Spark调优,性能优化
Spark调优,性能优化
相关博文地址:
Spark部分:调优
1.使用reduceByKey/aggregateByKey替代groupByKey
reduceByKey/aggregateByKey底层使用combinerByKey实现,会在map端进行局部聚合;groupByKey不会。
map端预聚合的算子: reduceByKey/aggregateByKey/combinerByKey
使用map-side预聚合的shuffle操作,尽量使用有combiner的shuffle类算子。
combiner概念:
在map端,每一个map task计算完毕后进行的局部聚合
combiner好处:
a) 降低shuffle write写磁盘的数据量。
b) 降低shuffle read拉取数据量的大小。
c) 降低reduce端聚合的次数。
2.使用mapPartitions替代普通map
mapPartitions类的算子,一次函数调用会处理一个partition所有的数据,而不是一次函数调用处理一条,性能相对来说会高一些。但是有的时候,使用mapPartitions会出现OOM(内存溢出)的问题。因为单次函数调用就要处理掉一个partition所有的数据,如果内存不够,垃圾回收时是无法回收掉太多对象的,很可能出现OOM异常。所以使用这类操作时要慎重!
3.使用foreachPartitions替代foreach
原理类似于“使用mapPartitions替代map”,也是一次函数调用处理一个partition的所有数据,而不是一次函数调用处理一条数据。在实践中发现,foreachPartitions类的算子,对性能的提升还是很有帮助的。比如在foreach函数中,将RDD中所有数据写MySQL,那么如果是普通的foreach算子,就会一条数据一条数据地写,每次函数调用可能就会创建一个数据库连接,此时就势必会频繁地创建和销毁数据库连接,性能是非常低下;但是如果用foreachPartitions算子一次性处理一个partition的数据,那么对于每个partition,只要创建一个数据库连接即可,然后执行批量插入操作,此时性能是比较高的。实践中发现,对于1万条左右的数据量写MySQL,性能可以提升30%以上。
foreach 以一条记录为单位来遍历 RDD
foreachPartition 以分区为单位遍历 RDD
foreach 和 foreachPartition 都是 actions 算子
map 和 mapPartition 可以与它们做类比,但 map 和 mapPartitions 是 transformations 算子
4.使用filter之后进行coalesce操作
通常对一个RDD执行filter算子过滤掉RDD中较多数据后(比如30%以上的数据),建议使用coalesce算子,手动减少RDD的partition数量,将RDD中的数据压缩到更少的partition中去。因为filter之后,RDD的每个partition中都会有很多数据被过滤掉,此时如果照常进行后续的计算,其实每个task处理的partition中的数据量并不是很多,有一点资源浪费,而且此时处理的task越多,可能速度反而越慢。因此用coalesce减少partition数量,将RDD中的数据压缩到更少的partition之后,只要使用更少的task即可处理完所有的partition。在某些场景下,对于性能的提升会有一定的帮助。
5.使用repartitionAndSortWithinPartitions替代repartition与sort类操作
repartitionAndSortWithinPartitions是Spark官网推荐的一个算子,官方建议,如果需要在repartition重分区之后,还要进行排序,建议直接使用repartitionAndSortWithinPartitions算子。因为该算子可以一边进行重分区的shuffle操作,一边进行排序。shuffle与sort两个操作同时进行,比先shuffle再sort来说,性能可能是要高的。
6.使用broadcast使各task共享同一Executor的集合替代算子函数中各task传送一份集合
在算子函数中使用到外部变量时,默认情况下,Spark会将该变量复制多个副本,通过网络传输到task中,此时每个task都有一个变量副本。如果变量本身比较大的话(比如100M,甚至1G),那么大量的变量副本在网络中传输的性能开销,以及在各个节点的Executor中占用过多内存导致的频繁GC,都会极大地影响性能。
因此对于上述情况,如果使用的外部变量比较大,建议使用Spark的广播功能,对该变量进行广播。广播后的变量,会保证每个Executor的内存中,只驻留一份变量副本,而Executor中的task执行时共享该Executor中的那份变量副本。这样的话,可以大大减少变量副本的数量,从而减少网络传输的性能开销,并减少对Executor内存的占用开销,降低GC的频率。
7.使用相同分区方式的join可以避免Shuffle
Spark知道当前面的转换已经根据相同的partitioner分区器分好区的时候如何避免shuffle。如果RDD有相同数目的分区,join操作不需要额外的shuffle操作。因为RDD是相同分区的,rdd1中任何一个分区的key集合都只能出现在rdd2中的单个分区中。因此rdd3中任何一个输出分区的内容仅仅依赖rdd1和rdd2中的单个分区,第三次shuffle就没有必要了。
rdd1 = someRdd.reduceByKey(...)
rdd2 = someOtherRdd.reduceByKey(...)
rdd3 = rdd1.join(rdd2)
那如果rdd1和rdd2使用不同的分区器,或者使用默认的hash分区器但配置不同的分区数呢?那样的话,仅仅只有一个rdd(较少分区的RDD)需要重新shuffle后再join。
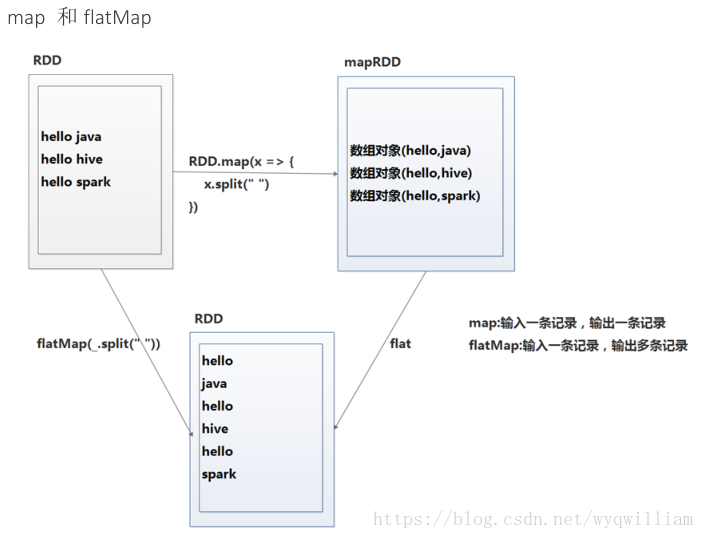
8.map和flatMap选择
def map[U](f: (T) ⇒ U)(implicit arg0: ClassTag[U]): RDD[U] //Return a new RDD by applying a function to all elements of this RDD.
def flatMap[U](f: (T) ⇒ TraversableOnce[U])(implicit arg0: ClassTag[U]): RDD[U] //Return a new RDD by first applying a function to all elements of this RDD, and then flattening the results.
9.spark性能优化----缓存清除
。其中去除重复计算是非常重要的。一般操作调用cache/persist,来缓存中间结果,避免重复计算。其中cache是persist的一个特列(cache相当于persist())。persist拥以下几个级别的缓存:
NONE 默认配置(不缓存)
DISK_ONLY 数据缓存到磁盘,特点读写特别慢,内存占用比较少
DISK_ONLY_2 数据缓存到磁盘两份,特点读写比较慢(比DISK_ONLY读写快,稳定性好)
MEMORY_ONLY 数据缓存到内存和cache()功能之一,读写最快但是内存消耗比较大
MEMORY_ONLY_2 数据缓存到内存,并且缓存两份,特点读写速度快内存消耗很大,稳定性比较好,适用于集群不稳定,缓存的数据计算过程比较复杂的情况
MEMORY_ONLY_SER 数据缓存到内存并序列化,一般可以配合kyro一起使用,读写过程需要序列化和反序列化,读写速度比Memory_only慢,但是数列化后的数据占用内存比较少
MEMORY_ONLY_SER_2 数据序列化后存两份到内存,读写过程同上,特点内存占用量较大,适用于不太稳定的集群
MEMORY_AND_DISK 数据缓存到内存,内存不够溢写到磁盘,一般情况这个使用的比较多一点,是读写性能和数据空间的平衡点
MEMORY_AND_DISK_2 数据缓存两份到内存,内存不够溢写到磁盘,一般情况这个使用的比较多一点,是读写性能和数据空间的平衡点
MEMORY_AND_DISK_SER 数据序列化后缓存到内存,内存不够溢写到磁盘
MEMORY_AND_DISK_SER_2数据序列化后缓存2份到内存,内存不够溢写到磁盘
OFF_HEAP 使用堆外内存缓存数据可以配合tachyon一起使用
spark框架还提供另外一个api供开发者调sc.getPersistentRDDs,这个方法返回所有这在被缓存的RDD数据,开发者可以根据自己需求去除掉不需要的缓存,以下是实现方法:
def unpersistUnuse(rddString: Set[String], sc: SparkContext) = {
var persistRdds = sc.getPersistentRDDs
persistRdds.foreach(truple => {
val xx = truple._2.toString()
val ddd = rddString
if (!rddString.contains(truple._2.toString())) {
truple._2.unpersist()
}
})
}
Spark调优,性能优化的更多相关文章
- Spark调优_性能调优(一)
总结一下spark的调优方案--性能调优: 一.调节并行度 1.性能上的调优主要注重一下几点: Excutor的数量 每个Excutor所分配的CPU的数量 每个Excutor所能分配的内存量 Dri ...
- Kafka性能调优 - Kafka优化的方法
今天,我们将讨论Kafka Performance Tuning.在本文“Kafka性能调优”中,我们将描述在设置集群配置时需要注意的配置.此外,我们将讨论Tuning Kafka Producers ...
- 【Spark学习】Apache Spark调优
Spark版本:1.1.0 本文系以开源中国社区的译文为基础,结合官方文档翻译修订而来,转载请注明以下链接: http://www.cnblogs.com/zhangningbo/p/4117981. ...
- 【Spark调优】Broadcast广播变量
[业务场景] 在Spark的统计开发过程中,肯定会遇到类似小维表join大业务表的场景,或者需要在算子函数中使用外部变量的场景(尤其是大变量,比如100M以上的大集合),那么此时应该使用Spark的广 ...
- 【Spark调优】Kryo序列化
[Java序列化与反序列化] Java序列化是指把Java对象转换为字节序列的过程:而Java反序列化是指把字节序列恢复为Java对象的过程.序列化使用场景:1.数据的持久化,通过序列化可以把数据永久 ...
- 【翻译】Spark 调优 (Tuning Spark) 中文版
由于Spark自己的调优guidance已经覆盖了很多很有价值的点,因此这里直接翻译一份过来.也作为一个积累. Spark 调优 (Tuning Spark) 由于大多数Spark计算任务是在内存中运 ...
- 【Spark调优】Shuffle原理理解与参数调优
[生产实践经验] 生产实践中的切身体会是:影响Spark性能的大BOSS就是shuffle,抓住并解决shuffle这个主要原因,事半功倍. [Shuffle原理学习笔记] 1.未经优化的HashSh ...
- Spark 调优(转)
Spark 调优 返回原文英文原文:Tuning Spark Because of the in-memory nature of most Spark computations, Spark pro ...
- Spark调优秘诀——超详细
版权声明:本文为博主原创文章,转载请注明出处. Spark调优秘诀 1.诊断内存的消耗 在Spark应用程序中,内存都消耗在哪了? 1.每个Java对象都有一个包含该对象元数据的对象头,其大小是16个 ...
随机推荐
- JavaDailyReports10_09
***************************** 1.2.2 布局管理器 BorderLayout 把容器的布局分为东西南北中五个部位,默认是中间,平铺占满! 1 package awt; ...
- 计算-服务器最大并发量-http协议请求-以webSphere服务器为例-考虑线程池
请求的处理流程 广域网上有大量的并发用户同时访问Web服务器,Web服务器传递请求给应用服务器(Web容器),Web容器传递请求给EJB容器,然后EJB容器发送数据库连接请求给数据库. 请求的处理流程 ...
- Javascript函数闭包及案例详解
什么情况下会形成闭包,什么是闭包 闭包(Closure):函数和其周围的状态(词法环境)的引用捆绑在一起形成闭包 可以在另一个作用域中调用一个函数的内部函数并访问到该函数的作用域中的成员 下面来看一个 ...
- Java基础--接口回调(接口 对象名 = new 类名)理解
接口 对象名1 = new 类名和类名 对象名2 = new 类名的区别是什么? 实例 /** *Person.java 接口 */ public interface Person { void in ...
- spark知识点_datasources
来自官网DataFrames.DataSets.SQL,即sparkSQL模块. 通过dataframe接口,sparkSQL支持多种数据源的操作.可以把dataframe注册为临时视图,也可以通过关 ...
- 利用GPU实现大规模动画角色的渲染(转)
原文: https://www.cnblogs.com/murongxiaopifu/p/7250772.html 利用GPU实现大规模动画角色的渲染 0x00 前言 我想很多开发游戏的小伙伴都希望自 ...
- 【RAC】运行root.sh的时候报错root.sh Oracle CRS stack is already configured and will be running under init(1M)
环境:oracle10g 系统:CentOS6.4 开始的时候,在节点1上运行root.sh发现出现90s 的时候hang住了,结束掉,结局完事后,再次运行root.sh报错 WARNING: dir ...
- kubernets之pod的删除方式
一 删除单个pod 1 删除指定命名空间的指定名称的pod k delete po kubia-manual -n defaultpod "kubia-manual" delet ...
- SAP表的锁定与解锁
表的锁定模式有三种模式. lock mode有三种模式:分别是S,E,X.含义如下: S (Shared lock, read lock) E (Exclusive lock, wri ...
- [从源码学设计]蚂蚁金服SOFARegistry之延迟操作
[从源码学设计]蚂蚁金服SOFARegistry之延迟操作 0x00 摘要 SOFARegistry 是蚂蚁金服开源的一个生产级.高时效.高可用的服务注册中心. 本系列文章重点在于分析设计和架构,即利 ...