理解brk和sbrk
brk和sbrk的定义
在man手册中定义了这两个函数:
#include <unistd.h>
int brk(void *addr);
void *sbrk(intptr_t increment);
手册上说brk和sbrk会改变program break的位置,program break被定义为程序data segment的结束位置。感觉这句话不是很好理解,从下面程序地址空间的分布来看,data segment后面还有bss segment,显然和手册说的不太一样。一种可能的解释就是手册中的data segment和下图中的data segment不是一个意思,手册中的data segment应该包含了下图中的data segment、bss segment和heap,所以program break指的就是下图中heap的结束地址。
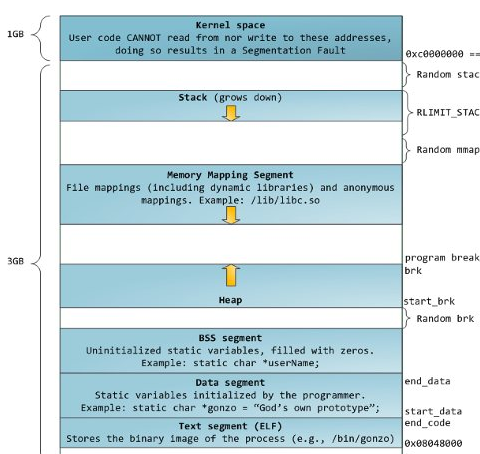
有了前面program break的概念后,我们来看下brk和sbrk的作用。brk通过传递的addr来重新设置program break,成功则返回0,否则返回-1。而sbrk用来增加heap,增加的大小通过参数increment决定,返回增加大小前的heap的program break,如果increment为0则返回program break。
从上面的图可以看出heap的起始地址并不是bss segment的结束地址,而是随机分配的,下面我们用一个程序来验证下:
#include <stdio.h>
#include <unistd.h> int bss_end; int main(void)
{
void *tret; printf("bss end: %p\n", (char *)(&bss_end) + );
tret = sbrk();
if (tret != (void *)-)
printf ("heap start: %p\n", tret);
return ;
}
运行的结果为:
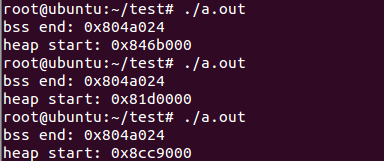
从上面运行结果可以知道bss和heap是不相邻的,并且同一个程序bss的结束地址是固定的,而heap的起始地址在每次运行的时候都会改变。你可能会说sbkr(0)返回的是heap的结束地址,怎么上面确把它当做起始地址呢?由于程序开始运行时heap的大小是为0,所以起始地址和结束地址是一样的,不信我们可以用下面的程序验证下。
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h> int bss_end; int main(void)
{
void *tret;
char *pmem; printf("bss end: %p\n", (char *)(&bss_end) + );
tret = sbrk();
if (tret != (void *)-)
printf ("heap1 start: %p\n", tret); if (brk((char *)tret - ) == -)
printf("brk error\n"); tret = sbrk();
if (tret != (void *)-)
printf ("heap2 start: %p\n", tret); pmem = (char *)malloc();
if (pmem == NULL) {
perror("malloc");
exit (EXIT_FAILURE);
}
printf ("pmem:%p\n", pmem); tret = sbrk();
if (tret != (void *)-)
printf ("heap1 end: %p\n", tret); if (brk((char *)tret - ) == -)
printf("brk error\n"); tret = sbrk();
if (tret != (void *)-)
printf ("heap2 end: %p\n", tret);
return ;
}
运行结果为:
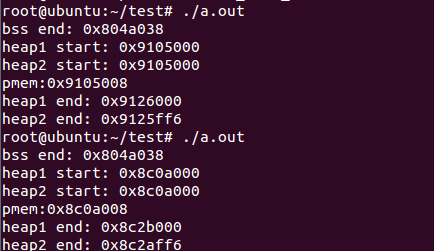
程序开始的时候打印出来heap的结束地址,并用这个地址减1来重新设置heap的结束地址,结果两次的结束地址居然是一样的,那说明这个结束地址就是heap的起始地址,再减小这个起始地址是不允许的,不过brk也不会报错。然后调用malloc获取内存,并打印出该内存的起始地址pmem,可以发现pmem与heap的起始地址相差8个字节,为什么会有8个字节没有?这8个字节应该是用来管理heap空间的(不深究)。最后再次获得heap的结束地址,并用这个地址减10来重新设置heap的结束地址,这下地址设置成功了。
堆的管理
上面的函数我们其实很少使用,大部分我们使用的是malloc和free函数来分配和释放内存。这样能够提高程序的性能,不是每次分配内存都调用brk或sbrk,而是重用前面空闲的内存空间。brk和sbrk分配的堆空间类似于缓冲池,每次malloc从缓冲池获得内存,如果缓冲池不够了,再调用brk或sbrk扩充缓冲池,直到达到缓冲池大小的上限,free则将应用程序使用的内存空间归还给缓冲池。
如果缓冲池需要扩充时,一次扩充多少呢?先运行下面的程序看看:
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h> int main(void)
{
void *tret;
char *pmem; tret = sbrk();
if (tret != (void *)-)
printf ("heap start: %p\n", tret); pmem = (char *)malloc(); //分配内存
if (pmem == NULL) {
perror("malloc");
exit (EXIT_FAILURE);
}
printf ("pmem:%p\n", pmem);
tret = sbrk();
if (tret != (void *)-)
printf ("heap size on each load: %p\n", (char *)tret - pmem);
free(pmem)
return ;
}
运行结果如下:

从结果可以看出调用malloc(64)后缓冲池大小从0变成了0x20ff8,将上面的malloc(64)改成malloc(1)结果也是一样,只要malloc分配的内存数量不超过0x20ff8,缓冲池都是默认扩充0x20ff8大小。值得注意的是如果malloc一次分配的内存超过了0x20ff8,malloc不再从堆中分配空间,而是使用mmap()这个系统调用从映射区寻找可用的内存空间。
参考
http://blog.csdn.net/sgbfblog/article/details/7772153
理解brk和sbrk的更多相关文章
- brk 和 sbrk 区别
转自:https://www.cnblogs.com/chengxuyuancc/p/3566710.html brk和sbrk的定义,在man手册中定义了这两个函数: 1 #include < ...
- Unix系统编程()brk,sbrk
在堆上分配内存 进程可以通过增加堆的大小来分配内存,所谓堆是一段长度可变的连续虚拟内存,始于进程的未初始化数据段末尾,随着内存的分配和释放而增减.通常将堆的当前内存边界称为"program ...
- Linux中brk()系统调用,sbrk(),mmap(),malloc(),calloc()的异同【转】
转自:http://blog.csdn.net/kobbee9/article/details/7397010 brk和sbrk主要的工作是实现虚拟内存到内存的映射.在GNUC中,内存分配是这样的: ...
- brk(), sbrk() 用法详解
brk() , sbrk() 的声明如下: #include <unistd.h> int brk(void *addr); void *sbrk(intptr_t increment); ...
- brk(), sbrk() 用法详解【转】
转自:http://blog.csdn.net/sgbfblog/article/details/7772153 贴上原文地址,好不容易找到了:brk(), sbrk() -- 改变数据段长度 brk ...
- 系统调用与内存管理(sbrk、brk、mmap、munmap)(转)
一.系统调用(System Call):在Linux中,4G内存可分为两部分——内核空间1G(3~4G)与用户空间3G(0~3G),我们通常写的C代码都是在对用户空间即0~3G的内存进行操作.而且,用 ...
- Linux内存分配小结--malloc、brk、mmap【转】
转自:https://blog.csdn.net/gfgdsg/article/details/42709943 http://blog.163.com/xychenbaihu@yeah/blog/s ...
- brk和mmap(转)
进程分配内存有两种方式,分别由两个系统调用完成:brk和mmap: 1.brk是将数据段的(.data)的最高地址指针_edata往高地址推 2.mmap是虚拟地址空间找一个空闲的虚拟内存 如果mal ...
- 转:如何实现一个malloc
如何实现一个malloc 转载后排版效果很差,看原文! 任何一个用过或学过C的人对malloc都不会陌生.大家都知道malloc可以分配一段连续的内存空间,并且在不再使用时可以通过free释放掉. ...
随机推荐
- 删除MSSQL中所有表的数据
CREATE PROCEDURE sp_DeleteAllDataASEXEC sp_MSForEachTable 'ALTER TABLE ? NOCHECK CONSTRAINT ALL'EXEC ...
- ZOJ1913 Euclid's Game (第一道简单的博弈题)
题目描述: Euclid's Game Time Limit: 2 Seconds Memory Limit: 65536 KB Two players, Stan and Ollie, p ...
- iOS 属性修饰符记录 --不定时更新
重新审视了一下OC在属性修饰符,特意记录一下来.以后不定时更新 > retain:只有在非ARC下才会有效,所有如果在ARC下使用了retain修饰也白搭 如以下的data属性用retain修饰 ...
- hadoop+tachyon+spark的zybo cluster集群综合配置
1.zybo cluster 架构简述: 1.1 zybo cluster 包含5块zybo 开发板组成一个集群,zybo的boot文件为digilent zybo reference design提 ...
- UITableView(一)
#import <UIKit/UIKit.h> @interface ViewController : UIViewController<UITableViewDataSource, ...
- SQL Server null知多少?
null是什么? 不知道.我是说,他的意思就是不知道(unknown). 它和true.false组成谓词的三个逻辑值,代表“未知”.与true和false相比,null最难以令人捉摸,因为它没有明确 ...
- Web3DGame之路(三)分析babylonjs
BabylonJS的例子十分详实 http://doc.babylonjs.com/tutorials Babylonjs的学习比较顺畅,开始做一些深入分析 一.语言选择 首先是js还是ts的问题 ...
- RabbitMQ Exchange & Queue Design Trade-off
In previous post, I mentioned the discussion on StackOverflow regarding designing exchanges. Usually ...
- jquery中bind()绑定多个事件
bind()绑定事件 $(selector).bind(event,data,function): 参数event为事件名称(如"click,mouseover....."),da ...
- 数据库基础,表及SQL语句
数据库基础及T-SQL语句 字符类型: int 整型 float 小数 double 小数 varchar(20) 字符串 bit 布尔型数据 datetime 日期时间类型 text 长文本 (以下 ...