本地AI搭建
搭建本地博客AI
环境
- Env:MacBook Pro M2
- Total memory:16GB
下载ollama
- 下载并按照提示安装启动ollama。
- 在浏览器中访问
http://localhost:11434,若返回"Ollama is running",则表示启动成功。
选择模型
选择embedding模型
查看性能测试
mteb展示了文本嵌入模型的性能测试结果。由于博客以中英文为主,因此在过滤语言时应该包含cmn、zho和eng(语言代码使用的是ISO 639-3标准)
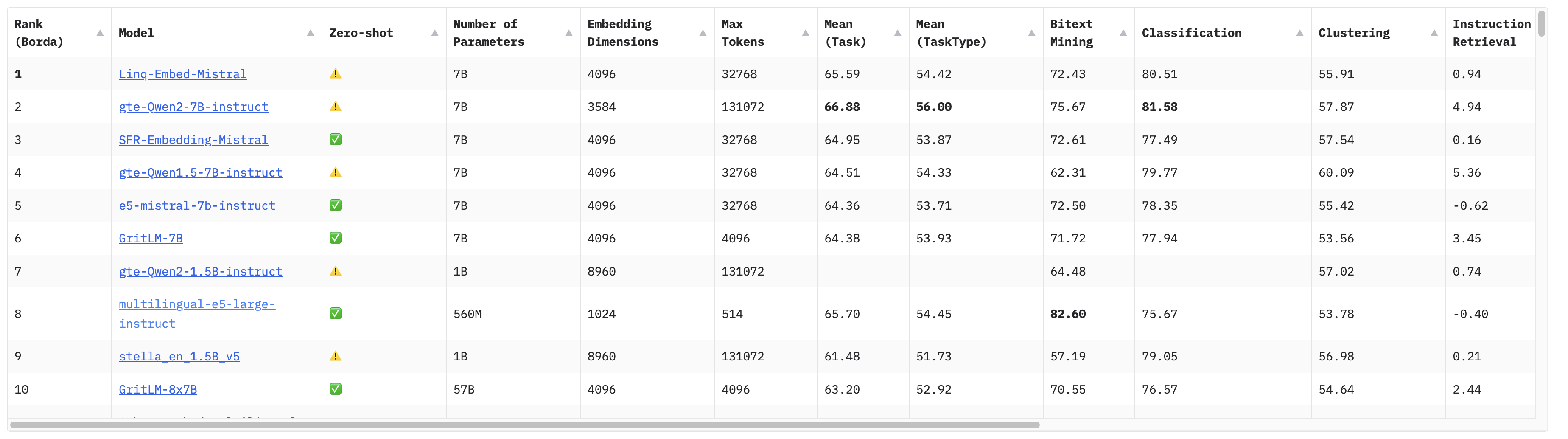
运行结果如下:
选择合适的嵌入模型(Embedder)
估算内存
在选择模型(不仅限嵌入模型)时,需要考虑模型占用的性能,通常参数越多,占用的内存也就越大。模型占用的内存估算公式如下:
\]
| Symbol | Description |
|---|---|
| M | 用千兆字节 (GB) 表示的 GPU 内存 |
| P | 模型中的参数数量。例如,一个 7B 模型有 7 亿参数。 |
| 4B | 4 字节,表示每个参数使用的字节数 |
| 32 | 4 字节中有 32 位 |
| Q | 加载模型时应使用的比特位数,例如 16 位、8 位或 4 位。 |
| 1.2 | 表示在 GPU 内存中加载额外内容的 20% 开销。 |
以上图中的第2名gte-Qwen2-1.5B-instruct为例,其参数数量(P)为1.78B,即17.8亿个参数,其模型应用的比特位数(Q)为F32,即32位,那么它占用的内存约为M = (1.78 ∗ 4) / (32 / 32) ∗ 1.2 ≈ 5.93GB
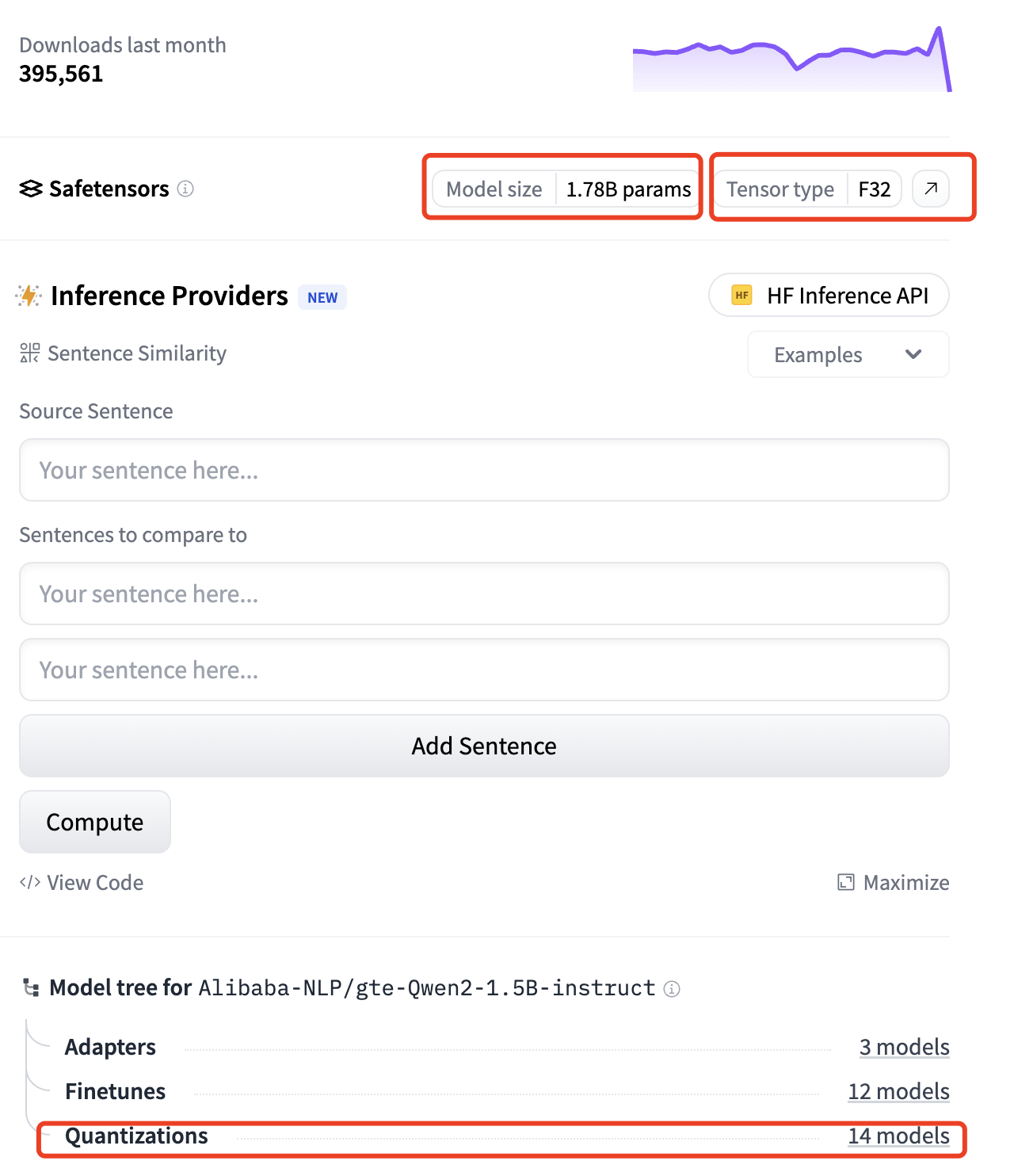
由于除嵌入模型外,我们还需要运行大模型(LLM),因此在总计16GB的内存上运行近6GB的嵌入模型是有些吃力的。那么是否有其他降低模型内存的方式呢?
答案是通过量化(Quantization)。
量化是一种降低内存占用的方式,通过将模型参数的精度从浮点数降低到更低的表达方式(如 8 位整数),显著降低了内存和计算需求,使模型能够更高效地部署在资源有限的设备。但降低精度可能会影响输出的准确性。通常来说,8bit的量化可以达到16bit的性能,但4bit的量化可能会显著影响模型性能。
如果想用2GB左右的内存运行该模型,那么量化应该设置为多少?
计算(1.78 ∗ 4) / (32 / Q) ∗ 1.2=2,求解Q约为7.5。
这里提供了一个模型内存计算工具,我们设置总内存(Custom Ran(GB))为10GB,系统预留内存(OS Overhead(GB))为8GB,这样留给嵌入模型的就只有2GB内存。量化级别(Quantization Level)为5-bit,上下文窗口(Context Window(Tokens))为2048,则该配置下,可以支持1.6B的模型,与预期大致相符:

选择模型
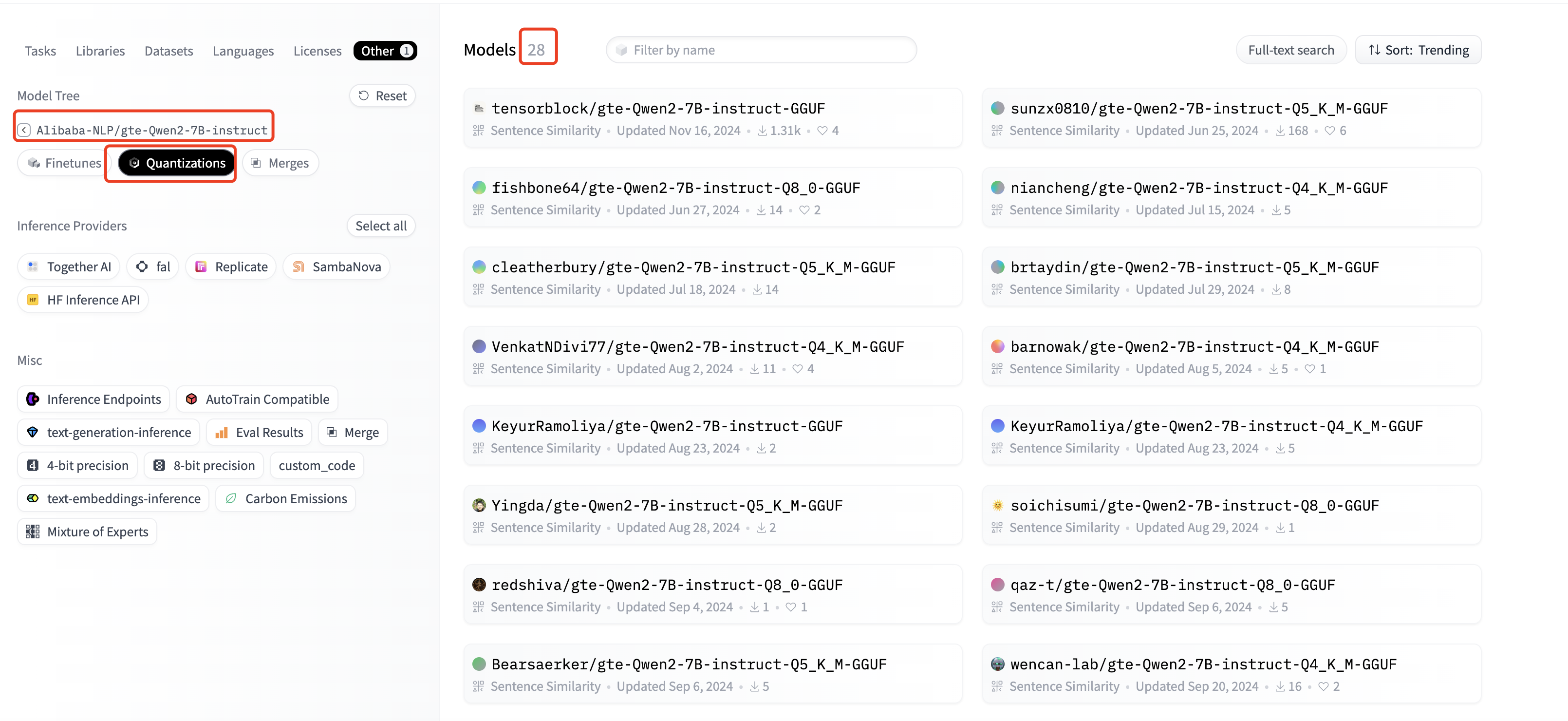
从上面截图中可以看到Alibaba-NLP/gte-Qwen2-7B-instruct模型有28个量化版本,点击进入这28个量化版本的浏览页面
点击进入第一个模型tensorblock/gte-Qwen2-7B-instruct-GGUF(下载量最多),在页面右侧选择Use this model->Ollama:

可以看到它有很多量化版本,那么该选择哪一个?
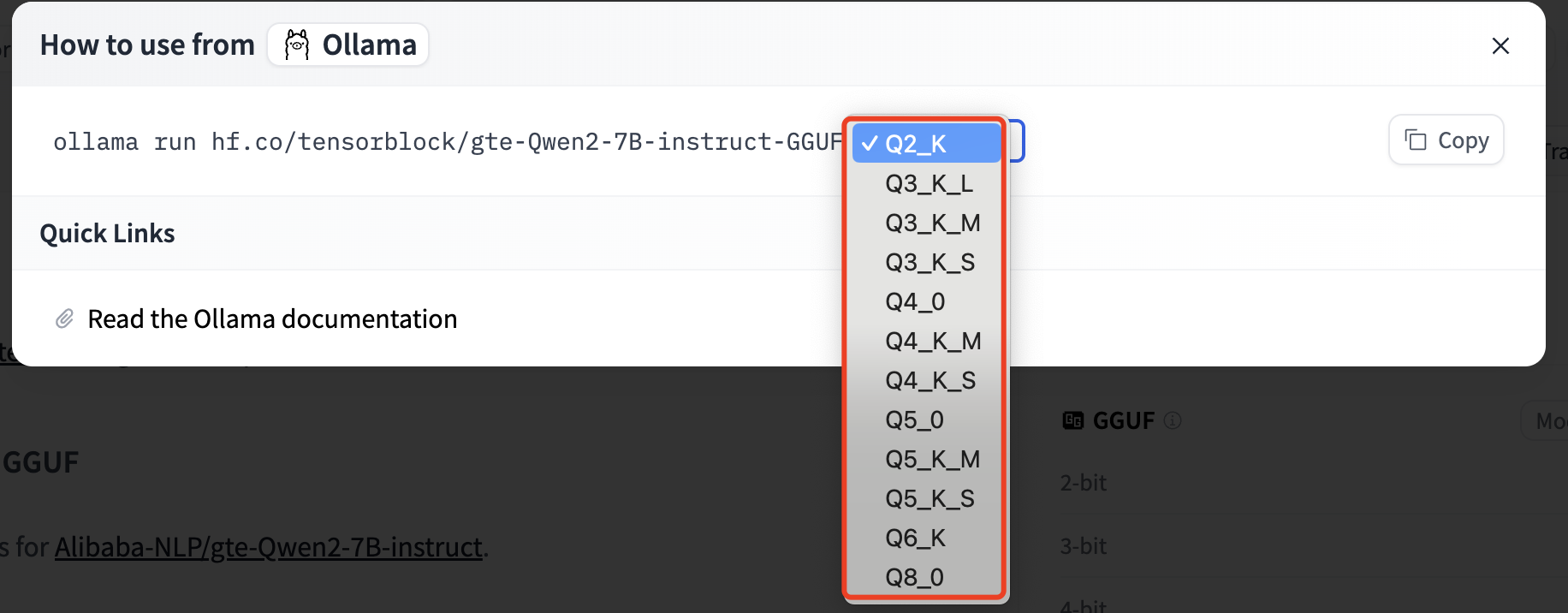
可以参考下面描述,推荐Q4_K_M和Q5_K_S,Q5_K_M,鉴于我们的量化级别不能大于7,因此可以采用推荐的Q5_K_M模型。
Allowed quantization types:
2 or Q4_0 : 3.50G, +0.2499 ppl @ 7B - small, very high quality loss - legacy, prefer using Q3_K_M
3 or Q4_1 : 3.90G, +0.1846 ppl @ 7B - small, substantial quality loss - legacy, prefer using Q3_K_L
8 or Q5_0 : 4.30G, +0.0796 ppl @ 7B - medium, balanced quality - legacy, prefer using Q4_K_M
9 or Q5_1 : 4.70G, +0.0415 ppl @ 7B - medium, low quality loss - legacy, prefer using Q5_K_M
10 or Q2_K : 2.67G, +0.8698 ppl @ 7B - smallest, extreme quality loss - not recommended
12 or Q3_K : alias for Q3_K_M
11 or Q3_K_S : 2.75G, +0.5505 ppl @ 7B - very small, very high quality loss
12 or Q3_K_M : 3.06G, +0.2437 ppl @ 7B - very small, very high quality loss
13 or Q3_K_L : 3.35G, +0.1803 ppl @ 7B - small, substantial quality loss
15 or Q4_K : alias for Q4_K_M
14 or Q4_K_S : 3.56G, +0.1149 ppl @ 7B - small, significant quality loss
15 or Q4_K_M : 3.80G, +0.0535 ppl @ 7B - medium, balanced quality - *recommended*
17 or Q5_K : alias for Q5_K_M
16 or Q5_K_S : 4.33G, +0.0353 ppl @ 7B - large, low quality loss - *recommended*
17 or Q5_K_M : 4.45G, +0.0142 ppl @ 7B - large, very low quality loss - *recommended*
18 or Q6_K : 5.15G, +0.0044 ppl @ 7B - very large, extremely low quality loss
7 or Q8_0 : 6.70G, +0.0004 ppl @ 7B - very large, extremely low quality loss - not recommended
1 or F16 : 13.00G @ 7B - extremely large, virtually no quality loss - not recommended
0 or F32 : 26.00G @ 7B - absolutely huge, lossless - not recommended
量化类型介绍
从上面可以看出不同的后缀(0、K、K_S、K_M、K_L)代表 不同的量化技术和优化策略。以下内容来自GPT:
Q5_0 vs Q5_K
Q5_0
- Q5_0 是最基础的 5-bit 量化方案,它使用 均匀量化(Uniform Quantization),但不包含任何额外的优化。
- 每个 block(通常 16 或 32 个权重)共享相同的缩放因子(scale)。
- 误差较大,在某些情况下可能导致 模型精度下降。
适用场景
- 适用于对精度要求不高的任务。
- 当设备计算资源有限但仍需要较好的推理速度时。
Q5_K
- Q5_K(K-Block Quantization)是一种更先进的 5-bit 量化方案,使用 块级(block-wise)非均匀量化(Non-Uniform Quantization) 以 降低量化误差。
- 相比 Q5_0,Q5_K 在同样的 5-bit 量化下能提供更好的数值精度,因此模型推理质量更高。
- Q5_K 进一步引入了优化策略,如动态缩放(dynamic scaling)或非均匀量化方法,使得量化误差小于 Q5_0。
适用场景
- 适用于 对精度有较高要求 的 LLM 任务,如 聊天机器人、代码生成、翻译 等。
- 适用于 存储受限 但仍希望保持较好精度的设备,如 GPU、CPU、移动端。
Q5_K 变体(Q5_K_S、Q5_K_M、Q5_K_L)
| 方案 | 说明 | 计算复杂度 | 精度 |
|---|---|---|---|
| Q5_K_S | "Small" 版本,更快但精度稍低 | 最低 | 较低 |
| Q5_K_M | "Medium" 版本,折中方案 | 适中 | 适中 |
| Q5_K_L | "Large" 版本,计算稍慢但精度高 | 较高 | 最佳 |
适用场景
- Q5_K_S:适用于 推理速度优先 的场景,例如 实时聊天机器人 或 低端设备。
- Q5_K_M:适用于 平衡精度和推理速度 的场景,是 最常用的 Q5_K 版本。
- Q5_K_L:适用于 对精度要求极高的 LLM 任务,如 科学计算、代码理解 等。
选择LLM模型
与嵌入模型类似,LLM模型也有自己的性能测试板块:open-llm-leaderboard,但该排行榜并未提供语言过滤功能,因此无法直接选择某个模型,还需要判断该模型是否支持中英文。
可以参考Open Chinese LLM Leaderboard。
也可以参考chinese-llm-benchmark,给出了中文大模型能力评测榜单。例如,我们想要找5B以下的小模型,可以参考该榜单,前3名为:
️在选择模型时,需要在huggingface上再次确认支持的语言,如上面的Llama-3.2-3B-Instruct模型,官方仅支持8种语言English, German, French, Italian, Portuguese, Hindi, Spanish, and Thai are officially supported,并没有中文!
这里我们选择的模型为qwen2.5-3b-instruct,根据公式,该模型大概占用的内存为2.55GB。
下载模型
️也可以直接在Ollama的模型库中直接查找下载。
下载LLM
ollama run hf.co/Qwen/Qwen2.5-3B-Instruct-GGUF:Q5_K_M
下载Embedder
ollama pull hf.co/second-state/gte-Qwen2-1.5B-instruct-GGUF:Q5_K_M
下载AnythingLLM
下载并安装anythingLLM
连接Ollama:分别在anythingLLM的
LLM和Embedder种选择Ollama,并将连接地址设置为正确的Ollama服务地址,Ollama的默认监听地址为127.0.0.1:11434(设置为http://localhost:11434好像有问题)。连接好后就可以自动加载模型:
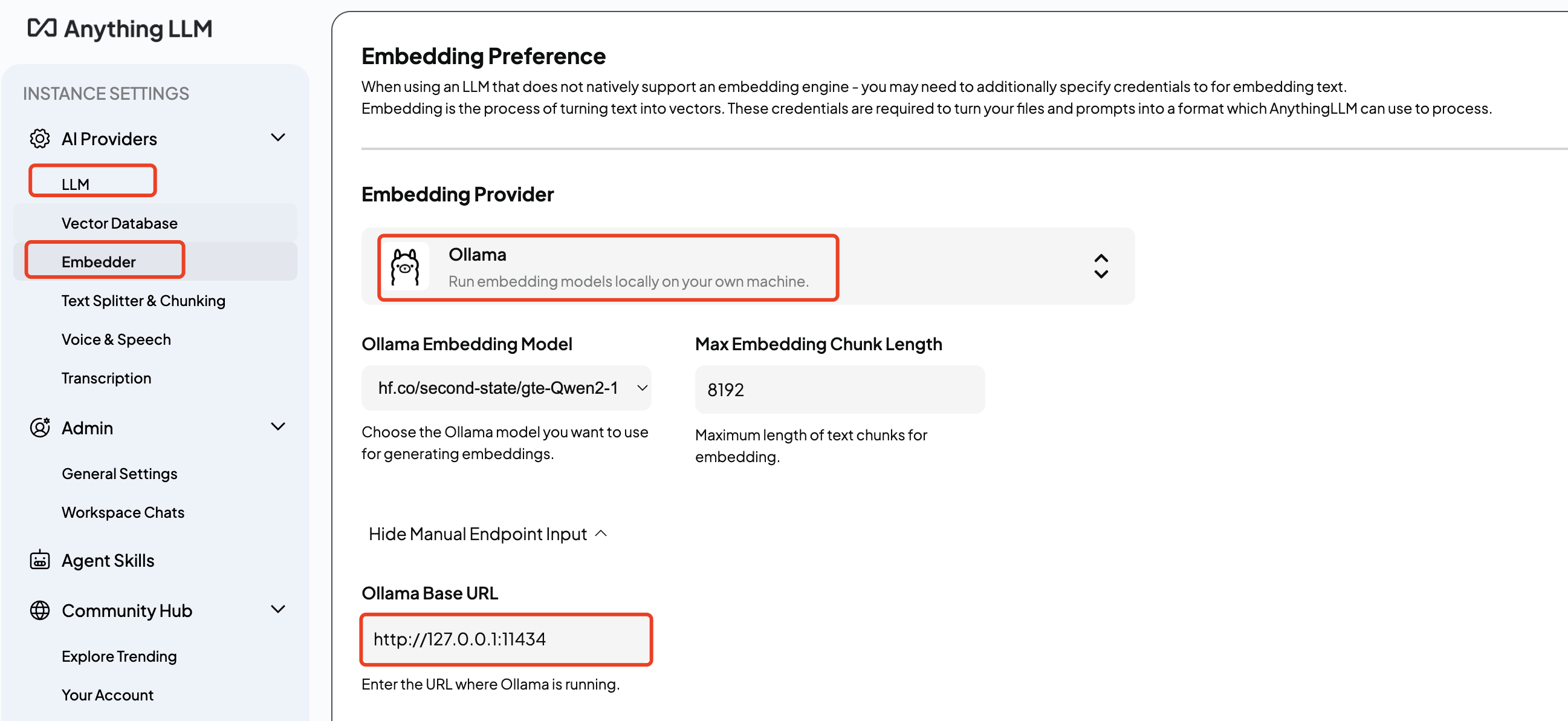
️ 使用Ollama时,anythingLLM无法区分模型是LLM还是embedder,因此都会进行加载,即在
LLM中出现嵌入模型,而在Embedder中出现LLM,需要手动选择正确的模型,将LLM设置为hf.co/Qwen/Qwen2.5-3B-Instruct-GGUF:Q5_K_M,将Embedder设置为hf.co/second-state/gte-Qwen2-1.5B-instruct-GGUF:Q5_K_M。官方有如下描述:
Heads up!
Ollama's
/modelsendpoint will show both LLMs and Embedding models in the dropdown selection. Please ensure you are using an embedding model for embedding.llama2 for example, is an LLM. Not an embedder.
配置向量数据库
这里就直接采用anythingLLM默认的本地数据库即可:
测试使用
简单测试一下模型是否生效:

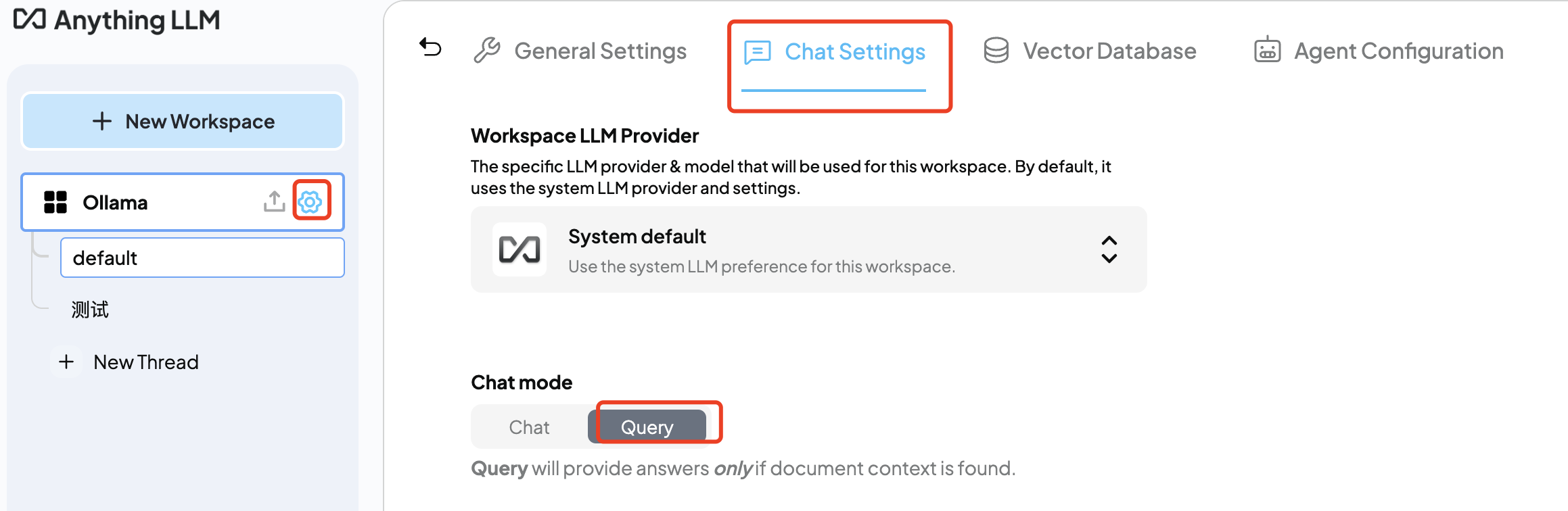
现在嵌入一个文档,看是否可以根据嵌入的文档进行回答。将Chat mode设置为Query,这样模型只会根据嵌入的文档进行回答:
上传一个文档,文档里面包含一个自定义的成语:"空让弄饭是一个成语,意思是有空一起做饭,形容一个人心情好":
测试结果如下:

如果用Chat模式,其结果如下:

Tips
Reset向量数据库
LLM没有使用自己的文档
官方给出了一些解决方式
Vector Database Settings > Search Preference中尝试使用
Accuracy Optimized,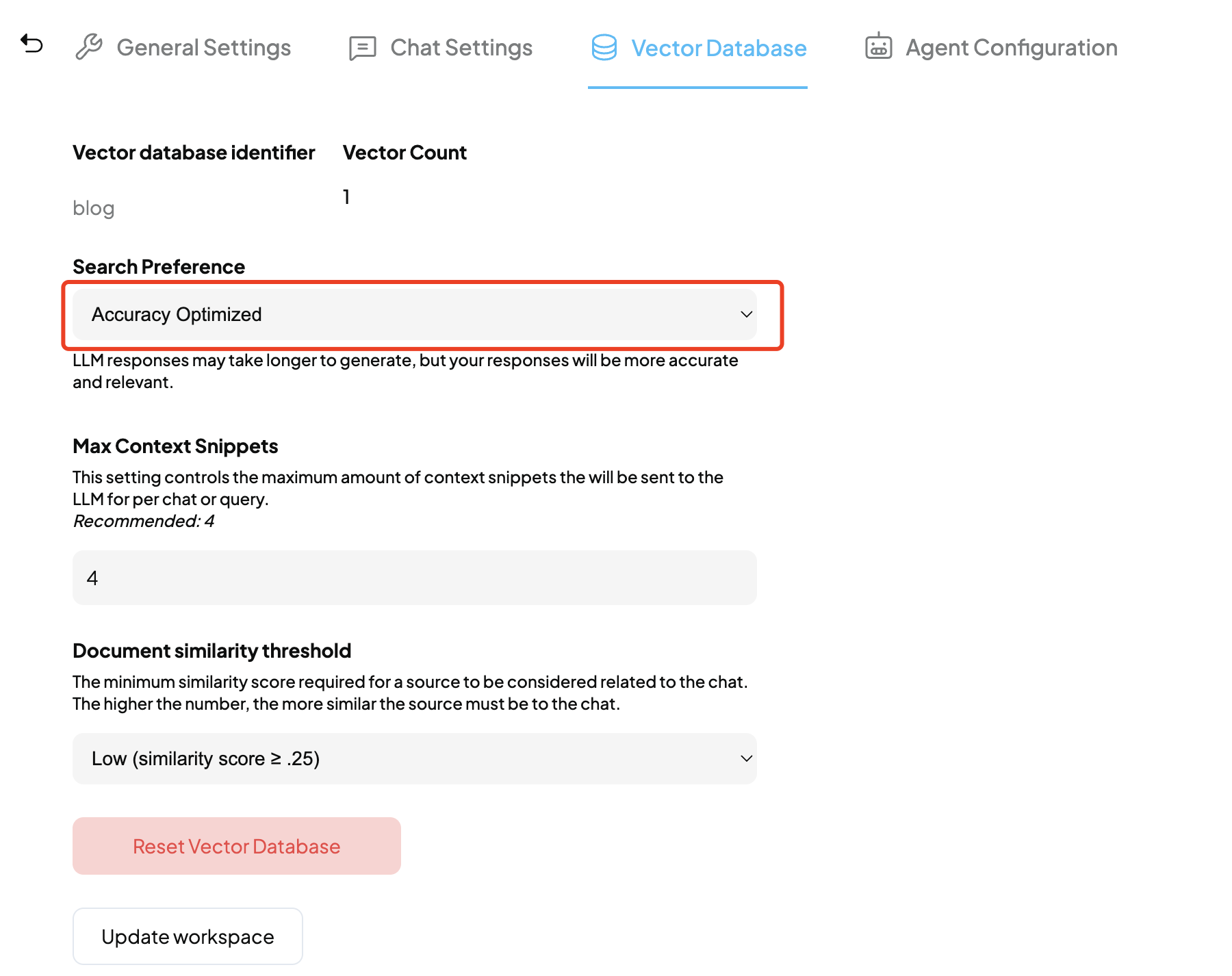
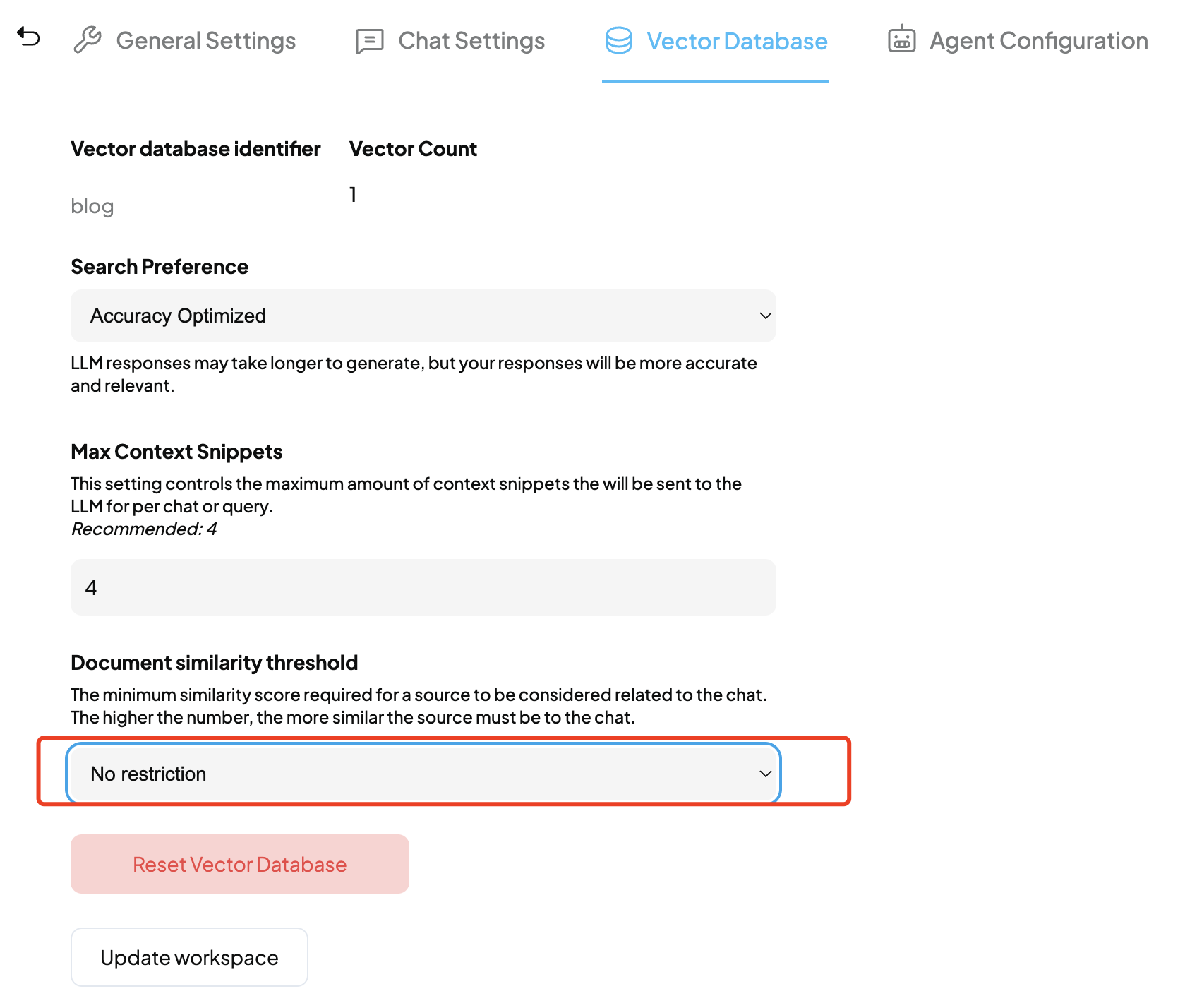
将Document similarity threshold设置为
No Restriction。该属性用于过滤掉可能与查询无关的低分向量数据,默认为20%:
AI回答逻辑混乱
可以适当将低模型的temperature值:Chat Settings > LLM Temperature
Ollama
日志中出现告警或错误
level=WARN source=runner.go:129 msg="truncating input prompt" limit=2048 prompt=2097 keep=0 new=2048
原因是Ollama默认使用2048的context window,解决方式是增加模型的num_ctx值,但这种方式比较耗时。
另一种方式是使用Modefile,下面修改嵌入模型hf.co/second-state/gte-Qwen2-1.5B-instruct-GGUF:Q5_K_M的num_ctx为8192:
cat Modelfile
# Modelfile
FROM hf.co/second-state/gte-Qwen2-1.5B-instruct-GGUF:Q5_K_M
PARAMETER num_ctx 8196
执行ollama create -f Modelfile gte-Qwen2-1.5B-instruct-GGUF:Q5_K_M将创建一个新的嵌入模型,在AnythingLLM中加载该模型即可。
️重新加载模型之前需要删除嵌入的文档,并reset 向量数据库。
命令行
Ollama的命令行有点像docker,常用的命令如下:
ollama server:启动一个ollama服务
ollama run:启动一个模型
ollama stop:停止一个模型
ollama ps:查看运行的模型
ollama pull:下载一个模型
ollama push:上传一个模型
ollama rm:删除一个模型
ollama list:查看下载的模型
ollama show:查看一个模型的信息
Debug
查看Ollama日志:cat ~/.ollama/logs/server.log
Ollama FAQ
参考
- Calculating GPU memory for serving LLMs
- 全民AI时代:手把手教你用Ollama & AnythingLLM搭建AI知识库,无需编程,跟着做就行!
- ollama支持的模型库
TODO
尝试一下其他大模型
本地AI搭建的更多相关文章
- Git本地服务器搭建及使用详解
Git本地服务器搭建及使用 Git是一款免费.开源的分布式版本控制系统.众所周知的Github便是基于Git的开源代码库以及版本控制系统,由于其远程托管服务仅对开源免费,所以搭建本地Git服务器也是个 ...
- 本地如何搭建IPv6环境测试你的APP
IPv6的简介 IPv4 和 IPv6的区别就是 IP 地址前者是 .(dot)分割,后者是以 :(冒号)分割的(更多详细信息自行搜索). PS:在使用 IPv6 的热点时候,记得手机开 飞行模式 哦 ...
- 基于本地iso 搭建的本地yum源 安装部署openldap
1,yum openldap-servers,openldap-clients 基于iso-cd1搭建的本地yum源(具体搭建参看ruige的repo本地快速搭建,在右边 找找看中输入repo key ...
- 【转】使用sinopia五步快速完成本地npm搭建
使用sinopia五步快速完成本地npm搭建 时间 2016-03-01 14:55:30 繁星UED 原文 http://ued.fanxing.com/shi-yong-sinopiawu-b ...
- 本地Git搭建并与Github连接
本地Git搭建并与Github连接 git 小结 1.ubuntu下安装git环境 ubuntu 16.04已经自带git ,可以通过下列命令进行安装与检测是否成功安装 sudo apt-get in ...
- Scala进阶之路-Spark本地模式搭建
Scala进阶之路-Spark本地模式搭建 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.Spark简介 1>.Spark的产生背景 传统式的Hadoop缺点主要有以下两 ...
- Sonar本地环境搭建
一个新项目准备上线提测了,为了在提测之前做一下代码走查,同时了解项目目前的质量情况,就在本地搭建了一套sonar环境.搭建的过程中遇到了很多问题,sonar官方已不再维护Eclipse的svn插件,所 ...
- 本地如何搭建IPv6环境测试你的APP(转)
IPv6的简介 IPv4 和 IPv6的区别就是 IP 地址前者是 .(dot)分割,后者是以 :(冒号)分割的(更多详细信息自行搜索). PS:在使用 IPv6 的热点时候,记得手机开 飞行模式 哦 ...
- Docker下kafka学习三部曲之二:本地环境搭建
在上一章< Docker下kafka学习,三部曲之一:极速体验kafka>中我们快速体验了kafka的消息分发和订阅功能,但是对环境搭建的印象仅仅是执行了几个命令和脚本,本章我们通过实战来 ...
- mac本地如何搭建IPv6环境测试你的APP
转自:http://www.cocoachina.com/ios/20160525/16431.html 投稿文章,作者:请勺子喝杯咖啡(简书) IPv6的简介 IPv4 和 IPv6的区别就是 IP ...
随机推荐
- mysqldump+binlog备份脚本
mysqldump是一种逻辑备份工具 , 可以对数据库进行全量备份 , 和binlog增量备份共同使用可以进行数据库备份 , 基于此写了一个备份的脚本 #!/bin/bash all_path=&qu ...
- 基于CPLD/FPGA的呼吸灯效果实现(附全部verilog源码)
一.功能介绍 此设计可以让你的FPGA板子上那颗LED具有呼吸效果,像智能手机上的呼吸灯一样.以下源码已上板验证通过,大家可直接使用. 二.呼吸灯Verilog源码 ps1. 带★号处可根据需要进行修 ...
- 零基础学习人工智能—Python—Pytorch学习(十一)
前言 本文主要介绍tensorboard的使用. tensorboard是一个可视化的,支持人工智能学习的一个工具. tensorboard的官方地址:https://www.tensorflow.o ...
- Vue CLI中views和components文件夹的区别
首先,src/components和文件夹src/views都包含Vue组件. 关键区别在于某些Vue组件充当路由视图. 在Vue中(通常是Vue Router)处理路由时,将定义路由以切换组件中使用 ...
- Java模拟Oracle函数MONTHS_BETWEEN注意事项
Java模拟Oracle函数MONTHS_BETWEEN注意事项 MONTHS_BETWEEN(DATE1, DATE2) 用来计算两个日期的月份差. 最近接到一个迁移需求,把Oracle SQL接口 ...
- 清理docker logs
1,docker ps找到id [root@mysql3 /]# docker ps CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES 1d8 ...
- django数据库反向迁移
目录 django数据库反向迁移 步骤一:连接MySQL 方式一:使用pymysql连接 方式二:使用mysqlclient连接 步骤二:迁移数据库 正向迁移(通过类创建表) 反向迁移(通过表创建类) ...
- Qt音视频开发45-视频传输TCP版
一.前言 做音视频开发,会遇到将音视频重新转发出去的需求,当然终极大法是推流转发,还有一些简单的场景是直接自定义协议将视频传出去就行,局域网的话速度还是不错的.很多年前就做过类似的项目,无非就是将本地 ...
- 启动redis失败Could not create server TCP listening socket 127.0.0.1:6379:bind:操作成功
问题: 启动redis失败Could not create server TCP listening socket 127.0.0.1:6379:bind:操作成功 解决方法: 在命令行提示符C:\P ...
- IM扫码登录技术专题(四):你真的了解二维码吗?刨根问底、一文掌握!
本文引用了ELab团队.腾讯大讲堂两个公众号分享的文章内容,引用内容见文末参考资料,感谢原作者的无私分享. 1.引言 对于市面上主流的IM来说,跟二维码有关的功能,比如扫码加好友.扫码登陆.扫码加群等 ...