Hadoop支持的数据集,比如HDFS.Cassandra.H ...
- Spark核心——RDD
Spark中最核心的概念为RDD(Resilient Distributed DataSets)中文为:弹性分布式数据集,RDD为对分布式内存对象的 抽象它表示一个被分区不可变且能并行操作的数据集:R ...
- [Spark] Spark的RDD编程
本篇博客中的操作都在 ./bin/pyspark 中执行. RDD,即弹性分布式数据集(Resilient Distributed Dataset),是Spark对数据的核心抽象.RDD是分布式元素的 ...
- 关于Spark中RDD的设计的一些分析
RDD, Resilient Distributed Dataset,弹性分布式数据集, 是Spark的核心概念. 对于RDD的原理性的知识,可以参阅Resilient Distributed Dat ...
- 理解Spark的RDD
RDD是个抽象类,定义了诸如map().reduce()等方法,但实际上继承RDD的派生类一般只要实现两个方法: def getPartitions: Array[Partition] def com ...
- Spark源码分析之分区器的作用
最近因为手抖,在Spark中给自己挖了一个数据倾斜的坑.为了解决这个问题,顺便研究了下Spark分区器的原理,趁着周末加班总结一下~ 先说说数据倾斜 数据倾斜是指Spark中的RDD在计算的时候,每个 ...
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
随机推荐
- 删除 KubeSphere 中一直卡在 Terminating 的 Namespace
介绍 最近一直在玩 EKS(Elastic Kubernetes Service -- Amazon EKS) 和 KubeSphere. 因为之前没有使用过 EKS 和 KubeSphere,所以这 ...
- 将NC栅格表示时间维度的数据提取出来的方法
本文介绍基于Python语言,逐一读取大量.nc格式的多时相栅格文件,导出其中所具有的全部时间信息的方法. .nc是NetCDF(Network Common Data Form)文件的扩展名 ...
- 五分钟掌握Python中配置文件解析器configparser的使用
--- 好的方法很多,我们先掌握一种 --- [背景] 这里描述的配置文件为自动化用例中使用到的信息,非pytest自动化框架中例如pytest.ini, conftest.py等具有特殊意义的配 ...
- Go语言单元测试的执行
Go 语言推荐测试文件和源代码文件放在同一目录下,测试文件以 _test.go 结尾.比如,当前 package 有 calc.go 一个文件,我们想测试 calc.go 中的 Add 和 Mul 函 ...
- 使用wxpython开发跨平台桌面应用,常用窗体布局BoxSizer,FlexGridSizer,GridBagSizer的介绍处理
我们在开发桌面应用的时候,不管是之前C#开发Winform的时候,还是现在使用wxpython来开发跨平台应用的时候,都需要了解布局的处理,wxpython的常用布局Sizer类,包括BoxSizer ...
- bitset优化传递闭包
bitset优化传递闭包 时间复杂度 \(O(\frac{n^3}{w})\) #include<bits/stdc++.h> #define F(i,l,r) for(int i=l;i ...
- 2.15 Linux中一切皆文件[包含优缺点]
Linux 中所有内容都是以文件的形式保存和管理的,即一切皆文件,普通文件是文件,目录(Windows 下称为文件夹)是文件,硬件设备(键盘.监视器.硬盘.打印机)是文件,就连套接字(socket). ...
- 3-3 C++ vector类型
目录 3.3.0 模板(Template) vector说明 模板简介 3.3.1 vector的定义和初始化 初始化的方式 总结初始化 3.3.2 往vector中添加元素 3.3.3 vector ...
- Codeforces 2023/2024 A-H
题面 A B C D E F G H 难度:红 橙 黄 绿 蓝 紫 黑 黑 题解 A 题目大意: 输入 \(a\),\(b\),解不等式 \(b - 2x \le a - x (0 \le x \le ...
- String,StringBuffer、StringBuilder的区别
1.可变性 String:是不可变的.其内部是fianl修饰的,每次变更都会创建一个新的对象. StringBuffer.StringBuilder是可变的,字符串的变更是不会创建新对象的. 2.线程 ...