[Python机器学习]鸢尾花分类 机器学习应用
1、问题简述
- 花瓣的长度和宽度以及花萼的长度和宽度,所有测量结果的单位都是厘米。
2、测试代码
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# @File : Iris.py
# @Author: 赵路仓
# @Date : 2020/2/26
# @Desc :
# @Contact : 398333404@qq.com import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
import mglearn
import pandas as pd
from sklearn.datasets import load_iris # 鸢尾花(Iris)数据集,这是机器学习和统计学中一个经典的数据集
from sklearn.model_selection import train_test_split iris_dataset = load_iris() # load_iris 返回的 iris 对象是一个 Bunch 对象,与字典非常相似,里面包含键和值
print("Key or iris_dataset:\n{}".format(iris_dataset.keys())) # 打印
print(iris_dataset['DESCR'][:193] + "\n...") # DESCR 键对应的值是数据集的简要说明。target_names 键对应的值是一个字符串数组 里面包含我们要预测的花的品种
print("Target names: {}".format(iris_dataset['target_names'])) # 三种花的名字类型
print("Feature names: {}".format(iris_dataset['feature_names'])) # 三种花的特征,花瓣的长度 宽度 及 花萼的长度 宽度
print("Type of data: {}".format(type(iris_dataset['data']))) # data 数组的每一行对应一朵花,列代表每朵花的四个测量数据
print("Shape of data: {}".format(iris_dataset['data'].shape)) # 数组中包含 150 朵不同的花的测量数据
print("First five rows of data:\n{}".format(iris_dataset['data'][:5])) # 前五朵花的数据
print("Type of target: {}".format(type(iris_dataset['target']))) # 是一个一维数组,每朵花对应其中的一个数据
print("Shape of target: {}".format(iris_dataset['target'].shape)) #
print("Target:\n{}".format(iris_dataset['target'])) # 品种转为0 1 2三个整数,代表三个种类 X_train, X_test, Y_train, Y_test = train_test_split(iris_dataset['data'], iris_dataset['target'], random_state=0)
print("X_train shape:{}".format(X_train.shape))
print("Y_train shape:{}".format(Y_train.shape))
print("X_test shape:{}".format(X_test.shape))
print("Y_test shape:{}".format(Y_test.shape)) # 利用X_train的数据创建DataFrame
# 利用iris_dataset.feature_names的字符对数据进行标记
iris_dataframe=pd.DataFrame(X_train,columns=iris_dataset.feature_names) # 横坐标 以及横坐标名称
# 利用DataFrame创建散点图矩阵,按y_trian着色
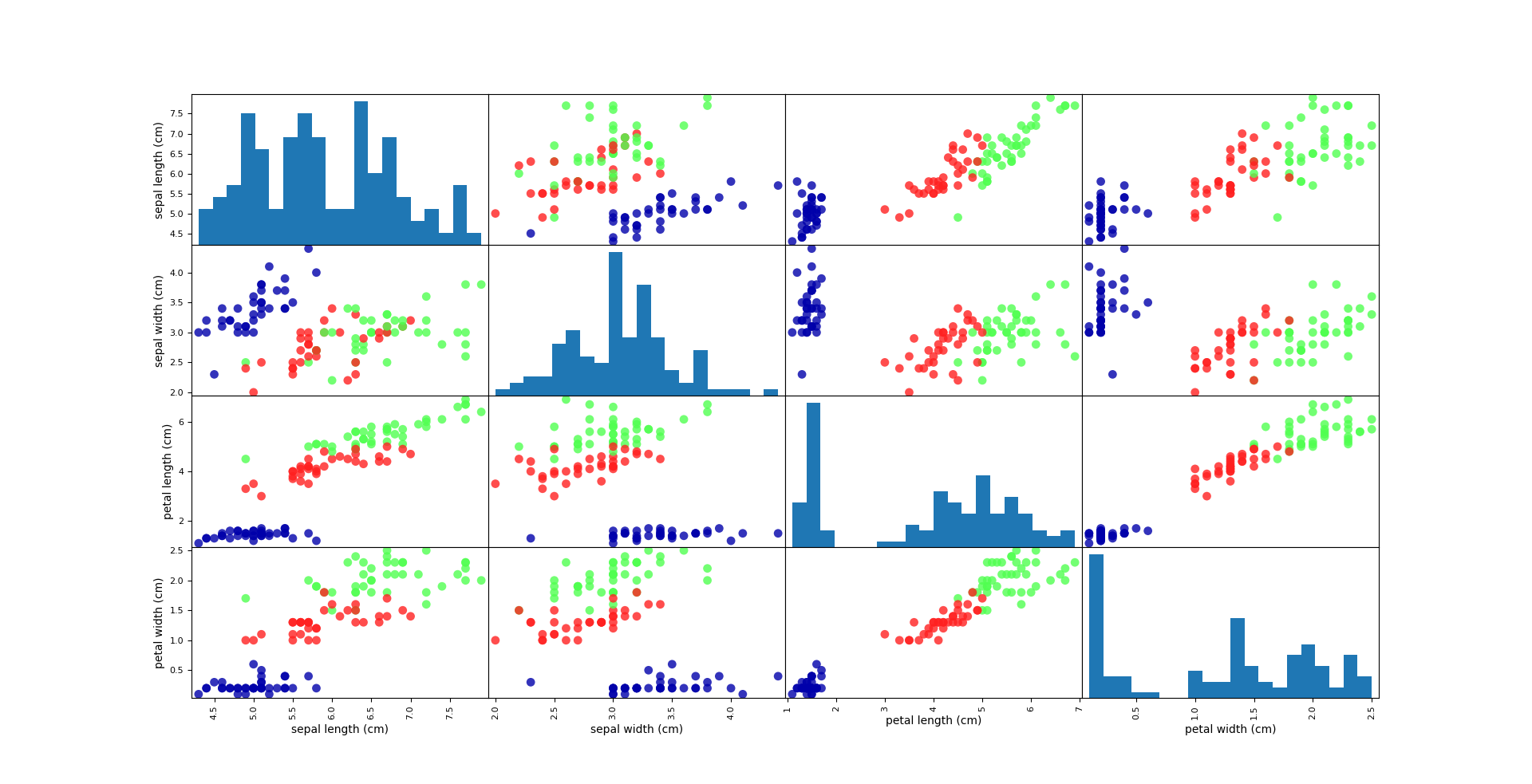
grr=pd.plotting.scatter_matrix(iris_dataframe, c=Y_train, figsize=(15, 15), marker='o',hist_kwds={'bins': 20}, s=60, alpha=.8, cmap=mglearn.cm3)
plt.show()
注:其中data数组的每一行代表一朵花,列代表每朵花的四个测量数据,一共150朵不同的花。而target是一个一维数组,每朵花代表其中的以个数据,用0、1、2三个整数代表三个不同的花品种。
3、衡量是否成功:训练数据和测试数据
首先,不能用构建模型的数据用于评估模型,因为模型是适配构建模型数据的,若用来测试匹配必定是100%。因此,要用新数据来测试模型。
X_train, X_test, Y_train, Y_test = train_test_split(iris_dataset['data'], iris_dataset['target'], random_state=0)
print("X_train shape:{}".format(X_train.shape))
print("Y_train shape:{}".format(Y_train.shape))
print("X_test shape:{}".format(X_test.shape))
print("Y_test shape:{}".format(Y_test.shape))
4、观察数据
# 利用X_train的数据创建DataFrame
# 利用iris_dataset.feature_names的字符对数据进行标记
iris_dataframe=pd.DataFrame(X_train,columns=iris_dataset.feature_names) # 横坐标 以及横坐标名称
# 利用DataFrame创建散点图矩阵,按y_trian着色
grr=pd.plotting.scatter_matrix(iris_dataframe, c=Y_train, figsize=(15, 15), marker='o',hist_kwds={'bins': 20}, s=60, alpha=.8, cmap=mglearn.cm3)
plt.show()
数据显示结果:
[Python机器学习]鸢尾花分类 机器学习应用的更多相关文章
- [Python]基于K-Nearest Neighbors[K-NN]算法的鸢尾花分类问题解决方案
看了原理,总觉得需要用具体问题实现一下机器学习算法的模型,才算学习深刻.而写此博文的目的是,网上关于K-NN解决此问题的博文很多,但大都是调用Python高级库实现,尤其不利于初级学习者本人对模型的理 ...
- Python数据预处理:机器学习、人工智能通用技术(1)
Python数据预处理:机器学习.人工智能通用技术 白宁超 2018年12月24日17:28:26 摘要:大数据技术与我们日常生活越来越紧密,要做大数据,首要解决数据问题.原始数据存在大量不完整.不 ...
- 探索 Python、机器学习和 NLTK 库 开发一个应用程序,使用 Python、NLTK 和机器学习对 RSS 提要进行分类
挑战:使用机器学习对 RSS 提要进行分类 最近,我接到一项任务,要求为客户创建一个 RSS 提要分类子系统.目标是读取几十个甚至几百个 RSS 提要,将它们的许多文章自动分类到几十个预定义的主题领域 ...
- 小姐姐带你一起学:如何用Python实现7种机器学习算法(附代码)
小姐姐带你一起学:如何用Python实现7种机器学习算法(附代码) Python 被称为是最接近 AI 的语言.最近一位名叫Anna-Lena Popkes的小姐姐在GitHub上分享了自己如何使用P ...
- 什么是机器学习的分类算法?【K-近邻算法(KNN)、交叉验证、朴素贝叶斯算法、决策树、随机森林】
1.K-近邻算法(KNN) 1.1 定义 (KNN,K-NearestNeighbor) 如果一个样本在特征空间中的k个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类 ...
- 搭建基于python +opencv+Beautifulsoup+Neurolab机器学习平台
搭建基于python +opencv+Beautifulsoup+Neurolab机器学习平台 By 子敬叔叔 最近在学习麦好的<机器学习实践指南案例应用解析第二版>,在安装学习环境的时候 ...
- Python实现鸢尾花数据集分类问题——基于skearn的NaiveBayes
Python实现鸢尾花数据集分类问题——基于skearn的NaiveBayes 代码如下: # !/usr/bin/env python # encoding: utf-8 __author__ = ...
- Python实现鸢尾花数据集分类问题——基于skearn的LogisticRegression
Python实现鸢尾花数据集分类问题——基于skearn的LogisticRegression 一. 逻辑回归 逻辑回归(Logistic Regression)是用于处理因变量为分类变量的回归问题, ...
- Python实现鸢尾花数据集分类问题——基于skearn的SVM
Python实现鸢尾花数据集分类问题——基于skearn的SVM 代码如下: # !/usr/bin/env python # encoding: utf-8 __author__ = 'Xiaoli ...
随机推荐
- ARTS Week 1
Oct 28,2019 ~ Nov 3,2019 Algorithm 本周的学习的算法是二分法.二分法可以用作查找即二分查找,也可以用作求解一个非负数的平方根等.下面主要以二分查找为例. 为了后续描述 ...
- 配置 Docker 加速器
Linux curl -sSL https://get.daocloud.io/daotools/set_mirror.sh | sh -s http://f1361db2.m.daocloud.io ...
- 5.7.20 多实例——MGR部署实战
数据库 | MySQL:5.7.20 多实例——MGR部署实战 MGR介绍 基于传统异步复制和半同步复制的缺陷——数据的一致性问题无法保证,MySQL官方在5.7.17版本正式推出组复制(MySQL ...
- PgSQL备份
SQL转储. 这里我们用到的工具是pg_dump和pg_dumpall. 这种方式可以在数据库正在使用的时候进行完整一致的备份,并不阻塞其它用户对数据库的访问.它会产生一个脚本文件,里面包含备份开始时 ...
- Mysql 升级重装后连接出错 Table \'performance_schema.session_variables\' doesn\'t exist
升级重装后 连接出错 报这个错误 Table 'performance_schema.session_variables' doesn't exist 使用这个命令即可 [root@localh ...
- ORB-SLAM2 论文&代码学习 —— 单目初始化
转载请注明出处,谢谢 原创作者:Mingrui 原创链接:https://www.cnblogs.com/MingruiYu/p/12358458.html 本文要点: ORB-SLAM2 单目初始化 ...
- 3.【Spring Cloud Alibaba】声明式HTTP客户端-Feign
使用Feign实现远程HTTP调用 什么是Feign Feign是Netflix开源的声明式HTTP客户端 GitHub地址:https://github.com/openfeign/feign 实现 ...
- C语言结构体定义位域,从bit0开始,依次到最高bit位
位域是指信息在存储时,并不需要占用一个完整的字节, 而只需占几个或一个二进制位.例如在存放一个开关量时,只有0和1 两种状态, 用一位二进位即可.为了节省存储空间,并使处理简便,C语言又提供了一种数据 ...
- 解决 webpack-dev-server 不能使用 IP 访问
webpack 是众所周知很好用的打包工具,在开发 vue 项目时,vue-cli 就集成了 webpack.我们启一个服务:npm run dev然后在浏览器可是使用 http://localhos ...
- Arm开发板+Qt学习之路-multiple definition of
问题描述:在一个头文件a.h中定义一些变量x,在其他.c文件中(b.c,c.c)要用到.用一般的全局变量的方法,编译时总是提示error:multiple definition of x 问题分析:o ...