最短路-朴素版Dijkstra算法&堆优化版的Dijkstra
朴素版Dijkstra
目标
找到从一个点到其他点的最短距离
思路
①初始化距离dist数组,将起点dist距离设为0,其他点的距离设为无穷(就是很大的值)
②for循环遍历n次,每层循环里找出不在S集合中,且距离最近的点,然后用该点去更新其他点的距离,算法复杂度是O(n2),适合稠密图
实例练习
题目:https://www.acwing.com/problem/content/851/
代码:
#include<bits/stdc++.h>
using namespace std;
const int maxn=550; int n,m;
int g[maxn][maxn];
int dist[maxn];
bool st[maxn]; int Dijkstra()
{
int i,j;
//初始化距离为无穷大
memset(dist,0x3f,sizeof(dist));
//起点距离为1
dist[1]=0;
//循环n次,就可以将所有点都加入到集合里
for(i=1;i<=n;i++)
{
//用来记录,不在S集合中,距离最近的点
int t=-1;
for(j=1;j<=n;j++)
{
if(!st[j]&&(t==-1||dist[t]>dist[j]))
t=j;
}
//加入到集合S中
st[t]=true;
//更新新加入的点,到其他点的距离
for(j=1;j<=n;j++)
{
dist[j]=min(dist[j],dist[t]+g[t][j]);
} }
//如果还是无穷大,代表从起点走不到n
if(dist[n]==0x3f3f3f3f)
return -1;
else
return dist[n];
} int main()
{
int i,j;
cin>>n>>m;
//初始化权值
memset(g,0x3f,sizeof(g));
while(m--)
{
int x,y,z;
cin>>x>>y>>z;
//因为会有重边存在,只保留最小的即可
g[x][y]=min(g[x][y],z);
}
int ans=Dijkstra();
cout<<ans;
return 0;
}
如果是稀疏图,点的个数比较多,1e5个点,用O(n2)就会爆掉,因此我们引入堆优化版的Dijstra
堆优化版的Dijkstra
原理
将找寻不在S中,且距离最近的点的方法进行优化,采用堆(优先队列的方法),时间复杂度为mlog(n),就可以解决
思路
对于稀疏图,我们可以用邻接表结构来进行存储
先上数据,如下。
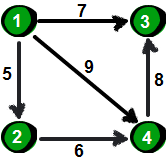
4 5
1 4 9
4 3 8
1 2 5
2 4 6
1 3 7
第一行两个整数n m。n表示顶点个数(顶点编号为1~n),m表示边的条数。接下来m行表示,每行有3个数x y z,表示顶点x到顶点y的边的权值为z。下图就是一种使用链表来实现邻接表的方法。
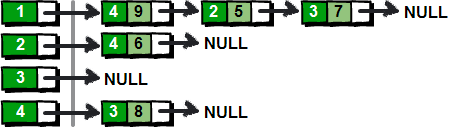
上面这种实现方法为图中的每一个顶点(左边部分)都建立了一个单链表(右边部分)。这样我们就可以通过遍历每个顶点的链表,从而得到该顶点所有的边了。使用链表来实现邻接表对于痛恨指针的的朋友来说,这简直就是噩梦。
这里我将为大家介绍另一种使用数组来实现的邻接表,这是一种在实际应用中非常容易实现的方法。这种方法为每个顶点i(i从1~n)也都保存了一个类似“链表”的东西,里面保存的是从顶点i出发的所有的边,具体如下。
首先我们按照读入的顺序为每一条边进行编号(1~m)。比如第一条边“1 4 9”的编号就是1,“1 3 7”这条边的编号是5。
这里用u、v和w三个数组用来记录每条边的具体信息,即u[i]、v[i]和w[i]表示第i条边是从第u[i]号顶点到v[i]号顶点(u[i]àv[i]),且权值为w[i]。

再用一个first数组来存储每个顶点其中一条边的编号。以便待会我们来枚举每个顶点所有的边(你可能会问:存储其中一条边的编号就可以了?不可能吧,每个顶点都需要存储其所有边的编号才行吧!甭着急,继续往下看)。比如1号顶点有一条边是 “1 4 9”(该条边的编号是1),那么就将first[1]的值设为1。如果某个顶点i没有以该顶点为起始点的边,则将first[i]的值设为-1。现在我们来看看具体如何操作,初始状态如下。
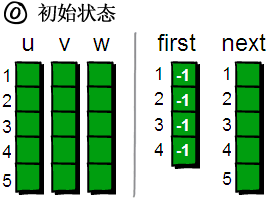
咦?上图中怎么多了一个next数组,有什么作用呢?不着急,待会再解释,现在先读入第一条边“1 4 9”。
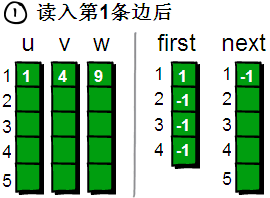
读入第1条边(1 4 9),将这条边的信息存储到u[1]、v[1]和w[1]中。同时为这条边赋予一个编号,因为这条边是最先读入的,存储在u、v和w数组下标为1的单元格中,因此编号就是1。这条边的起始点是1号顶点,因此将first[1]的值设为1。
另外这条“编号为1的边”是以1号顶点(即u[1])为起始点的第一条边,所以要将next[1]的值设为-1。也就是说,如果当前这条“编号为i的边”,是我们发现的以u[i]为起始点的第一条边,就将next[i]的值设为-1(貌似的这个next数组很神秘啊⊙_⊙)。
读入第2条边(4 3 8),将这条边的信息存储到u[2]、v[2]和w[2]中,这条边的编号为2。这条边的起始顶点是4号顶点,因此将first[4]的值设为2。另外这条“编号为2的边”是我们发现以4号顶点为起始点的第一条边,所以将next[2]的值设为-1。
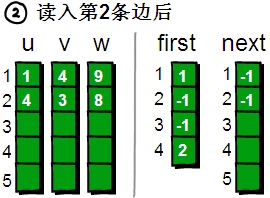
读入第3条边(1 2 5),将这条边的信息存储到u[3]、v[3]和w[3]中,这条边的编号为3,起始顶点是1号顶点。我们发现1号顶点已经有一条“编号为1 的边”了,如果此时将first[1]的值设为3,那“编号为1的边”岂不是就丢失了?我有办法,此时只需将next[3]的值设为1即可。现在你知道next数组是用来做什么的吧。next[i]存储的是“编号为i的边”的“前一条边”的编号。(注:next数组的大小由边的数目决定,first数组的大小由顶点的个数来决定)
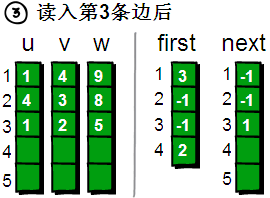
读入第4条边(2 4 6),将这条边的信息存储到u[4]、v[4]和w[4]中,这条边的编号为4,起始顶点是2号顶点,因此将first[2]的值设为4。另外这条“编号为4的边”是我们发现以2号顶点为起始点的第一条边,所以将next[4]的值设为-1。
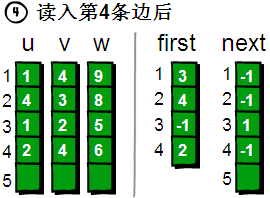
读入第5条边(1 3 7),将这条边的信息存储到u[5]、v[5]和w[5]中,这条边的编号为5,起始顶点又是1号顶点。此时需要将first[1]的值设为5,并将next[5]的值改为3(编号为5的边的前一条边的编号为3)。
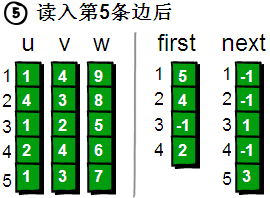
此时,如果我们想遍历1号顶点的每一条边就很简单了。1号顶点的其中一条边的编号存储在first[1]中。其余的边则可以通过next数组寻找到。请看下图。
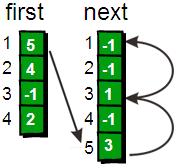
细心的同学会发现,此时遍历边某个顶点边的时候的遍历顺序正好与读入时候的顺序相反。因为在为每个顶点插入边的时候都直接插入“链表”的首部而不是尾部。不过这并不会产生任何问题,这正是这种方法的其妙之处。
实例练习
题目:https://www.acwing.com/problem/content/description/852/
代码
#include<bits/stdc++.h>
using namespace std;
const int maxn=2e5+10;
typedef long long ll;
ll n,m;
typedef pair<int, int> PII;
int h[maxn],e[maxn],w[maxn],ne[maxn],idx;
int dist[maxn];
bool st[maxn]; void add(int x,int y,int c)
{
//权值记录
w[idx]=c;
//终点边记录
e[idx]=y;
//存储编号为idx的边的前一条边的编号
ne[idx]=h[x];
//代表以x为起点的边的编号,这个值会发生变化
h[x]=idx++;
} ll Dijkstra()
{
ll i,j;
memset(dist,0x3f,sizeof(dist));
dist[1]=0;
//寻找出非S集合外,距离最小的顶点,并将其加入,更新他到其他边的最短距离
priority_queue<PII,vector<PII>,greater<PII>> heap;
//push的集合中:距离,顶点(这里为起点1)
//这里为啥距离在前,因为会先按第一个值排序,我们要找出距离最小的边
heap.push({0,1});
while(heap.size())
{
auto t=heap.top();
heap.pop();
//获得顶点和他到起点的距离
int ver=t.second,distance=t.first;
//判断是否加入集合里
if(st[ver])
continue;
//加入到集合
st[ver]=true;
//遍历他所连接的所有边
for(int i=h[ver];i!=-1;i=ne[i])
{
//跟ver连接的终点j
int j=e[i];
//判断j点离原点的距离 > ver点离原点的距离 + ver和j点的距离,哪个近
if(dist[j]>dist[ver]+w[i])
{
//更新距离
dist[j]=dist[ver]+w[i];
//将更新后的距离,和对应的终点j,加入到里面
heap.push({dist[j],j});
}
}
}
//如果说原点到终点n的距离还是无穷,则代表到达不了
if(dist[n]==0x3f3f3f3f)
return -1;
else
return dist[n];
} int main()
{
ll i,j;
cin>>n>>m;
//初始化h数组为-1,目的是为ne数组赋值
memset(h,-1,sizeof(h));
while(m--)
{
int x,y,z;
cin>>x>>y>>z;
//加边
add(x,y,z);
}
//堆优化版的Dijkstra
ll ans=Dijkstra();
cout<<ans;
return 0;
}
最短路-朴素版Dijkstra算法&堆优化版的Dijkstra的更多相关文章
- 最短路模板(Dijkstra & Dijkstra算法+堆优化 & bellman_ford & 单源最短路SPFA)
关于几个的区别和联系:http://www.cnblogs.com/zswbky/p/5432353.html d.每组的第一行是三个整数T,S和D,表示有T条路,和草儿家相邻的城市的有S个(草儿家到 ...
- Dijkstra算法堆优化详解
DIJ算法的堆优化 DIJ算法的时间复杂度是\(O(n^2)\)的,在一些题目中,这个复杂度显然不满足要求.所以我们需要继续探讨DIJ算法的优化方式. 堆优化的原理 堆优化,顾名思义,就是用堆进行优化 ...
- Dijkstra算法堆优化
转自 https://blog.csdn.net/qq_41754350/article/details/83210517 再求单源最短路径时,算法有优劣之分,个人认为在时间方面 朴素dijkstra ...
- Dijkstra算法堆优化(vector建图)
#include<iostream> #include<algorithm> #include<string.h> #include<stdio.h> ...
- 单源最短路——朴素Dijkstra&堆优化版
朴素Dijkstra 是一种基于贪心的算法. 稠密图使用二维数组存储点和边,稀疏图使用邻接表存储点和边. 算法步骤: 1.将图上的初始点看作一个集合S,其它点看作另一个集合 2.根据初始点,求出其它点 ...
- 朴素版和堆优化版dijkstra和朴素版prim算法比较
1.dijkstra 时间复杂度:O(n^2) n次迭代,每次找到距离集合S最短的点 每次迭代要用找到的点t来更新其他点到S的最短距离. #include<iostream> #inclu ...
- 洛谷P3371单源最短路径Dijkstra堆优化版及优先队列杂谈
其实堆优化版极其的简单,只要知道之前的Dijkstra怎么做,那么堆优化版就完全没有问题了. 在做之前,我们要先学会优先队列,来完成堆的任务,下面盘点了几种堆的表示方式. priority_queue ...
- POJ 3635 - Full Tank? - [最短路变形][手写二叉堆优化Dijkstra][配对堆优化Dijkstra]
题目链接:http://poj.org/problem?id=3635 题意题解等均参考:POJ 3635 - Full Tank? - [最短路变形][优先队列优化Dijkstra]. 一些口胡: ...
- Codeforces 843D (Dijkstra算法的优化,动态最短路)
题面 (http://codeforces.com/problemset/problem/843/D) 题目大意: 给定一张带权无向图,有q次操作 操作有两种 1 v 询问1到v的最短路 2 c 将边 ...
随机推荐
- Python 爬虫系列
爬虫简介 网络爬虫 爬虫指在使用程序模拟浏览器向服务端发出网络请求,以便获取服务端返回的内容. 但这些内容可能涉及到一些机密信息,所以爬虫领域目前来讲是属于灰色领域,切勿违法犯罪. 爬虫本身作为一门技 ...
- centos7下mysql安装与卸载
彻底卸载mysql 一.chak 是否有安装mysql a) rpm -qa | grep -i mysql // 查看命令1 b) yum list install mysql* ...
- java左移右移运算符详解
在阅读源码的过程中,经常会看到这些符号<< ,>>,>>>,这些符号在Java中叫移位运算符,在写代码的过程中,虽然我们基本上不会去写这些符号,但需要明白这些 ...
- CAP理论和BASE理论及数据库的ACID中关于一致性及不同点的思考
CAP定理又被称作是布鲁尔定理,是加州大学伯克利分销计算机科学家里克在2000年提出,是分布式理论基础. CAP:是分布式系统的理论基础 [一致性 可用性 分区容错性] BASE理论是对CAP中 ...
- LeapMotion控制器 java语言开发笔记--(LeapMotion控制器简介)
(1)LeapMotion系统识别和追踪手,手指,以及根手指类似的工具,这个设备运行在一个极小的范围,这个范围拥有个高精度,高跟踪频率可以记录离散的点,手势,和动作. (2)LeapMotion控制器 ...
- springboot源码解析-管中窥豹系列之项目类型(二)
一.前言 Springboot源码解析是一件大工程,逐行逐句的去研究代码,会很枯燥,也不容易坚持下去. 我们不追求大而全,而是试着每次去研究一个小知识点,最终聚沙成塔,这就是我们的springboot ...
- sqlserver 清除表数据和拷贝表结构的操作
最近在做一个ERP系统需要导入数据,因此用到了sql的一些操作,在这里记录一下. 1.清除表数据: Delete from 表名称 where XXX 2.拷贝表结构,需求是新增一个和某个表数据格式一 ...
- TeamView WaitforConnectFailed错误原因
更新到最新版本并重启如下服务 检查TCP IPV4是否选中
- WPF APP 启动时增加特殊逻辑
public partial class App : Application { public App() { this.Startup += (o1, e1)=>{ string comman ...
- oracle 11.2.0.1.0 升级 11.2.0.4.0 并 patch 到11.2.0.4.7
升级步骤: (1) 备份数据库 (2) 运行patchset,升级oracle 软件 (3) 准备新的ORACLE_HOME (4) 运行dbua 或者脚本升级实例 (5) ...