spark (五) RDD的创建 & 分区
1. RDD的创建方式
1.1 从内存创建RDD
主要依赖如下两个方法
- parallelize
- makeRDD
- 底层调用的还是
parallelize
- 底层调用的还是
def main(args: Array[String]): Unit = {
val sparkConfig: SparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("WordCount")
val sparkContext: SparkContext = new SparkContext(sparkConfig)
val rdd1: RDD[Int] = sparkContext.parallelize(
List(1, 2, 3, 4)
)
// makeRDD 底层调用的还是parallelize
val rdd2: RDD[Int] = sparkContext.makeRDD(
List(1, 2, 3, 4)
)
}
1.2 从外部存储(文件)创建RDD
由外部存储系统的数据集创建RDD包括
- 本地文件系统
- 所有Hadoop支持的数据集,比如HDFS、HBase等
def main(args: Array[String]): Unit = {
val sparkConfig: SparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("WordCount")
val sparkContext: SparkContext = new SparkContext(sparkConfig)
val rdd1: RDD[String] = sparkContext.textFile("data") // 或者 hdfs://master:7077/input
rdd1.collect().foreach(println)
sparkContext.stop()
}
1.3 从其他的RDD创建
下述的flatMap map reduceByKey 每个操作都是以上一个RDD为基础创建另一个RDD
def main(args: Array[String]): Unit = {
val sparkConfig: SparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("WordCount")
val sparkContext: SparkContext = new SparkContext(sparkConfig)
val rdd1: RDD[String] = sparkContext.textFile("data") // 或者 hdfs://master:7077/input
rdd1
.flatMap(word => word.split(" "))
.map(word => (word, 1))
.reduceByKey(_ + _)
.collect()
.foreach(println)
sparkContext.stop()
}
1.4 直接 new RDD
spark框架中会这么操作
2. 分区(partition)
2.1 makeRDD的分区
可以通过以下优先级方式指定分区
- 优先使用
makeRDD的第二个参数指定的分区数量 - 使用默认的配置的分区数量
- SparkConf 若指定了
spark.default.parallelism, 则用这个 - 否则使用CPU的核数(这里的CPU的核数在本地模式下,如
local[3]则为3,local[*]等于物理机真实的CPU核数)
- SparkConf 若指定了
// 第二个参数指定numSlices, 即分区的数量
val rdd: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4), 2)
完整的表现分区的例子
package com.lzw.bigdata.spark.core.rdd_basic_usage_1
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Rdd_4_Partition_From_Mem {
def main(args: Array[String]): Unit = {
val sparkConfig: SparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("WordCount")
// .set("spark.default.parallelism", "5")
val sparkContext: SparkContext = new SparkContext(sparkConfig)
val rdd: RDD[Int] = sparkContext.makeRDD(List(1, 2, 3, 4), 2)
// 保存成分区文件,每个分区会生成一个文件,可以借此查看真实生成了几个分区
rdd.saveAsTextFile("output")
sparkContext.stop()
}
}
2.2 读取文件的分区例子
spark读取文件借助的是hadoop的方法, 所以以下的读取规则是hadoop的规则
// 可以指定 minPartitions, 不指定默认是 math.min(defaultParallelism, 2)
sparkContext.textFile("data/word.txt", 2)
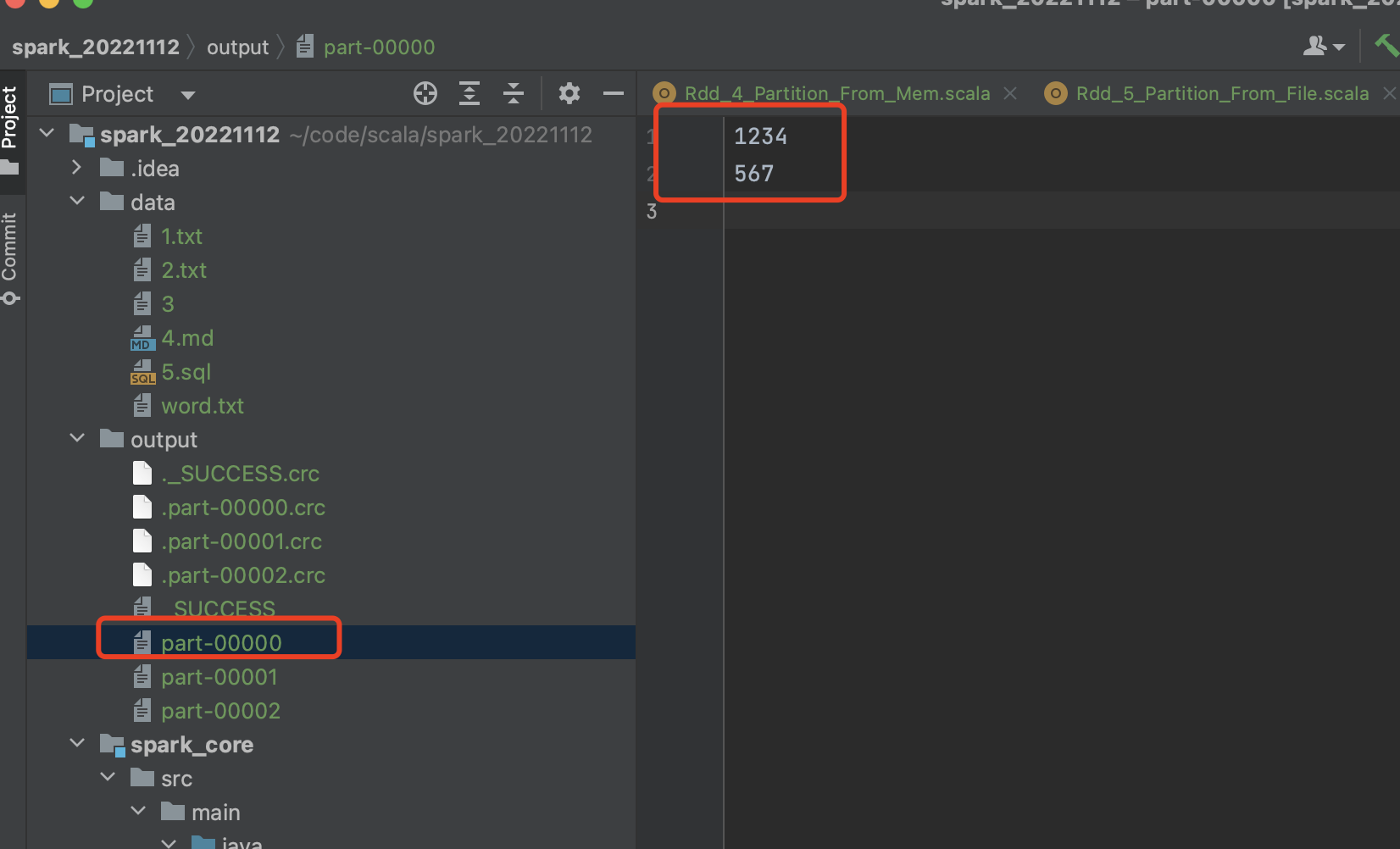
以以下一个文件word.txt为例, 该文件算上换行符\n一共13个字节
1234
567
8900
2.2.1 读取文件分区规则
所以分区数计算方式为
分区数: 13 bytes / 2(这里2是minPartitions) = 6
13 bytes / 6 bytes = 2分区 + 剩余的1byte => 1/6 > 0.1 => 3分区
2.2.2 每个分区的数据
每个分区里面的数据, (hadoop按偏移量之后按行读取):
分区1预期 [0, 6] => 1234\n
567\n
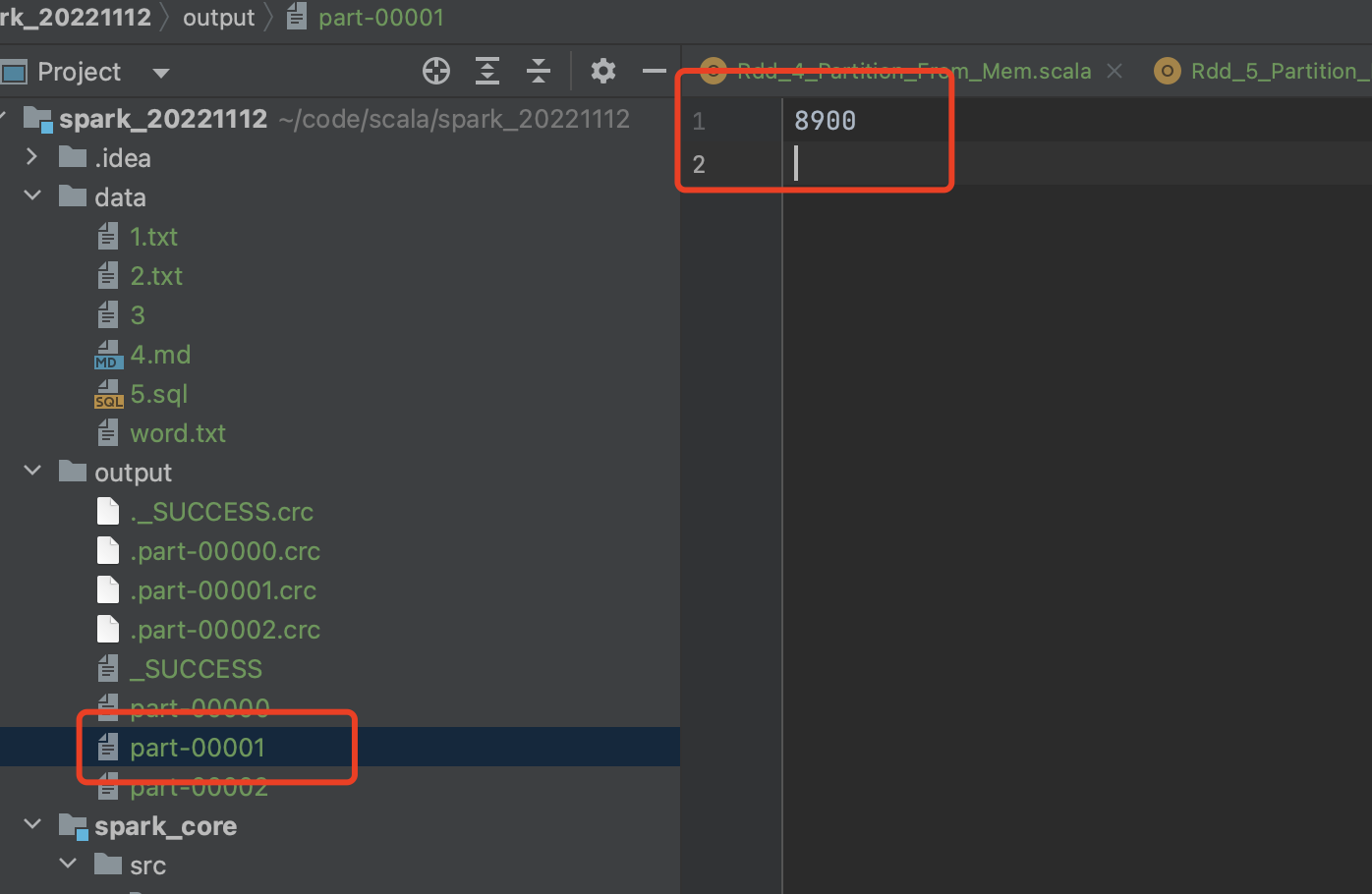
分区2预期[6, 12] => 但是上一个分区因为是偏移量到了某一行,某行就都被读走了,所以真实的
=> 8900
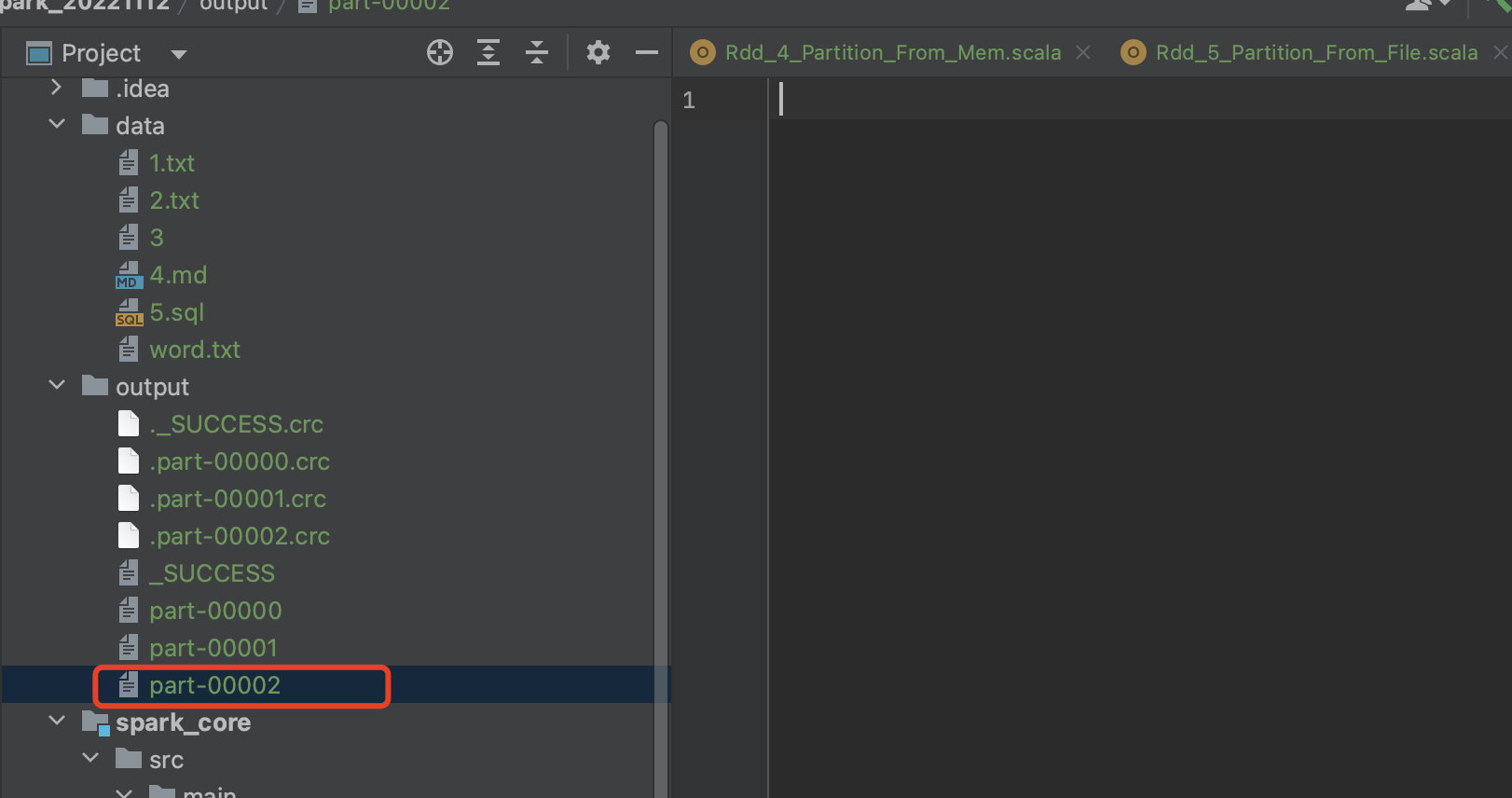
分区3预计[12, 13] => 已无数据可读
2.2.3 完整示例
package com.lzw.bigdata.spark.core.rdd_basic_usage_1
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
object Rdd_5_Partition_From_File {
def main(args: Array[String]): Unit = {
val sparkConfig: SparkConf = new SparkConf()
.setMaster("local[*]")
.setAppName("WordCount")
// .set("spark.default.parallelism", "5")
val sparkContext: SparkContext = new SparkContext(sparkConfig)
/*
1234\n
567\n
8900
分区数: 13 bytes / 2(这里2是minPartitions) = 6
13 bytes / 6 bytes = 2分区 + 剩余的1byte => 1/6 > 0.1 => 3分区
每个分区里面的数据, (hadoop按偏移量之后按行读取):
分区1预期 [0, 6] => 1234\n
567\n
分区2预期[6, 12] => 但是上一个分区因为是偏移量到了某一行,某行就都被读走了,所以真实的
=> 8900
分区3预计[12, 13] => 已无数据可读
*/
val rdd: RDD[String] = sparkContext.textFile("data/word.txt", 2)
rdd.saveAsTextFile("output")
sparkContext.stop()
}
}
spark (五) RDD的创建 & 分区的更多相关文章
- spark 中如何查看单个RDD分区的内容(创建分区,查看分区数)
spark 创建分区 val scores = Array(("Fred", 88), ("Fred", 95), ("Fred", 91) ...
- Spark核心RDD、什么是RDD、RDD的属性、创建RDD、RDD的依赖以及缓存、
1:什么是Spark的RDD??? RDD(Resilient Distributed Dataset)叫做弹性分布式数据集,是Spark中最基本的数据抽象,它代表一个不可变.可分区.里面的元素可并行 ...
- 【Spark】快来学习RDD的创建以及操作方式吧!
目录 RDD的创建 三种方式 从一个集合中创建 从文件中创建 从其他的RDD转化而来 RDD编程常用API 算子分类 Transformation 概述 帮助文档 常用Transformation表 ...
- Spark RDD概念学习系列之RDD的创建(六)
RDD的创建 两种方式来创建RDD: 1)由一个已经存在的Scala集合创建 2)由外部存储系统的数据集创建,包括本地文件系统,还有所有Hadoop支持的数据集,比如HDFS.Cassandra.H ...
- Spark核心——RDD
Spark中最核心的概念为RDD(Resilient Distributed DataSets)中文为:弹性分布式数据集,RDD为对分布式内存对象的 抽象它表示一个被分区不可变且能并行操作的数据集:R ...
- [Spark] Spark的RDD编程
本篇博客中的操作都在 ./bin/pyspark 中执行. RDD,即弹性分布式数据集(Resilient Distributed Dataset),是Spark对数据的核心抽象.RDD是分布式元素的 ...
- 关于Spark中RDD的设计的一些分析
RDD, Resilient Distributed Dataset,弹性分布式数据集, 是Spark的核心概念. 对于RDD的原理性的知识,可以参阅Resilient Distributed Dat ...
- 理解Spark的RDD
RDD是个抽象类,定义了诸如map().reduce()等方法,但实际上继承RDD的派生类一般只要实现两个方法: def getPartitions: Array[Partition] def com ...
- Spark源码分析之分区器的作用
最近因为手抖,在Spark中给自己挖了一个数据倾斜的坑.为了解决这个问题,顺便研究了下Spark分区器的原理,趁着周末加班总结一下~ 先说说数据倾斜 数据倾斜是指Spark中的RDD在计算的时候,每个 ...
- [转]Spark学习之路 (三)Spark之RDD
Spark学习之路 (三)Spark之RDD https://www.cnblogs.com/qingyunzong/p/8899715.html 目录 一.RDD的概述 1.1 什么是RDD? ...
随机推荐
- EDUSRC | 记录几张edusrc证书站挖掘
在web资产挖证书站是比较难的,尤其是没有账号密码进入后台或者统一的情况下,于是便转变思路,重点放在信息收集,收集偏远资产上. 一.XX大学 srping actuator未授权 茫茫c段,找到这么一 ...
- 2个月搞定计算机二级C语言——真题(5)解析
1. 前言 本篇我们讲解2个月搞定计算机二级C语言--真题 5 2. 程序填空题 2.1 题目要求 2.2 提供的代码 #include <stdio.h> double fun(int ...
- WebElement的常用属性和方法
WebElement是WebDriver.find_element()方法返回的一个对象,该对象用来描述Web上的一个元素,比如输入框,按钮等.本节介绍WebElement的常用属性和方法. 一.We ...
- 焕然一新!TinyVue 组件库 UI 大升级,更符合现代的审美!
你好,我是 Kagol,个人公众号:前端开源星球. 自从 TinyVue 组件库去年开源以来,一直有小伙伴反馈我们的 UI 不够美观,风格陈旧,不太满足现阶段审美. "TinyVue 给我的 ...
- StarRocks 物化视图刷新流程及原理
前段时间给 StarRocks 的物化视图新增了一个特性,那也是我第一次接触 StarRocks,因为完全不熟悉这个数据库,所以很多东西都是从头开始了解概念. 为了能顺利的新增这个特性(具体内容可以见 ...
- php xattr操作文件扩展属性再续
今天偶然发现自己电脑还有一个隐藏硬盘,500G的我平时没挂载,就没用到,然后这次就给它挂载了,然后发现读取文件,操作xattr都很慢,比之前速度慢10倍左右,猜测可能是固态硬盘和机械硬盘的差别关系.看 ...
- php操作sqlite3
距离上次接触sqlite3已经快一年了,去年这篇文章讲跟着菜鸟教程学python操作sqlite3,https://www.cnblogs.com/lizhaoyao/p/13717381.html ...
- npm安装包出现Invalid Version,npm list报错UNMET DEPENDENCY报错
执行 npm install 出现报错 2097 verbose stack TypeError: Invalid Version: 2097 verbose stack at new SemVer ...
- Hook框架之Frida
Frida是一款轻量级HOOK框架,可用于多平台上,例如android.windows.ios等. frida分为两部分,服务端运行在目标机上,通过注入进程的方式来实现劫持应用函数,另一部分运行 ...
- Redis之内存占用分析工具RDR
GitHub:https://github.com/xueqiu/rdr 场景:最近Redis爆满, 但是不清楚具体哪些键占用的空间较多, 是否有设置过期时间等情况 1.下载软件 windows:ht ...